数据库Join原理
基本的Join算法
主要有三种基本的Join算法,各种数据库的Join只是对这三种Join的优化和补充:
- Nested Loop Join (嵌套循环Join)
- Hash Join
- Sort Merge Join
Nested Loop Join
最简单的关联方式,嵌套循环
假设有表R、表S,那么 R Left join S的本质就是双层for循环,如下伪代码:
1 | for (r : R) { |
所以此种方式,我们需要:读取R表 + R的行数*S表
Hash Join
在Nested Loop Join的基础上,可以将较小的一个表存入hash,加快遍历速度
1 | hashTable = buildHashTable(S); |
所以此种方式,我们需要:读取R表 + S表
Sort Merge Join
将两张表排序,然后各有一个指针分别开始从头遍历,遇到相同join key就输出,适用于具有相同排序键的两个表
1 | // 从小到大排序 |
所以此种方式,我们需要:读取R表 + 排序R表 + 读取S表 + 排序S表
Mysql中的Join
驱动表与被驱动表
在介绍Mysql的Join之前,需要先了解驱动表和被驱动表两个概念
- 驱动表(Driving Table): 驱动表是在连接操作中先被访问的表。它是整个查询执行的起点,驱动表的每一行都会尝试与被驱动表的相应行进行匹配。在嵌套循环连接(Nested Loop Join)中,驱动表的每一行都会作为外层循环的一部分,执行内层循环以与被驱动表进行匹配。
- 被驱动表(Driven Table): 被驱动表是在连接操作中后被访问的表。在嵌套循环连接中,被驱动表的每一行都会被用于与驱动表进行匹配。
可以说驱动表是真正执行时意义上的“外表”,被驱动表是真正意义上的“内表”
到底哪一个表是驱动表呢?参考文章:https://blog.csdn.net/u010134642/article/details/134045154
在没有where条件时,驱动表的选择逻辑如下:
- Inner Join:优化器会先将小表作为驱动表,大表作为被驱动表
- Left join:左表是驱动表
- Right join:右表是驱动表
在有where条件时,驱动表的选择逻辑如下:
- Inner Join:与之前相同,优化器会先将小表作为驱动表,大表作为被驱动表
- Left join:
- 没有where条件,左表是驱动表;
- 有where条件:
- where字段有索引:使用where字段所在的表
- where字段没有索引:左表
- Right join:同理left join
对于Nested Loop Join来说,驱动表的每一行都要去遍历一遍被驱动表,因此驱动表尽量要小,会减少计算量
而且要给被驱动表建立索引,驱动表的索引是不会使用的
Index Nested Loop Join
如果关联键是被驱动表的索引键,内层遍历会优化为通过索引查询
将驱动表的每一行与被驱动表进行匹配。
这样做的好处是什么呢?
当内层表是索引查询时,由于B+树最多有3~4层,因此查询的I/O消耗其实是比较稳定的
所以一般会选择小表作为驱动表(载入内存占用小),然后大表作为被驱动表(查询消耗稳定)
Block Nested Loop Join
当关联键不是被驱动表的索引,且版本在V8.0.20之前的非等值查询时,会使用这种方式:
与基本的Nested Loop Join的区别是,引入了一个Join buffer,与Index Nested Loop Join的区别是,提出了一个Block的概念:
所谓Block就是将驱动表划分为各个“块”,然后每次匹配一个Block,这样可以减少IO次数(划分块后确实非常适合于非等值查询)
Hash Join
关于hash join参考:https://cloud.tencent.com/developer/article/1684046
v8.0.20开始全面使用HashJoin取代Block Nested Loop Join
Mysql中的HashJoin的具体实现由两部分组成:
- 建表 build:遍历表,使用hash函数计算连接键构建哈希链表
