MapReduce
Map Reduce
Abstract
Map函数:处理键值对,生成一个中间键值对
Reduce函数:将中间值中相同中间键的联系在一起
这两个函数作用->简化分布式的开发(没有经验的人一样可以轻松编写分布式程序)
Introduction
遇到的问题:并发计算、分发数据、处理失败的这些代码,把原本最简单的计算变成了复杂的代码(简单的问题变得复杂)
解决办法:使用一种模型,这种模型只需要用户指定map与reduce函数,就可以自动的完成并行与分发的操作
Programming Model
- Map方法:(
(k1, v1)->list(k2, v2))- 输入一个键值对,输出一个中间键值对intermediate key/value
- 利用中间键值对,将含有相同key的分为到同一组
- 然后交给Reduce处理
- Reduce方法:(
(k2, list(v2))->list(v2))- 输入一个中间键及其一系列的中间值(中间值通过迭代器Iterator运送到Reduce函数,以免内存无法容纳)
- 将这些值合并在一起,构成一个可能会小一点集合
- 通常只有0或1个输出
Implementation
The right choice depends on the environment
这篇paper的实现适用的环境:连在因特网上的大型商用计算机集群 pc clusers
要求的配置很低,2-4g的内存等等,意在表达MapReduce不需要很硬的计算机环境
Execution Overview
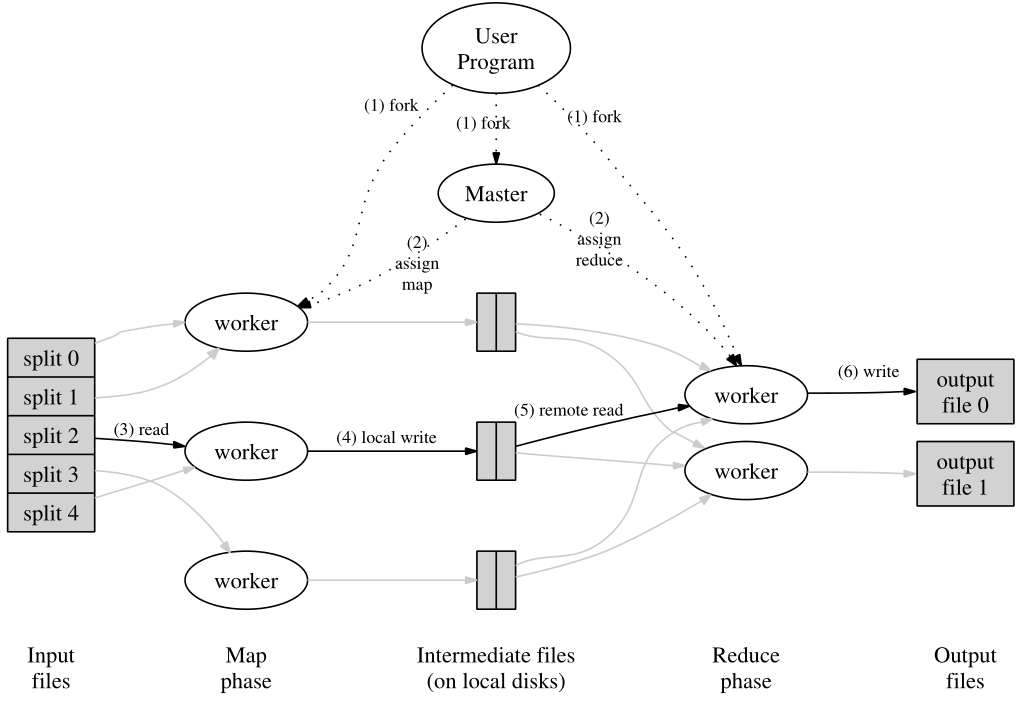
1、用户在用户程序内输入文件后,首先会拆为M块(每块大小不一16M到64M,这是以前的标准了),然后在一个集群内的机器上启动许多副本
2、这些副本中,有一个为Master,其余由Master分配给Worker。其中有M个map任务+R个reduce任务;Master会选择空闲的worker,分配给他们一个map或是一个reduce任务
(之后我会将分配到Map任务的Worker称为MWorker,同理也有RWorker)
3、MWorker:读入之前拆分的数据,送到用户定义的Map函数内(Map函数生成的中间键值对会存放在内存内)
4、内存内的缓存会周期写入到disk,并通过分区函数partitioning function划分为R个区域。其在disk上的地址会被发送到Master,Master负责将这些地址发给RWorker
5、当Master通知那些RWorker时,RWorker会通过RPC读取MWorker的机器上的数据(如图,可以看到第四步是local write,而第五步是remote write,这也表示两者的区别)
在读取完成所有的中间数据后,它会按照中间键 intermediate keys去排序,以便于所有相同key的value可以被分在一起
此处的排序是必须的:(这里多说两句)
MapReduce本质就是一个分布式Sort程序,不管是Map还是Reduce都会去进行Sort操作,Map的Sort操作就是为了减少Reduce部分Sort的负担。
这里的sort算法使用的是快排,而且当内存不够用的时候,会触发外部排序
6、 Reduce的Worker会迭代排序好的中间数据,对遇到的每一个唯一的key,都会传输key和一堆value给Reduce函数。
7、当所有任务完成,Master就会唤醒用户程序(将对MR程序的调用返回到用户程序中)
最后每个Reduce任务都会有一个输出文件,文件名用户可以指定
Master Data Structures
Master的数据结构:
- 存储了每个Map任务与Reduce任务的状态:idle 空闲、in-progress处理中、completed已完成
- 对于处于非空闲的任务还会存储对应Worker的id
可以说,Master是Map任务与Reduce任务沟通的管道。
- 对于每一个完成的Map任务都要存储Map输出的文件的地址location和大小size
- 在Map任务完成后,更新地址和大小
- 将这些信息逐步 incremently推送给in-progress的reduce任务
Fault Tolerance
MR联系了成千上万台PC,因此如果有PC宕机,MR需要考虑如何优雅的容灾。
1、Worker Failure
Master会定期给Worker发送PING信号,如果一定时间内收不到receive,就会将此Worker标记为failed
当一个in-progress任务completed后,会把它的状态变为idle。同样,当任务失败时,也会将失败的任务重置为idle,但Map和Reduce有一些区别:
- 已完成的map任务失败:需要重新执行任务,因为它的输出存在它的local,其他人访问不了
- 已完成的reduce任务失败:不需要重新执行,因为他的输出存在全局的文件系统 Global File System
当Map任务失败后,由WorkerA(运行失败了)切换到WorkerB后,所有在处理Reduce任务的Worker都会重新执行
2、Master Failure
Master会周期性的写检查点,如果Master的任务失败了,那么会在检查点的位置重新copy一个新的任务进行执行
(此时的结构,如果Master本身宕机了,由于只有一个依然会导致整个系统挂掉,此时只能重启整个MR服务了)
3、避免并发错误的措施
如何保证整个分布式系统最终输出正确——依赖于Map和Reduce的原子提交 atomic commits操作
- 一个Reduce task会产生一个临时文件
- 一个Map task会产生R个临时文件(取决于整个Map任务交给多少Reduce任务)
Map任务完成会向Master发送整个文件的名称、大小、位置,如果收到一个已经完成的临时文件名,则忽略它
Reduce任务完成会把临时文件名改为最终文件名,如果多个相同的Reduce任务完成,那么会执行多次的Rename操作(Rename也是原子操作)
对于绝大多数确定性的Map与Reduce,我们可以认为就是在顺序执行;
对于不太确定的MR,会提供微弱的语义
Locality
为了节省网络带宽的一些操作:
将Map任务尽可能的分配给文件所在的机器上,本地读取文件以节省网络带宽,如果对应的机器宕机,那么就找和他在同一个交换机上的机器
Task Granularity
任务粒度:M个map任务,R个reduce任务
每个机器都可能运行map或是reduce,因为这可以提高负载均衡,以及更快的恢复速度(完成的map任务可以迅速的分配给其他工作机)
时间复杂度O(M+R),空间复杂度O(M*R)
Backup Tasks
使MR操作时间变长的原因有很多(称为 straggler):
- 可能有些pc上的磁盘有坏道,这会导致他的读取性能从30M/s降到1MB/s
- 可能由于CPU、内存、DISK、网络带宽之间的竞争,导致一个任务开始的较慢
- 机器的其他意外,比如缓存被禁用
如何解决这些Straggler:
在MR任务快要完成的时候,启动一个相同的MR任务作为备份,当Master收到原本的或是备份的任务完成的信息后,标记任务为完成。
Refinements
一些额外的优化与扩展:
1、分区函数 Partitioning Function
MR产生的临时文件会被分区,默认的分区方式是hash(key) mod R(R是用户指定的输出文件的数量)
2、排序的作用
在分区内,按Key的升序排列
排序后可以输出排好序的临时文件(方便之后的Reduce操作),而且保证了可以支持随机查找
3、组合函数 Combiner Function
组合函数和Reduce类似,常用在要处理Map端的重复元素时使用。
比如词频统计这个问题,在Map端很容易产生很多类似<"sky", 1>这样的键值对,我们可以在发送给Reduce之前,调用一下combiner 函数,将所有key="sky"的字符串加在一起
Combiner和Reduce的唯一区别:输出不同
- Combiner的输出到中间文件
- Reduce输出为最终输出文件
4、输入和输出类型
输入类型:
- text类型:会将输入视为键值对,key为文件的偏移量,value为该行的内容
- 另一种格式也是键值对,按key序排列
用户也可以自己重写输入输出的api
5、副作用
某些情况下,用户可以方便的产生额外的文件(可以输出中间文件),但是这算是一个副作用,因为MR不支持多个输出文件的原子两阶段提交(两阶段提交可以看一看mysql)
6、跳过Bad记录
有时第三方库可能有bug,产生一些bad record,MR支持跳过这些崩溃的记录
原理:每个worker都安装了可以捕获分段冲突segmentation violations和总线错误bus errors的信号处理器 signal handler,在MR操作开始前,MR的库就将参数的序列号记录在全局变量内,如果遇到了一些bad record,那么这个信号处理器就会给Master发送一个UDP包,称为last gasp,Master就会指示跳过这条record
7、本地执行
本地提供了帮助测试的库,以便于调试(为了帮助你在分布式系统中调试)
8、状态信息
Master运行了一个内部的HTTP服务器,用户可以在此查看各个任务的进度等各种信息
9、计数
MR提供了专门用来计数的API,通过PING信号传递到Master
(之后的paper内容没有必要看了)