GFS
Google File System
Abstract
GFS:一个适用于大型分布式数据密集型应用
运行在低配置的机器上就可以获得容灾 fault tolerance和对大量客户端的高聚合 aggregate
Introduction
分布式文件系统的目标除了:性能、可扩展性、可靠性、可用性之外,还从应用负载和技术环境驱动,去考虑新的观点:
- 组件故障是常态而不是例外:因此还需要持续监控constant monitoring、错误检测 error detection、容灾 fault tolerance、自动恢复automatic recovery
- 与传统相比文件会更大:几到几十G很常见,因此需要重新设计预计值和参数(比如IO操作块的大小)
- 大多数文件都是append而不是overwrite:要更考虑文件的append性能(随机写实际上是不存在的)
- 设计时从APP和FS两方面来考虑,简化复杂度:比如放宽一致性模型,比如引入原子附加操作
Design Overview
Assumption
设计在一定前提下实现:
- 大部分机器廉价,而且经常损坏
- 存储的文件中等,大概在几百万个100M的文件左右
- 读取:由大部分顺序读和小部分随机读组成
- 写入:大部分的顺序写
- 对多用户的并发append操作有良好的设计(并发处理方式:生产者消费者队列)
- 要高持续的带宽而不是低延迟
Interface
实现的功能:基本操作create delete open close read write,额外的设计 snapshot与record append:
snapshot:低成本的创建一个文件或是目录树的copyrecord append:保证用户可以并发对文件进行添加操作
Architecture
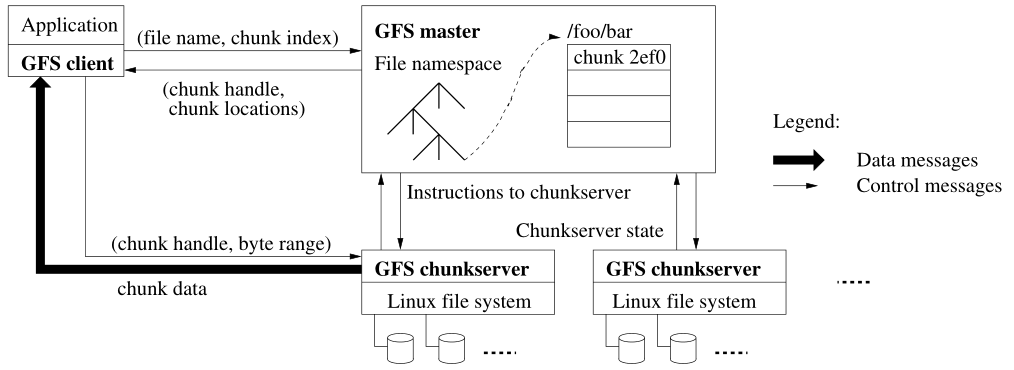
1、系统由一个Master与多个chunkserver组成,并且被多个client访问
chunkserver的作用:
- 文件被分为固定大小的块chunk(在chunk创建的时候,Master会给其一个64bit唯一标识符chunk handle)
- chunkserver负责存储这些块,而且同一份文件会在多台chunkserver上有多个备份(默认有三个备份)
Master的作用:
- 维护元信息 metadata:存储命名空间、访问控制信息、文件与chunk的映射、当前所在的chunk。
- 控制系统活动:chunk lease management、孤立chunk的垃圾回收、chunk迁移
- 周期性的联系chunkserver(心跳机制,发送HeartBeat信息)
Client作用:
- 提供给APP响应的API,最为APP的代理,请求Master和Chunkserver
- 与Master交互:请求元数据
- 与Chunkserver交互:请求真正的数据
Client与Chunkserver都不会缓存数据,但Client会缓存元数据
为什么不缓存?