- 探测 probe:遍历另一个,根据连接键计算hash值找到对应的桶
注意:hash join 一般会选择比较小的表作hash表,不一定会选择驱动表
- Inner Join:选择小表建立哈希表
- Left join:选择右表建立哈希表
- Right join:选择左表建立哈希表
因此hash join中LEFT JOIN时,尽量使用大表join小表
Mysql中Join的选择策略
- 当关联键是索引:
- Index Nested Loop Join
- 当关联键不是索引:
- V8.0.20之前:
- 等值查询:Hash Join
- 非等值查询:Block Nested Loop Join
- V8.0.20之后:Hash Join
- V8.0.20之前:
Hive中的Join
见文档
关于关系型数据库和非关系型数据库的Join原理有所区别:
- 关系型数据库一般是为了获得某一个数据,比如今日最受欢迎的网站是哪一个(依赖于索引)
- 非关系型数据一般是为了数据分析,需要获得某一组数据的结果,比如今日最受欢迎的网站分别属于哪些年龄段的人(全表扫描)
Spark中的Join
数据库有三种join:
- Nested Loop join:最基本的JOIN策略(它会循环遍历第一个表的每一行,然后对于每一行,再循环遍历第二个表的所有行,以查找匹配的行),嵌套循环join(匹配n*n次)
- Sort merge join:排序后匹配join,开销为O(nlogn)+O(n),跟排序算法有关
- 在Mysql中,SMJ的排序算法是归并排序(因为Mysql一般都是单机运行,且数据库系统一般关注稳定性,因此归并算法这种稳定算法比较适合,稳定指相同值的元素在排序前后顺序一致)
- 在Spark中,SMJ的排序算法是快速排序(Spark是分布式计算引擎,因此快排这种原地排序算法更好,而且快排的速度很快)
- Hash join:按hash分区后,每个分区内双层循环匹配,拆分分区后每个分区内匹配次数较少(3030 vs 1010 + 1010 + 1010)
- 在哈希连接中,系统会为连接条件中的每个表构建哈希表,然后将两个表的哈希表进行匹配,以找到匹配的行
大数据机器间的数据交互形式:
- broadcast:即广播,driver端发送小表到每个executor上,此过程主要开销是网络io,以及executor的内存占用
- shuffle:洗牌,会经历按Hash(hash值mod分区数,得到一个值并发往相应分区)或Range(采样后按照采样分布重分区,尽可能让数据均匀)拆分数据得到分片,对应分片发往对应下游机器再进行处理的过程,此过程中重点是让数据分布均匀,否则会产生数据倾斜(单个节点数据量过大,处理时间过长,出现长尾效应)
PS:shuffle是个比较重的动作:涉及到重分区以及大量的网络io开销,若数据量过大不够在内存中完全处理,还会落盘,涉及到磁盘io开销
结合起来就是spark的五种join:
- 适用等值join:broadcast hash join、shuffle hash join 、shuffle sortmerge join
- 适用于非等值join:cartesian product join、broadcast nested loop join
- 只是先机器之间怎么交互数据,再本地怎么匹配的问题
Broadcast hash join
也叫Map Join
对于场景:大表Join小表,且是等值join的情况
我们可以将小表广播,这样可以避免shuffle
原理:driver 先把广播表(小的那一个表) collect, 然后分发到各 exectuor。exctuor 里面进行 hash join,这样规避了 shuffle
(其实就是每一个executor除了大表的数据,还要存储小表的数据)
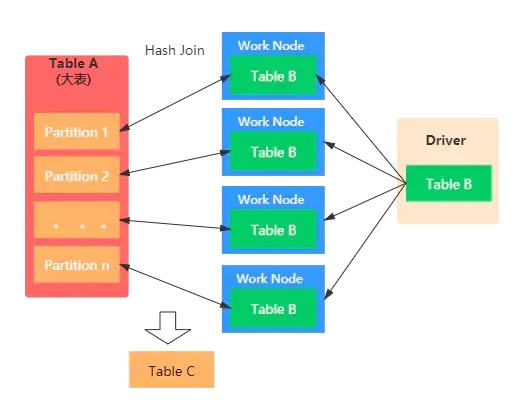
使用这种方法的要求是:
- 对driver、executor需要有足够的内存,广播的表要尽量小(表不能超过8G)
- 只支持等值连接
- 不支持 full outer join
如何开启广播?
