卷积神经网络CNN
相关资料:
- b站 刘二大人
基本的CNN
数据准备
以MINST数据为例,搭建CNN并进行测试。
MINST:入门级的CV数据库,内容全为手写的阿拉伯数字,包含了6w张训练集图片+1w张测试集图片
1 | import torch |
梯度下降存在的问题
- Batch梯度下降 BGD——遍历所有数据,计算损失函数,计算梯度,更新梯度
计算量大,收敛速度慢,训练的模型一般
- 随机梯度下降 SGD ——每次从训练集中随机选择一个样本,计算其对应的损失和梯度,进行参数更新,反复迭代
收敛速度比batch还要慢,还遇到鞍点问题;但是训练的模型好。
鞍点saddle point 问题:目标函数在此点的梯度为0,但从该点出发的一个方向存在函数极大值点,而另一个方向是函数的极小值点,在高度非凸空间中,存在大量的鞍点,这使得梯度下降法有时会失灵,虽然不是极小值,但是看起来确是收敛的。
注意:鞍点和局部最优解 local minima不同
critical point:包括local minima局部最优解 和 saddle point鞍点

如何鉴别是鞍点还是局部最优点?
是否可以逃离:可以逃离的是鞍点,逃不掉的是局部最优解
这部分可以看这个视频bilibili link:
根据hessian判断
- Hessian的所有特征值均大于0:local minima
- Hessian的所有特征值均小于0: max minima
- Hessian的特征值有时候大于0,有时候小于0:saddle point
- 综合两者DataLoader——MINI-Batch
使用MINI-Batch时要使用一个嵌套的循环:
1 | for epoch in range(train_epochs): |
三个重要的概念::
- Epoch:所有样本都经过一个前馈+反馈,就叫一个Epoch
- Batch-size:一个前向+反向所用的样本的数量
- Iteration:前+反的次数
显然有:Epoch = Batch-size * Iteration
载入数据的过程
在DataSet准备好样本数据后,会经过一个Shuffle过程,将样本数据打乱
在这之后,在进行分批,每一批就是一个Batch

数据预处理
这里关于transform做一个API介绍:这一部分的官方Link
Compose():将多个转换操作组合在一起ToTensor():将一个pillow图片或是ndarray转换为一个张量(即将0-255转为0-1)Normalize:用均值 mean和标准差 std归一化一个浮点张量图像(这个操作只能操作torch的tensor)- 参数
mean:每个通道的均值序列 - 参数
std:每个通道的标准差序列 - 计算公式:
image = (image - mean)/std
- 参数
1 | batch_size = 64 |
神经网络模型设计
torch.nn官方API:,这里列几个用到的:
torch.nn.Module:所有神经网络的类的基类torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0...):二维卷积- 参数1
in_channels:输入通道 - 参数2
out_channels:输出通道 - 参数3
kernel_size:卷积核的大小 - 参数4
stride:步长 - 参数5
padding:图形填充0
- 参数1
torch.nn.MaxPool2d(kernel_size):二维最大值池化- 参数
kernel_size:核大小
- 参数
torch.nn.Linear:linear unit线性单元y = xA + b- 参数1
in_channels:输入通道 - 参数2
out_channels:输出通道 - 参数3
bias:默认为True
- 参数1
tensor.view():用来改变tensor的形状,数据不会变- 返回的新tensor与原tensor共享内存,意味着你改变一个,另一个也会改变
- 当某一维度是
-1,会自动计算这一维度的大小
PyTorch固定的模板就是这样:__init__初始化卷积核、池化、全连接层,forward写神经网络的执行顺序,反馈由Module自动执行无需我们设计
1 | # 神经网络模型 |
损失与优化
1 | # 损失函数:该准则计算输入和目标之间的交叉熵损失 |
损失函数
损失函数也是Module的子类,他负责计算损失,计算损失的算法有很多种
MSELoss:求y与y_hat的差值平方CrossEntropyLoss:交叉熵
交叉熵:它主要刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近
优化器
优化器:optim是一个实现了多个优化算法的包,直接调用即可。
构造一个优化器:使用前需要创建一个优化器对象,必须传入一个module的参数对象,并可以配置学习率lr
model.parameters():检查model所有单元的参数,发现有权重就拿走(假如内部有一个线性单元linear unit,就会调用他的linear.parameters()方法,如果还有其他单元,回依次获取)
使用:只要梯度更新(例如backward()),就可以调用优化器方法step()
训练
整个训练过程可以精炼为如下几个步骤:
- 计算
y_hat - 计算损失
loss - 反馈
backward()(注意:在此之前记得优化器清零zero_grad()) - 更新
step()
1 | # 训练及更新 |
预测
1 | def test(): |
高级的CNN
Inception
GoogleNet是一个比较出名的CNN模型
Inception:对于比较复杂的结构,会有很多复用的结构,这样的结构就叫做Inception
比如这样的一个Inception结构,优点是:往往并不能确定什么样的卷积核比较好,因此一个Inception就可以带多个卷积核,来比较他们之间的性能,如果其中一条线路的效果较好,那么就增大这条线的权重