client为了尽可能的避免缓存一致性cache coherence issues问题,简化系统复杂度,而且大多数app的文件很大,导致无法缓存
chunkserver本地存储了文件,而且linux系统已经将数据缓存在内存中,chunkserver本身不需要额外操作
Single Master
单个Master去存放元信息,减少了很多复杂设计。
客户机不会直接与Master数据通信,而是询问对应chunkserver的位置(并缓存这个信息一段时间,失效后再来与Master通信)之后直接与chunkserver数据交流
1、client将用户想要的filename和byte index利用固定的chunksize翻译成文件内的chunk index
2、client将filename, chunk index,Master就会返回chunkhandle, chunk locations(返回的chunk的handle以及多个文件副本的位置)client会将Master传来的信息用文件名+索引作为key缓存
3、client请求对应的chunkserver上的chunk块,chunkserver会将数据返回(通常这个请求会一次请求多个chunk,而且也可以携带master的请求)(为了尽量减少Master的交互,避免单独的Master称为瓶颈)
之后,client之后请求相同的块无需再与Master交互,直到cache过期或是文件被重新打开
Chunk Size
选定64MB(以前的标准)作为chunk的大小
每一个chunk都是linux的一个普通的文件,而且使用lazy space allocation惰性的空间释放避免内部碎片而浪费空间
惰性空间释放:
比如一个文件5MB,我们会先释放5MB空间给这个文件,如果有需要再去扩展为64MB,而不是一开始就给64MB
设置64MB(略大于文件系统block的块),有以下优点:
- 可以减少与Master的交互次数(只需要一次初始化的与Master的交互,就可以多次read和write)
- 由于块较大,因此一个块上的文件会更多,client可能多次操作都在同一个块上,因此可以延长一次TCP交互的时间,从而减少网络开销
- 减少了Master上元数据的存储开销,使元数据可以在内存中放得下
缺陷:
- 即使使用了惰性空间分配,依然会存在内部碎片的问题(比如一个文件由一个chunk组成,可能还会存在内部碎片)
- 可能会出现hot spots(很多client都会访问的热点chunk),这种情况实际上很少,但是为了避免这个问题:
- 给热点数据chunk更高的备份因子
- 如果想长期解决,可以允许客户端从其他客户端读取数据
Metadata
Master存储三种类型的数据在内存:
- file和chunk的命名空间
- file到chunks的映射
- chunk副本的位置(不会持久化存储)
前两个会进行持久化存储(通过存储操作日志operation log在Master的disk上,并且会在远端的机器上备份)第三个不会持久化存储,而是在Master启动时询问所有chunkserver,或是集群中新增加chunkserver时加载到内存
需要注意几个问题:
1、In-Memory Data Structure
元数据存储在内存,并且会定期扫描(为了实现GC、负载均衡等功能)
每一个chunk需要存储一个64b的handle,而且命名空间使用前缀压缩,尽可能的缩减大小
而且给Master添加内存条大小成本也不是很大
关于前缀压缩:在mysql中的MyISAM引擎,索引块中的第一个值是“perform“,第二个值是”performance“,那么第二个值的前缀压缩后存储的是类似”7,ance“这样的形式
2、chunk location
这类信息不会持久化(为了使系统更加简单,避免考虑添加和移除chunkserver对文件的同步),而是在Master启动时轮询polls所有的chunkserver,之后通过心跳信息更新
3、Operation Log
是GFS的核心文件
- 保留了元数据历史改动的日志文件,便于文件恢复
系统恢复只需要重新执行这个文件的操作即可,因此需要保证这个文件尽量的小:在日志超过某个大小后,都会重新设置检查点 checkpoint
检查点checkpoint:是压缩的B树格式,可以直接映射到内存中用于命名空间的查找,而无需额外的解析
切换到新的检查点时,开启一个额外的线程
- 定义并发操作的逻辑时间线(file、chunk以及他们的version全靠此文件决定)
必须保证此文件的强一致性,否则可能会丢失用户的操作:因此除了在多个机器上有此日志文件的备份外,只有当本地和远端都将record刷新到磁盘后,才会响应用户的操作(刷新和复制都会批量操作,尽可能的减少对系统吞吐量的影响)
Consistency Model
GFS实现了弱一致性,来保证分布式系统足够简单
GFS通过以下设计来解决并发问题:
1、文件名称空间file namespace的改变
关于文件名称空间(file namespace mutations, 比如文件的创建)的改变只会被Master操作(并且operation log记录了关于这类操作的总体顺序)
关于文件的内容(file region)改变,它的状态取决于下表:影响的因素有,操作是否成功、操作是否有并发
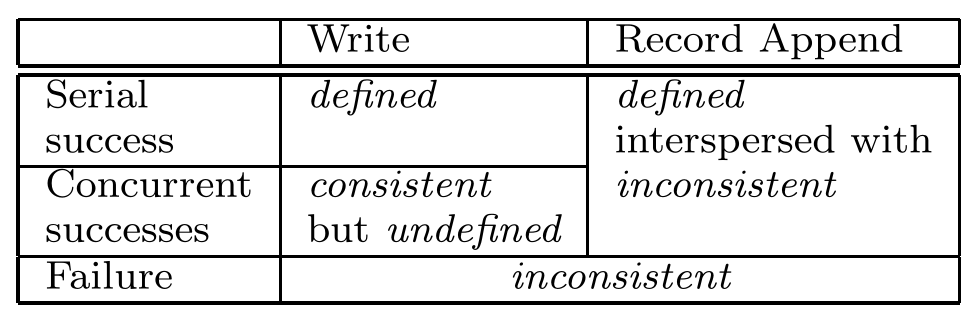
这里有两个状态需要解释一下:参考这篇博文
- consistent:一个file region对于所有的client都是一致的
- defined:要求更严格,除了要consistent,还需要保证写入有效(即client能够看到全部写入的内容)
如上表所示,失败操作都将inconsistent;而当串行执行成功时,是defined;当出现并发操作且成功时,是consistent;
还有两个操作需要区别一下:
- write:指application去指定一个偏移offset去改变内容
- record append:GFS去指定一个偏移offset,至少一次(说明存在重试)的去改变内容
而常规的append只是在文件的结尾处添加数据,GFS指定的offset会被返回给client,并且表示一个已定义区域 defined region的起始位置(GFS通常填充padding或是重复的记录项,而这些区域是inconsistent的)
在一连串的改变后,GFS通过以一定的顺序在一个文件所有的副本上按序执行,并且其中也有版本控制,对于过时的版本会自动忽略(过时的版本的副本称为 Stale replicas 过时副本)
过时副本不会去响应改变,也不会去询问client最新的副本的location在哪里,而是被GC掉
而此时的client由于缓存了stale replicas的location,也有可能再去访问(这取决于缓存是否过期或是是否被重新打开)
2、APP的实现
GFS的应用为了适应弱一致性的特性,使用了一些简单的技术:依赖于追加append、检查点checkpoint、编写自我验证writing self-validating、自我识别记录self-identifying
大量情况下都是追加写。
- 串行追加写
在文件写入完成后,GFS会给文件一个永久的name;即使没有写完也会周期性检查成功写了多少(设置检查点checkpoints)
设置完成后,检查点还包括APP级别的校验和checksum(检查时只会检查最新的检查点,也就是最后一个defined区域)
检查点可以保证增量式的写入,并可以阻止写入那些应用看来还不完整的数据文件
- 并发追加写
writers会至少写入一次。
Writers会给每个记录都准备一个checkpoint,以便于他们自我检验
Readers会处理偶尔出现的填充和重复项(如何处理?可以直接忽略,也可以进行对其进行其他操作,比如删除重复项)
System Interaction
GFS设计的一切都是为了减少Master的交互(避免单独的Master成为整个系统的瓶颈)
这一节介绍的内容主要是如何实现:数据变更data mutations、原子追加操作atomic append、快照snapshot
Leases and Mutation Order
Mutations指的是改变了内容或者元数据的操作
mutations会作用到所有的副本上,GFS通过租用 lease来保证各个副本的mutation的顺序一致
大致过程是:Master会选择所有副本的其中一个作为primary主副本,主副本会决定一个顺序,这个顺序将会变成所有副本的顺序
个人理解lease的含义在于:Master把权利租给其中一个副本,这样做是为了尽量减小Master的交互(下面把这个称为租约关系)
一个租约关系超时时间为60s,只要chunk发生变化,primary就可以在每次的HeartBeat信息上携带mutation给master,而且Master可以收回租约,并且当primary宕机后,租约关系到期Master会选另外一个副本作为primary
