VM-fault tolerance
VM-fault tolerance
The Design of a Practical System fir Fault-Tolerant Virtual Machine
Abstract
文章表明实现了一个容灾虚拟机,原理是通过备份到另外的服务器。
Introduction
一个常用的实现容灾服务器的方法:primary/backup主备份,即时刻准备一个备份服务器去接替宕机的主服务器
要实现这个方法,要做的就是要保持主从同步,即备份服务器的状态应该和主服务器一致,这样才能做到对client透明。
为了保证主从同步有两种办法:
第一种:不断的传输primary的所有更改状态。(这种方法需要传送CPU、内存、IO设备等等信息,这些信息可能量会比较大,如果带宽不足,可能会出现延迟)(内存的改变信息会很多很多)
另外一个办法:设计了一个状态机statemachine方法(注意,状态机的意思是一个数学模型,或者说是一个状态变化图)
所设计的状态机:将服务器建模为确定性的状态机 deterministic statement,即保证主从能以相同的初始状态启动,并且接收相同顺序的输入请求
为了保证协调,需要付出一定的性能代价,但是状态机方法传送的数据量会远远少于第一种方法的数据量
实现物理机之间的同步比较困难,但是让运行在物理机上的虚拟机实现同步是较为简单的
(不同的物理机之间处理器的频率不同,导致其状态很有可能不一致,但是虚拟机不一样)
但是虚拟机也有可能不确定的操作,比如读取时钟或是发送中断,因此虚拟机也需要传输同步信息
hypervisor:又称为虚拟机监视器 VMM virtual machine monitor是用来建立和执行虚拟机的程序,可以观测到虚拟机的数据
hypervisor可以捕获虚拟机必要的状态信息,然后在备份服务器上重播 replay,即可实现主从同步
by the way:从最原始的物理机,在他之上抽象出一层虚拟机,在虚拟机上又抽象出Docker,在之后出现K8s,再再之后出现云原生,那么之后会是什么呢?
状态机方法的优势:
- 实现了对程序的容灾,而与硬件解耦。
- 传输的数据量小,适合低带宽运行
主备份然后从重播的技术也叫作deterministic replay确定性回放,本文介绍方法除此之外还补充了一些功能。
目前只支持单核操作系统(不支持并发,并发操作的不确定性因素太多)
Basic FT Design
综述一下:
容灾的基本设计如图所示,PrimaryVM是我们需要去提供容灾服务的虚拟机,BackupVM是执行在另外的物理机上的虚拟机,他尽量和primary保持同步,但是还会有一些lag
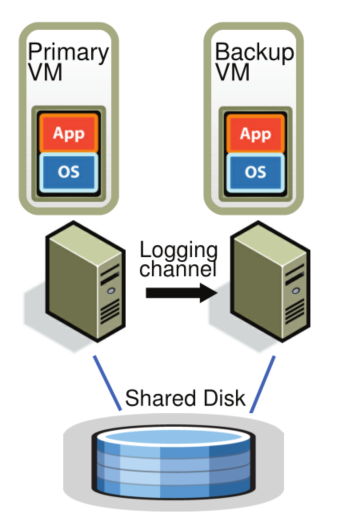
可以看到他们共享了同一个输入设备(这代表两个虚拟机会获取相同的输入和输出)这是最原始的设计,之后会探讨非共享磁盘的设计(这种共享相同设备的设计称为 virtual lockstep虚拟机锁定状态)
网络中只会暴露primary,因此输入只会进入Primary,从会通过Logging chennel保持与primary的同步,之后从虚拟机的输出会被丢弃,只有primary的输出会被返回给请求者
在相关服务器之间会有心跳连接,而且会监控logging channel的流量情况。
Deterministic Replay Implementation
如果能保证主从能以相同的初始状态启动,并且接收相同顺序的输入请求,那么他们就会有相同的输出
两种非确定性:他们可能会导致主从的状态不一致
- 非确定性事件:如虚拟机中断
- 非确定性操作:如读取时钟周期数,这取决于CPU的时钟周期
非确定事件与操作代表我们需要做三种事情:
- 确保捕获输入和所有的非确定,来保证虚拟机正确的执行
- 正确的将输入和不确定性应用到backup vm
- 不让性能变差
实现上述三点的关键在于记录日志 logging,确定性重播把虚拟机收到的输入和所有可能的非确定都记录在日志文件中,重播时一行一行执行此日志文件即可。
FT Protocol
如本节开始的configuration图所示,确定性重播会记录日志,但是不是将日志全部写入磁盘内,而是通过logging channel实时让backup VM去执行
为此,我们必须在logging channel规定一个协议以确保我们可以实现容灾。
输出要求Output Requirement:如果backup接替了primary(这个过程称为failover),必须保证backup接着之前primary的输出继续执行
(即primary对外已有的输出,backup必须能知悉并且恢复到这一点)
(协议规定的很好理解,只要保证backup上任后状态和之前primary一致,就不会让外部感受到发生了failover)
因此我们需要能保证:延迟到backup已经接收到产生在output操作之前的所有log并且重播到primary当时的状态
注意:接收到在输出操作之前的所有log,如果backup在此之前就进行了重播,那么可能会和primary的状态不一致