方法一:使用hint(提示)【推荐】
1 | SELECT /*+ BROADCAST(r) */ * FROM records r JOIN src s ON r.key = s.key |
方法二:设置参数,当某表小于此阈值,就会自动更改执行计划,spark会进行统计信息(但在统计信息出来前,不会进行广播,因此还是方法一比较好)
1 | spark.sql.autoBroadcastJoinThreshold = 10485760 --(默认10M,-1代表关闭) |
shuffle hash join
原理:没有避免两表的shuffle read,但是选择对小表构建hashmap,join时从hashmap读取数据
比如我们按照a.sex=b.sex进行检索,他会进行如下的过程:
- 在两端按照sex这个字段进行重分区,没有避免shuffle,原因是需要把相同sex的数据传输到同一个分区
- 然后对较小的表建立一个hashmap,然后使用大表的分区数据去映射这个hashmap获取数据
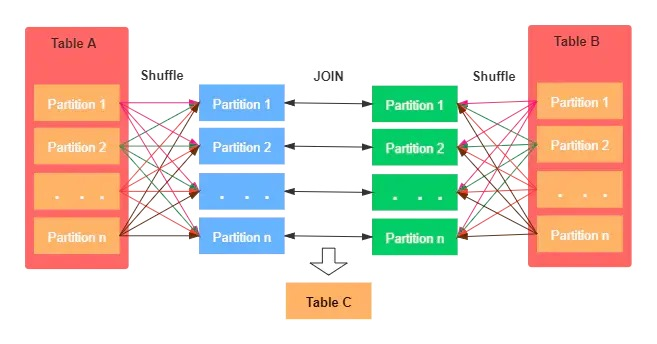
使用这种方法的要求是:
- 构建 hashmap 也需要消耗内存,因此如果较小的表也很大,有可能会发生oom
- 构建 hashmap 的耗时与 sort 耗时比较
- 仅支持等值连接
- 不支持 full outer join
如何开启:
方法一:提示
1 | SELECT /*+ SHUFFLE_HASH(s) */ * FROM records r JOIN src s ON r.key = s.key |
方法二:将默认使用Sort Merge Join关闭
1 | spark.sql.join.prefersortmergeJoin = false -- 默认为true |
方法三:AQE,当每个分区大小小于下面的阈值时,AQE 自动更改执行计划为 SHJ,此时不管 spark.sql.join.prefersortmergeJoin 的值
1 | -- spark 3.2.0 后: |
Sort Merge Join
Spark默认的join方式:一般在两张大表进行JOIN时,使用该方式。
Sort Merge Join可以减少集群中的数据传输,该方式不会先加载所有数据的到内存,然后进行hashjoin,但是在JOIN之前需要对join key进行排序。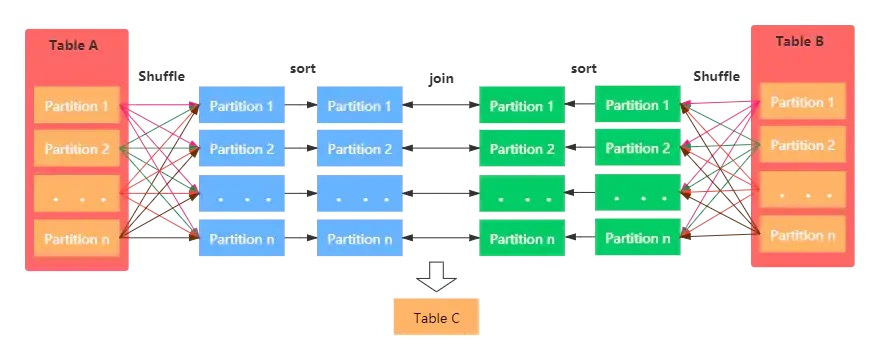
Sort Merge Join主要包括三个阶段:
- Shuffle Phase:两张大表根据Join key进行Shuffle重分区
- Sort Phase:每个分区内的数据进行排序
- Merge Phase:对来自不同表的排序好的分区数据进行JOIN,通过遍历元素,连接具有相同Join key值的行来合并数据集
要求:
- 只支持等值链接
- 支持所有的join
- Join的key需要排序
- 默认的join方式
Cartesian Join
如果 Spark 中两张参与 Join 的表没指定join key(ON 条件)那么会产生 Cartesian product join,这个 Join 得到的结果其实就是两张行数的乘积。
Broadcast Nested Loop Join
该方式是在没有合适的JOIN机制可供选择时,最终会选择该种join策略。
优先级为:Broadcast Hash Join > Sort Merge Join > Shuffle Hash Join > cartesian Join > Broadcast Nested Loop Join
在Cartesian 与Broadcast Nested Loop Join之间,如果是内连接,或者非等值连接,则优先选择Broadcast Nested Loop策略,当是非等值连接并且一张表可以被广播时,会选择Cartesian Join。
- 支持等值和非等值连接
- 支持所有的JOIN类型,主要优化点如下:
- 当右外连接时要广播左表
- 当左外连接时要广播右表
- 当内连接时,要广播左右两张表