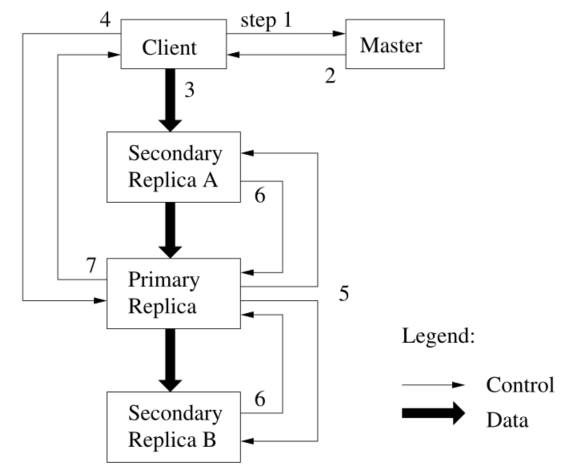
这里按顺序介绍一下GFS的运作流程:
- client请求Master:当前持有lease的primary副本以及其他副本(即图中的secondary replica)的位置
- Master回复client对应的位置,client将这些信息缓存起来以便下次mutation可以直接联系(直到primary失去联系,或是lease到期)
- client将数据推送到每一个副本上(这个顺序无所谓)chunkserver缓存这个数据(LRU方式)
- clients(可能不止一个客户端)向primary发送写请求(Mutations),primary会给这些mutations确定一个具体的顺序,然后primary将顺序update到本地
- primary推送确定顺序后的mutations给其他副本,其他副本也更新到本地
- secondary replica更新完成后,回复primary一个信息表示已完成
- primary向client答复:副本遇到的错误
- 如果primary更新失败:将不会推送到其他副本
- 如果有的其他副本失败:那么可能会出现primary与其他副本版本不一致的情况(此时client会重试mutations的请求,重复3-7的步骤,尝试几次)
如果写请求比较大,或是跨越了chunk的边界,GFS会怎么处理呢?
GFS会对这些请求进行拆分
拆分的操作可能会出现多个客户端下的并发覆盖的现象
(因此可能最终的file region会包含来自不同客户端的片段,并且这也是Consistency Model一节介绍的consistent but not defined的原因——即虽然最终生成的文件一样,但是存在有些客户端快,有些客户端慢,并且后执行的可能会覆盖前执行的,导致这个chunk的状态不能稳定)
Data Flow
数据流和控制流解耦合,有利于提高网络效率
- 控制流:从primary流向secondary
- 数据流:沿着chunkserver的链线性推送(不是使用网络的拓扑结构,比如树)
数据流这样传输可以最大利用网络带宽,client利用管道快速的发送data给最近的chunkserver
比如S1发送给S4,可能并不会直接发送;可能S1最近的是一个S2,S2距离S4更近,这样就会先发给S2,然后S2发给S4(因为S1可能和S2是同一个交换机,这样可以充分利用带宽)
Atomic Record Appends
在consistency model说过,传统的write和record append方式的区别,在于offset是谁指定的。
传统的write因为offset由client指定,所以不能做到并发,一个client去写,另外的必须等待;而record append由GFS指定偏移,最后将偏移返回给client,这样就可以实现并发
record append就是一种mutation,它遵循上述的mutation流程,但是有一点额外的操作:在client的数据推送到所有的副本上后,它会给primary发送请求,primary会判断即将的record append操作是否会使chunk超过预订的size 64M。
- 如果超过了size的大小,primary就会将这个chunk填充padding(补到最大大小)然后通知其他副本也去padding,然后告诉client应该在下一个chunk上执行这个操作
注意:record append最多为chunk size的1/4,这样可以一定程度的避免空间浪费
- 如果符合大小,就返回写入后的偏移量给client
Snapshot
快照就是对file或是directory tree进行一个备份。
类似于AFS,使用写时复制技术copy-on-write
- 当Master接收到snapshot请求后,它首先收回将要操作的chunk的lease(如果这时出现mutation,将会与Master进行交互)
- lease收回后,master将操作存入disk的operation log中,并将disk内的状态同步到内存中,新创建的快照与源文件指向同一个块(此时此chunk的引用计数+1)
- 当client第一次要写入刚做完快照操作的chunk时,由于没有lease,所以会请求master,master发现他的引用计数>1,Master就会指定一个新的chunk去备份这个chunk,然后选择其中一个给予lease,最后回复client primary是谁
