cache高速缓存
Cache高速缓存
这一节的内容主要介绍Cache,涉及到的相关知识可以看此篇,比如:
- 局部性原理
- SRAM的结构
几个问题,引入今天的Cache
- 为什么引入了Cache?
- 引入Cache带来了什么问题?
- 如何解决Cache带来的问题?
第一个问题应该很好回答,此篇的目的是记录后两个问题。
Cache
Cache的设计结构
Cache由三部分组成:
高速静态储存器
SRAM,一种十分稳定的存储结构(使用6个晶体管,访问速度是DRAM的十倍,常用在cache)
地址转换模块
Cache行替换模块
Cache中有一些标志位(脏位、回写位、访问位),Cache行替换模块的目的就是根据这些标志位进行相关操作
Cache与内存之间的交流
Cache与内存交换数据的最小单位是一行(一行通常为32字节或是64字节)
而且,Cache的很多行形成一组
工作流程
CPU发来的地址,到达Cache会经过以下步骤:
地址转换模块将CPU发来的地址转换为三部分:组号、行号、行内偏移
Cache根据组号、行号查找cache中对应的行
读操作
- 命中:根据行内偏移,返回数据即可
- 没有命中:分配一个新行,并访问内存,把从内存访问到的数据家载入Cache返回给内存
写操作(分为两种)
- 回写:写入Cache行就结束
- 直通写:写入Cache行并且写入内存
如果没有新行了,那么执行相关替换算法
上述流程对程序员透明,全部由硬件实现
注意:从结构中我们可以发现,Cache的流程与内存的工作流程,甚至是到Mysql、redis这些应用的缓存流程,基本一致(这也是缓存思想的广泛应用)
三级缓存
冯诺依曼结构与哈佛结构
进入正题之前,先介绍两种计算机的设计理念
两者的区别:
- 冯诺依曼结构:讲求数据与指令混装
- 哈佛结构:数据与指令分开装
基于冯诺依曼结构的计算机,设计简单,而且对硬件的要求也简单;
基于哈佛结构的计算机,运行速度快,主要有两个优点:
- 可以并发的读取指令与数据(冯需要分时执行)
- 由于指令通常情况下不会动态修改,而数据则需要频繁的修改,因此可以进一步优化指令Cache的设计(冯需要全部重新载入)
为什么我要引入两种计算机的结构设计思想?
因为平常我们用到的计算机,其实大体都是基于冯诺依曼的设计理念,对于嵌入式的设备来说,哈佛结构更受欢迎
而在Cache的设计中,L1 cache就使用了哈佛结构这种设计思想,整体上来看cache其实还是冯诺依曼的设计思想
三级缓存的结构
现代CPU将Cache分为三级,如图:
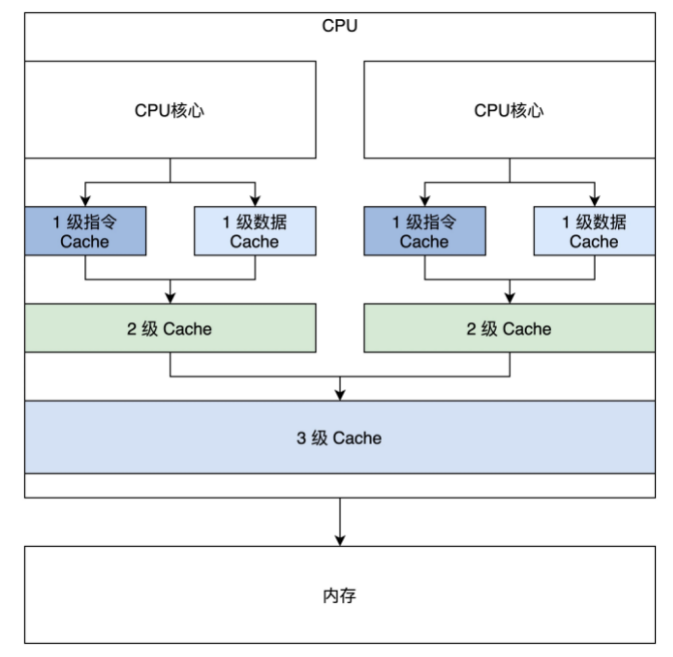
这是一个双核心的CPU,三级缓存等级不同:
- 一级缓存:指令与数据分开(如图:指令Cache与数据Cache)
- 指令进入指令Cache,指令涉及到的数据进入数据Cache
- 二级缓存:CPU核心独占
- 三级缓存:核心之间共享
三级缓存带来的问题:
使用缓存,就会带来缓存一致性问题,CPU设计了三级缓存,就涉及到了三种缓存一致性问题
(CPU 的 L3 Cache 与设备内存,如 DMA、网卡帧储存,显存之间的一致性问题此处不进行讨论)
指令Cache与数据Cache的缓存一致性问题
一级缓存:将指令与数据分开存储,就涉及到了缓存一致性问题
怎么样会出现?
可能存在这么一种情况:
CPU执行指令1 + 地址A ,去执行地址A所在的指令2,但是某些自修改程序(可以修改运行中代码指令数据)就改为了新的指令(即将地址A的代码修改为指令3)
但是修改指令也需要CPU,因此CPU会将修改后的新的指令(指令3)放在数据缓存(注意,此时指令缓存还是旧的指令(指令2))
此时如果执行,那么有可能运行的还是旧的指令
因此存在指令Cache与数据Cache缓存一致性问题
如何解决?
对于这种情况,需要先将数据Cache的数据写回内存,并让指令Cache无效,重新去加载内存中的数据
核心与L2 Cache的缓存一致性问题
L2 Cache是一个CPU核心独占的,L3是核心之前共享的;
但是读取相同的数据,是不需要走一遍L3->L2->l1的流程的
硬件上实现了:对于核心1已经读取的数据可以直接复制到核心2的L2、L1中
怎么出现缓存一致性问题?
核心1修改了指令,但是核心2拷贝的是旧的指令
如何解决?
通过缓存一致性协议,比如MESI
缓存一致性协议——MESI
MESI:定义了四种基本状态
- M(Modified)已修改
- E(Exclusive)独占
- S(Shared)共享
- I(Invalid)无效
举个栗子:
最开始只有一个核读取了A数据,此时状态为E独占,数据是干净的;
后来另一个核又读取了A数据,此时状态为S共享,数据还是干净的;
接着其中一个核修改了数据A,数据变脏,此时会向其他核广播数据已被修改,让其他核的数据状态变为I失效
而本核的数据还没回写内存,状态则变为M已修改
等待后续刷新缓存后,数据变回E独占,其他核由于数据已失效,读数据A时需要重新从内存读到高速缓存,此时数据又共享了
缓存实战
开启缓存
x86 CPU 上默认是关闭 Cache 的,需要在 CPU 初始化时将其开启
开启的方式:只需要将CR0寄存器的CD、NW位同时清理即可
CD=1表示Cache关闭NW=1表示CPU不维护内存数据一致性
1 | mov eax, cr0 |
获取可以读写的内存
对于程序员来说,最主要的目的,就是想知道哪块内存还可以使用
我们可以直接调用BIOS实模式下的中断服务即可
中断服务是int 15h,但是它需要一些参数
1 | _getmemmap: |
每次中断都输出一个 20 字节大小数据项,最后会形成一个该数据项(结构体)的数组
1 |
|