Concatnate会将不同通道的tensor合并在一起
1*1的卷积核
1*1卷积核的作用:信息融合,以便于降低运算量在多通道的情况下,会将每个卷积核的特征融合到一起
(类比与学校的加权成绩)

降低运算量:假设现在有要对192*28*28的张量进行卷积,卷积核为5*5,最后输出32*28*28:
那么一共要5*5*32*192*28*28=120_422_400
如果给中间加一步16个卷积1*1,那么运算量会变为1*1*28*28*192*16 + 5*5*28*28*16*32=12_433_648
可见,降低了1/10的运算量
代码实现
设这四条线路分别为A、B、C、D,我们在构建模型时,构造方法就应该写以下代码:
1 | def __init__(self, in_channels): |
在初始化后,加入到forward中就可,最后的输出的通道数24*3 + 16 = 88
1 | def forward(self, x): |
Risidual Net
梯度消失
在训练过程中可能会遇到梯度消失的问题
梯度消失:我们嵌套的多层卷积层,如果每个算出的值都是十分接近于0的数,在不断的链式乘积后,就会变得更小,导致梯度消失
解决办法:
【法一】我们可以逐个增加卷积层,去查看哪一层发生了梯度消失
显然这种方法很麻烦
【法二】Risidual Net 残差网络
在基础的NN上,加一个跳连接,如图所示

其中,H(x)= F(x) + x可以保证H'(x) = F'(x) + 1即使F'(x)极小,也可以使梯度变化
但是这种Net结构得保证经过卷积后的shape与原shape一样,因此在shape发生变化的位置,我们需要单独处理(处理方式:对x也做处理或是根本不做跳连接)
代码实现
1 | class ResidualBlock(nn.Module): |
循环神经网络
RNN出现的原因
有时候会遇到类似于根据上一次的数据,去预测下一次的结果的情况。
比如天气预报,假设我们的数据温度|湿度|光照->天气,那么我们根据当天的温度和湿度去预测当天的天气是没有意义的。
如何去预测明天的天气呢?
可以将4行记录为一组,3行接在一起作为训练集(温度1|湿度1|光照1|温度2|湿度2|光照2|温度3|湿度3|光照3),用第四天的天气作为验证集;这样就可以使用三天的数据去预测后一天的天气了。
但是这里存在一个问题,如果单个行记录的参数就很多,那么我们拼凑起来的参数会更多,这样我们在之后的卷积、全连接过程中,可能会参数爆炸
因此为了解决“参数爆炸”的问题,提出了循环神经网络RNN
RNN Cell
RNN适合去解决数据有序的问题:比如天气预测、比如语言类问题(我|要|去吃饭,语言也有顺序)
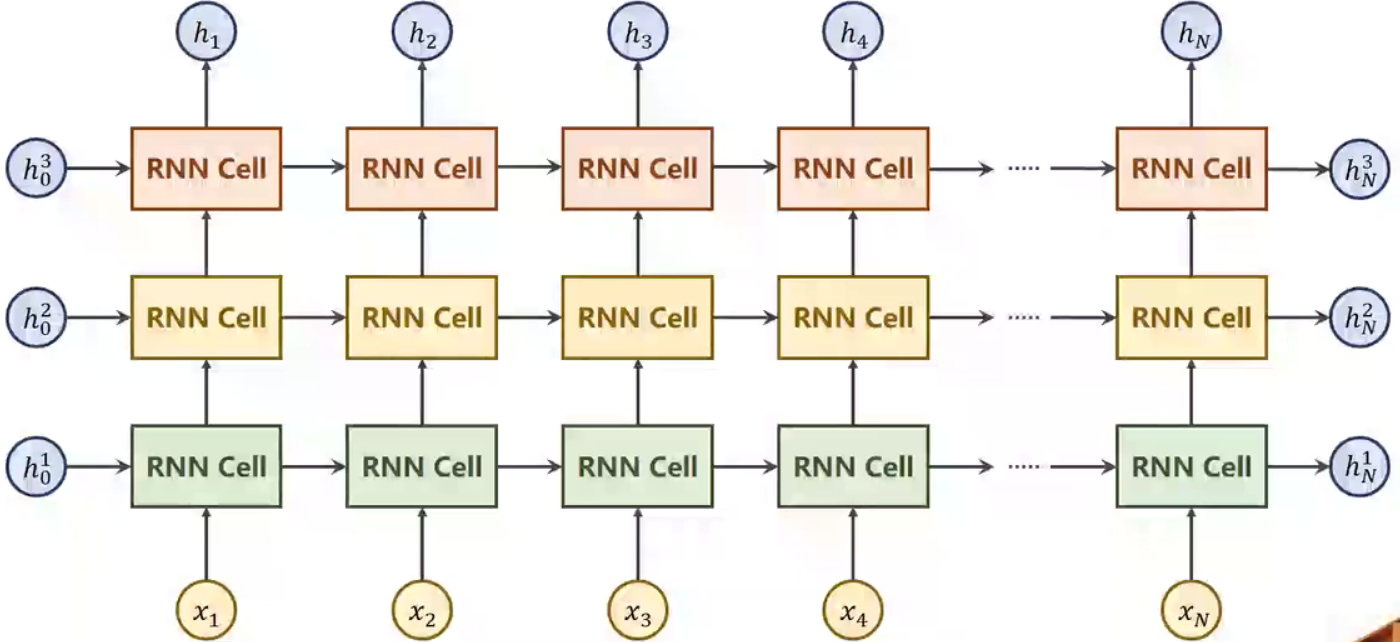
RNN的结构如图所示:

右图是左图的展开式,可以看到,每一次的计算都需要用到上一次的数据,而参数却还使用原来的同一层,这样可以大大减少计算所需要的参数。
RNN cell的本质就是一个线性层,它的计算式如下:
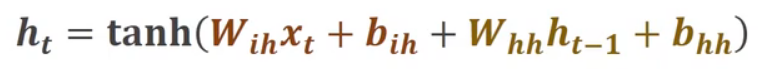
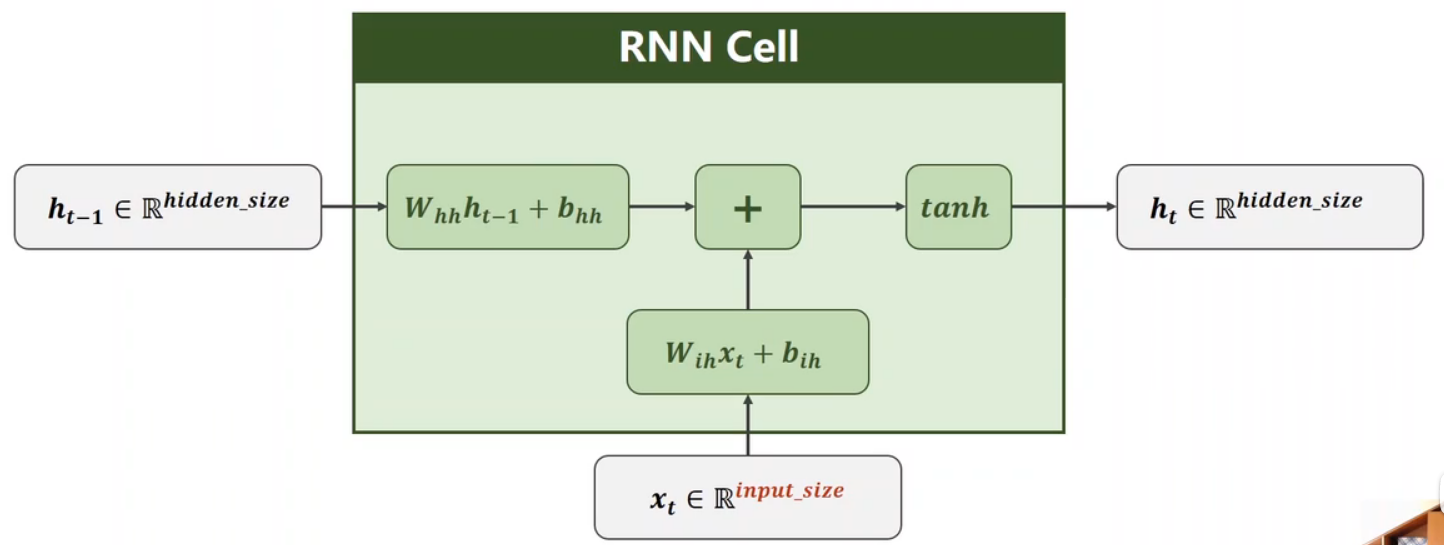
值得注意的是:xt和ht-1看起来做了两次线性变换,其实我们可以把两个矩阵合起来运算,因此其实就是一次线性运算
比如w1*h + w2*x = [w1, w2]*[h, x]^T
代码实现
PyTorch中提供的对应框架有两个,可以使用RNNCell也可以直接使用RNN
- RNNCell
1 | cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size) |
对于inputs要注意的是,他就是输入的序列值,他有三个维度(seq_len, batch_size, input_size)
对于hidden注意,他也有三个维度(num_layers, batch_size, hidden_size)
- RNN
1 | cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers) |
比如一个三层的RNN运算时就是这样的: