Caffeine与缓存算法
LRU及其变体
LRU、LRU-K
LRU 最近最少使用算法,最简单可以使用一个hashmap+linkedlist实现,越靠近头表示刚被访问,越靠近尾部表示越久时间没有被访问。
所谓LRU-K,就是将最近使用过1次的普通LRU算法扩展到K次。
- 优点:对于热点数据,LRU的表现很好
- 缺点:对于偶发性的、周期性的批量操作,LRU会有比较明显的缓存污染情况,会缓存很多长尾数据。
SLRU
Segment LRU:将LRU分为保护段(protected segment)和试用段(probationary segment)
- 试用段:存放只访问1次的数据
- 保护段:存放访问至少2次的数据
试用段只会接受新的数据,用这个结构来增加对偶发性、周期性批量操作的抗性。
与ARC算法十分相似,可以认为是静态的ARC算法
LFU及其变体
LFU
最近最少频次,需要维护访问的次数,通常会用一个最小堆来实现。
相较于LRU:
- 优点:LFU的效率更好,能避免周期性或是偶发性的命中率下降的问题。
- 缺点:
- 维护“频率”的计数需要大量内存
- 如果数据的访问模式改变,那么LFU需要重新进行计数来适应新的访问模式。
- 存在缓存污染问题,比如高频数据不再高频(比如上个礼拜的热点,现在已经不是了,但是计数居高不下)
LFU-Aging
为了解决高频数据不再高频的问题(即第三个缺点),引入了访问的时效性(即上次距上一次访问间隔的时长),以及衰减策略,但衰减策略的调节也是一个问题。
Redis中就有LFU-Aging算法的思想,他将原本的LRU字段拆为两个,高位表示数据的访问时间戳,低位表示数据的访问次数,在淘汰时,先比较访问次数(低位),再比较时间戳(高位)
LFU-Aging 主要是为了解决第三个问题:防止缓存污染
Window-LFU
所谓的Window,就是不再维护所有数据的频率计数,而是维护一部分的,维护的这一部分就成为窗口。
窗口可以是固定的也可以是滑动的,在滑动窗口满后,再添加新的元素,会淘汰滑动窗口内频次最小的元素。
Window-LFU的主要目的是解决LFU的第一个问题,即减少维护计数所需要的资源
ARC算法
Adaptative Replacement Cache 自适应替代缓存一种结合了LRU、LFU思想的算法。
实现ARC算法需要两个LRU Cache:
- L1 Cache:存储只访问过1次的
- L2 Cache:存储至少访问过2次的
需要维护两种信息:
- T1子列表:最近访问
- T2子列表:最高频访问
还需要记录被淘汰的数据信息:
B1:记录T1子列表淘汰的数据,即LRU淘汰的数据
B2:记录T2子列表淘汰的数据,即LFU的数据
核心思想是:
当L1、L2两个cache存满后,如果T1的数据被淘汰,则记录数据到B1;同理L2数据被淘汰,记录数据到B2。
此后:
- 如果B1的数据被访问,则会扩展T1的长度,此时表现更像LRU
- 如果B2的数据被访问,则会扩展T2的长度,此时表现更像LFU
Tiny-LFU
在介绍Tiny-LFU缓存算法之前,需要先了解两个概念:
Bloom Filter
布隆过滤器用来判断元素是否存在,其本质是一个有多个Hash函数的bitmap,在存储一个元素时:
- 使用 N 个Hash函数分别计算这个数据的哈希值,得到 N 个哈希值
- 将哈希值对 bit 数组的长度取模,得到每个哈希值在数组中的对应位置
- 将对应的 bit 位置为 1
这样布隆过滤器就可以保证绝对的判断不存在,相对的判断存在。
在判断是否存在时可能会有误差。bitmap越大,哈希函数越多,错误率会越低。
CM-Sketch
CM-Sketch用来求元素在集合中数量的布隆过滤器,本质是一个有多个Hash函数的二维数组

与bloom过滤器将相应位置置1不同,CM-Sketch会将对应位置的元素+1:
- 使用 N 个Hash函数分别计算这个数据的哈希值,得到 N 个哈希值
- 每一个hash值会映射到二维数组的一个位置
- 将对应位置+1
这样在判断一个元素在集合中的数量的时候,求出不同的hash值,并取最小值就是该元素在集合中的数量Min{hash1 , hash2, hash3}。
当然和布隆过滤器一样,也存在一定的误差。
Tiny-LFU
LFU算法需要计算“频率”,这是LFU算法淘汰元素的策略。
Tiny-LFU算法使用CM-Sketch来判断元素的访问次数(访问频次其实并不需要计算的很精确,使用CM-Sketch效率很高)
简而言之:Tiny-LFU = CM-Sketch + 衰减策略
Sketch可以为了防止长尾数据带来的缓存污染问题,更进一步的是,Tiny-LFU还使用了布隆过滤器(称为Doorkeeper 门卫)
核心思想是:使用Doorkeeper判断元素是否存在
- 如果不存在插入到Doorkeeper
- 如果存在插入到Sketch,且返回Sketch存储的计数再+1
Caffeine的W-TinyLFU
TinyLFU对一些突如其来的高频请求不够友好,Caffeine结合了Window-LFU、SLRU(ARC)、TinyLFU的思想,实现了W-TinyLFU
结构如下:
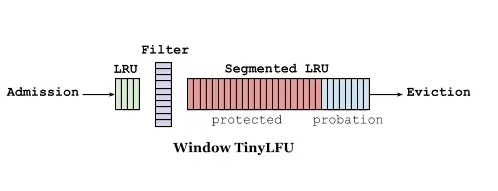
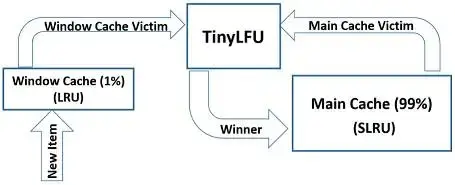
开始访问后,可以直接打到一个LRU上(Window Cache),在WindowCache被淘汰,才会进入一个Filter(TinyLFU,即Doorkeeper+Sketch),才有机会打到SLRU上(Main Cache)
Caffeine是Java著名的本地缓存工具,Caffeine内部的增长逻辑如下:
1 | public void increment( E e) { |
与其他统计频次的LFU算法一样,在运行一段时间后需要给LFU的频次“降温”(频次衰减)
1 | void reset() { |
相关链接
- 很好的博文,算是论文的翻译:https://www.qin.news/tinylfu/
- caffeine代码仓库:https://github.com/ben-manes/caffeine