(因为不到最后一刻,永远不知道是否发生了变化,比如在output的前一刻,发生了中断,但是你已经执行了重播,此时就不能恢复到与原本master一样的状态,你的backup此后的输出可能会和之前的primary的输出有矛盾)
最简单的实现上述要求的方法就是:对每一个输出操作都加一个特殊的日志条目special log entries
即:要执行output时,不要让primary对外输出,直到backup接收到了这个output之前的所有log,才对外输出
注意:我们只是延迟了对外输出的一步,并不影响其他操作的正常执行
什么时候进行对外输出?异步机制在对应内容完成后会通知我们
如下图这个例子:
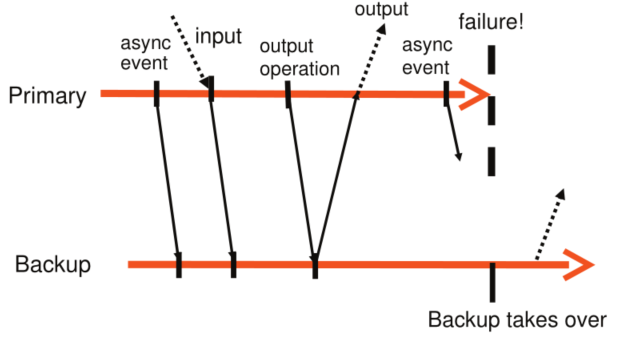
- 异步事件->正常同步
- 输入数据->正常同步
- 输出操作发生->正常同步->收到回执->对外输出
- 异步事件->primary宕机->backup接管
第3点就是我们所说的,延迟输出直到backup接收到了log
Detecting and Responding to Failure
宕机可能有三种情况:
- 如果其他VM宕机,primary和backup需要感知到其掉线
- 如果backup宕机,primary将不会再传数据到log channel,然后正常运行
- 如果primary宕机,就是上一节的过程
在backup替代了primary后,他就升级成了primary,此时他还需要做一些操作:比如广播自己的mac地址给其他vm、再比如重新发布一些磁盘io
检测primary或backup宕机的方法:
- 通过UDP实现的heartbeat
- 通过检测日志流量,包括两部分
- primary发给backup的log entries
- backup回复的确认信息acknowledge
这些检测方法可能会引起大脑分裂问题a split-brain problem:
即,当我们丢失了heartbeat时,有可能是出现了宕机,也有可能是网络出现了拥塞
如何解决这个问题?我们前面说过primary和backup之间共享磁盘 shared storage
为了确保只有一个“primary”,当backup想要上位的时候(或者说要发生failover或是go live时),我们可以在共享磁盘上做原子的测试设置操作 atomic test-and-set:
- 如果操作成功:说明可以go live
- 如果操作失败:说明已经有一个启动了,当前这个会停止且“自杀”
Practical Implementation of FT
Starting and Restarting FT VMs
为了保证primary和backup以相同状态启动,我们需要考虑两个问题:如何启动backup、选择什么样的服务器去运行
如何启动备份:
VMware之前的处理是将原server迁移到远端服务器,中间会暂停一段时间
修改后的版本可以在运行的同时,克隆到远端,中间不会有暂停服务的时间
选择什么样的服务器:
- FT-VM的集群使用共享存储,任意一个server都可以
FT-VM有一个集群,当进行了一次fallover后,如果缺失了backup,primary会通知集群给出一个backup
集群服务会选择最佳的那个server作为backup
Managing the Logging Channel
1、这一节更详细的描述了主从日志的运行模式:
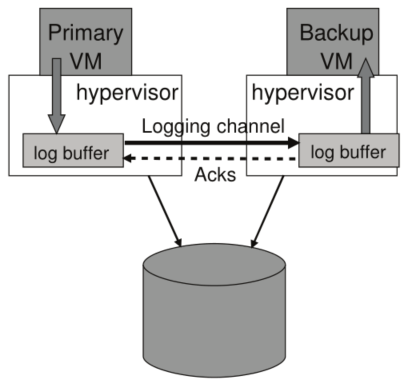
首先,Hypervisors维护了一个存储日志条目的缓冲区;primary向里面写,backup往外读;
如图所示,primary的hypervisor的buffer一有数据就会flush到channel内,而backup的buffer会立即读取。
当backup从网络读取到本地的缓存后,就会给primary发送一条确认消息Acks
(在宕机后,就依赖这个确认消息,决定什么时候go live)
2、可能引起服务暂停的几个原因:
- 当primary的日志缓冲区填满的时候,其会停止服务
因此我们尽量要保证primary的日志会被快速读取(一般情况下,backup进行重放和记录的速度一致,除非backup当前非常繁忙)
- 有时候不希望延迟太大,因为如果发生意外,需要重放,重放的时间基本与这个延迟时间一致,时间太长容易造成服务停止
在每次primary与backup的交流信息内(sending与acknowledging),都会携带他们之间的lag
这个值通常为100ms,如果大于1s,hypervisor就会逐渐限制primary vm的cpu频率(注意我们是虚拟机,所以可以很轻松的做到这一点);相反如果延迟太小,就会调大cpu频率
(Operation on FT VMs、Implementation Issues for Disk IOs、Implementation Issues for Network IO三节感觉没有什么读的价值,忽略)