- client将mutation写入chunk中
这样利用本地做快照,减少了网络传输
Master Operation
Master的主要负责操作有:对命名空间的所有操作、备份相关操作、负载均衡、GC操作
这一节介绍这些操作的内容
Namespace Management and Locking
GFS维护了一个全路径名 Full pathnames到元数据 Metadata的一个Map表(前缀压缩过,可以高效的存放在Master的内存里)
命名空间内的每一个结点 Node(绝对文件名或是绝对路径名)都联系着一个读写锁
比如一个例子:现在有操作要将
/home/user备份一个快照到/save/user,同时要创建一个文件在上/home/user/foo
那么GFS会有这样的流程:
- 假设先执行了快照,快照操作就会拿到
/home与/save的读锁以及/home/user与/save/user的写锁 - 然后创建操作需要拿
/home、/home/user的读锁,以及/home/user/foo的写锁 - 发现1与2在获取
/home/user时(1要获取写锁,2要获取读锁,读写不能同时)出现了冲突,那么GFS就会按一个正确的顺序去执行操作,比如先让快照操作写入,释放锁后,让创建操作去创建
GFS对于名称空间锁的管理就是,一个对/d1/d2/d3/file的操作,会获取读锁和写锁,读锁会获取/d1、/d1/d2、/d1/d2/d3三个,写锁会获取/d1/d2/d3/file
总结一下,读锁与写锁的作用:
- 读锁是为了保证,操作在执行时,阻止读锁的路径上出现被删除、被重命名、被快照的操作
- 写锁是为了保证,在出现冲突后,GFS可以安排一个合理的顺序去正确的执行
锁的获取严格按照顺序:首先按照名称空间树的级别,之后按照字典序排序
Replica Placement
首先解释一下几个概念:分布式distribution与集群cluster、机架racks与节点node
分布式:指一个S系统,拆分为A、B、C等等多个服务,然后将不同的服务部署在不同的机器上
集群:指一个相同的服务A,部署在多个机器上
(分布式是多个人分活干,集群是多个人干同一个活)
机架:一个机架上有多台服务器
节点:机架上的一台服务器可能就是一个节点
两个来自不同机架上的机器,交流时可能会走一个或多个交换机;
并且一个机架的带宽小于这个机架上所有机器的带宽总和
副本的放置策略只为了两个目的:
- 最大化数据可靠性和可用性
- 最大化网络带宽利用率
一个chunk的默认有三个副本,有两个在同一个机架上,一个在另外的机架上(保证即使一个机架都宕机掉,我们依然有存活的chunk副本可以使用)
对于读操作会利用多个机架的总带宽,但是写操作需要流过多个机架(一种权衡:利于读,不利于写)
Creation,Re-replication,Rebalancing
引起备份的原因有三种:创建了新块Creation、重新备份Re-replication、重新平衡Rebalancing
1、对于Creation
放置副本考虑三个原因:
- 优先放置在磁盘利用率低的chunkserver上
- 最好不要放置在刚刚执行过Creation操作的chunkserver上
- 放置在不同的机架上
对于第二点,是因为我们的实际情况是append-once-read-many一次写后多次读的场景,因此最好将副本分散在多个机器上,可以更好的均衡负载
(假设我们给一个机器一直分配creation操作,这会导致,当有很多读操作来的时候,这个机器的流量会很大,而其他的机器流量几乎没有)
2、对于Re-replication
只要副本的数量低于我们设定的备份数量,就会触发重新备份的操作。(可能我们重新指定了备份大小,也可能有一个chunkserver挂掉,也可能是有一台机架直接停电或是磁道损坏)
重新备份操作有优先级:
- 低于预设置更多的副本优先re-replication(比如A只有一个副本,但是B有两个,我们设定需要三个副本,那么会优先对A操作)
- 优先备份live files而不是最近删除的文件
- 优先备份那些可能会阻塞用户进程的chunk
为了防止clone的流量压倒client的流量,Master限制了GFS系统内clone操作的数量
3、对于Rebalancing
Rebalancing操作是Master周期去执行的,检查当前副本的分布,移动到更好的位置上
Garbage Collection
1、Mechanism
Master回收一个文件的资源有几种情况:
- 用户主动删除了文件
- 被标识为孤立文件 orphaned chunks
在第一种情况下:当用户删除一个文件时,并不会立即删除该文件,但是会立即在operation log内记录关于这个文件被删除的操作,然后将这个文件rename为一个隐藏的名称(通常是删除操作的时间戳),在过去一定间隔,比如说三天后,Master才会将这个文件的资源回收,并将它的元数据也删除
当文件的名称被更改为隐藏名称后,使用这个名称去访问文件,依然可以访问到。并且如果将这个隐藏名称再改为正常的名称,就能阻止这个文件被GC掉
在第二种情况下:Master会定期扫描chunk的名称空间,识别孤立文件(孤立文件就是那些访问到的,不可及的文件,类似于JVM去GC)
在定期的HeartBeat消息中,每一个chunkserver都会向Master汇报它所拥有的chunk的集合,如果Master判断有些chunk不再需要了,就会回复给这个chunkserver(注意:master回复的是那些不在需要的chunk的标识)之后chunkserver会回收资源
2、Discussion
延迟删除比立即删除有几个优点:
- 简单且可靠:创建、删除操作都有可能失败,所以Master要有“记忆力”去记住那些要删除的文件;而立即删除不能这么做
- 节省资源:延迟删除合并到了常规的后台活动内(比如HeartBeat机制),减轻Master的负担
- 安全:延迟收回资源给了我们后悔的可能
但是也有缺点:
- 在存储空间紧张时,可能会对妨碍用户的操作
为了解决这个问题:GFS可以对不同的目录使用不同的备份策略(比如不备份某目录下的文件);并且多次重复强调删除某文件,会加快删除的进程
Stale Replica Detection
副本可能会过期,对于每一个chunk,Master都维护了一个chunk version number 块版本号去区别最新副本和过时的副本。
- 当Master授予新的lease时,对应副本的版本号就会增加,primary和secondary都会持久化存储最新的版本号。
- 当chunkserver重新启动并向Master汇报它所拥有的chunk及其版本号时,这些过时的版本stale replica就会被发现;如果Master发现有的chunk版本号比自己的存储的版本号要高,Master会认为在lease过程中出现了失败,就会更新到最新的版本号
Master在GC过程中回收过时的副本
FAULT TOLERANCE AND DIAGNOSIS
High Availability
实现高可用high availability两个简单有效的措施:快速恢复fast recovery、备份replication
1、快速恢复
master和chunkserver在宕机后都会尽快恢复(我们并不能判断造成中断的原因是什么)
2、备份
chunk备份就如前面提到的,除了备份外,还可以做其他形式的跨服务器备份,如奇偶校验parity或擦除码erasure codes
master如果出现问题,检测设备会立即检测到,并利用备份的operation log文件立即启动一个master(shadow master),shadow master会立即提供一个仅供读操作的文件系统(是shadow而不是mirror,代表会有些许延迟)
Data Integrity
数据完整性都是通过校验和 checksum来保证的
不能使用不同的副本来互相比较:因为无法保证一个副本是定义的,所以不能让他们之间互相比较
每一个副本都必须保证自己的数据完整
一个chunk64M,被分成为了1024个64kb的block,每一个block都有一个32bit的checksum,checksum和其他元数据一样,存入内存中,并且会被持久化
chunkserver在回复request之前,都会验证数据块的校验和(chunkserver不会把损坏的数据传给其他机器);如果检验出有异常,那么会立即回复给请求者返回一个error,并且给master返回一个mismatch信息;之后请求者去找其他副本读取数据,而master从其他副本clone一份到这个位置,完成后删除原本损坏的副本。
检验和在内存内,而且由于我们的操作不会跨很多的块,因此检验和读取也不需要多少,不会占用很多的性能。