kafka
Kafka
可以从其他很多知识中,串联到kafka中,很多设计思想都是相同的。
Kafka是什么
在0.9.0版本中,Kafka的官方定义是一个分布式、分区、复制的提交日志服务。它提供消息传递系统的功能。
在0.10.0版本中,Kafka的官方定义是分布式的流处理平台
Kafka起源于Linkedin公司,2010年贡献给Apache开源基金会,2012年成为顶级项目,2014年成立了Confluent商业化公司,目前为止,Kafka的版本更新到了3.5。
kafka的发行版有很多,除了商业化的Confluent Kafka,还有Cloudera Kafka和Hortonworks Kafka两个面向于大数据的Kafka发行版。
常见的消息模型及消息队列
首先需要介绍几种消息通信模型:
- JMS:Java Message Service API(Java消息服务)
- 专门针对于Java语言
- 定义两种通信方式:点对点模型(P2P)、发布订阅模型(Pub/Sub)
- 代表实现有:ActiveMQ
- AMQP:Advanced Message Queuing Protocol(高级消息队列协议)
- 支持事务,数据一致性高,多用于银行、金融行业
- 协议模型:队列(queues)信箱(exchanges)绑定(bindings),消息先放于信箱,根据绑定的不同的路由规则,再发送到对应的队列中。
- 代表实现有:RabbitMQ、Spring AMQP、Spring JMS
- MQTT:Message Queuing Telemetry Transport
- 用于IOT
- 为小型无声设备之间通过低带宽发送短消息而设计
kafka的消息格式与传输方式
消息引擎主要的作用就是发送消息,消息的格式如何以及如何发送消息是消息引擎的主要设计的内容,也是核心
- 消息格式:
- 可以使用JSON、CSV、XML格式等
- 也可以直接使用开源序列化框架:Protocol Buffer等
- 传输模型:一般来说主要有两种传输模型
**点对点模型 (Peer to Peer)**:指的是A发送的消息只可以传输给B(不能有其他系统染指)
发布订阅模型 (Pub / Sub):发布订阅机制,有一个主题的概念,发送方(发布者)与接收方(订阅者)可以关注同一个主题,相同的主题下接收方可以接收到发送方发送的消息
Kafka的选择:kafka同时提供了P2P与Pub/Sub两种模式,消息在kafka内以日志的方式记录
为什么要使用消息引擎?
三个原因:
- 为了信息传输的松耦合
当下的数据存储方案很多很多:mysql、Flume、SparkStreaming、Flink,他们之间的数据传输可以使用消息队列来进行解耦的数据传输。
- 削峰填谷(这也是根本原因)
何为削峰填谷?
上游的服务一般会由很多下游的服务提供,如果上游的请求量在一瞬间达到了很大的程度,那么很有可能冲垮下游的服务,导致雪崩(类似于Redis缓存雪崩的概念)
削峰填谷就是要将上游的流量以一种平滑的方式将数据传输给下游。
举个例子:如果上游突然激增TPS(每秒事务请求数),引入Kafka 能够将瞬时增加的订单流量全部以消息形式保存在对应的主题中,既不影响上游服务的 TPS,同时也给下游子服务留出了充足的时间去消费它们
- 异步通信
比如:用户在官网投递了A公司的简历,官网的页面会立即返回“投递成功”,但是发送短信和发送邮件的操作会先发送给消息队列(因为这两步的操作也有耗时时间),然后由下游的短信模块和邮件模块慢慢消费。
kafka基本结构
Kafka角色
- 生产者:即向主题发送消息的客户端
- 消费者:从主题接收消息的客户端
- 客户端:统称生产者与消费者
kafka核心组成
**主题(Topic)**:它存放同一类的消息,比如点赞、评论、收藏各是一个Topic
分区(Partition):Topic会划分为多个分区(Partition):每个分区都是一组有序的、不可变的消息日志(日志的格式就是key、value键值对)
- 消息的存储是以键值对的方式,如果key为null,那么就按照轮询的方式写到不同的分区中(同一个Topic的不同分区);如果key不为null,相同key的消息会有序的排放在相同的分区中。
- 生产者生产的消息只会被发送到一个分区中(如果一个Topic有2个Partition,只会被发到其中一个中,不在partition0就在partition1)
Replication:一个主题有多个分区,一个分区可以有多个副本
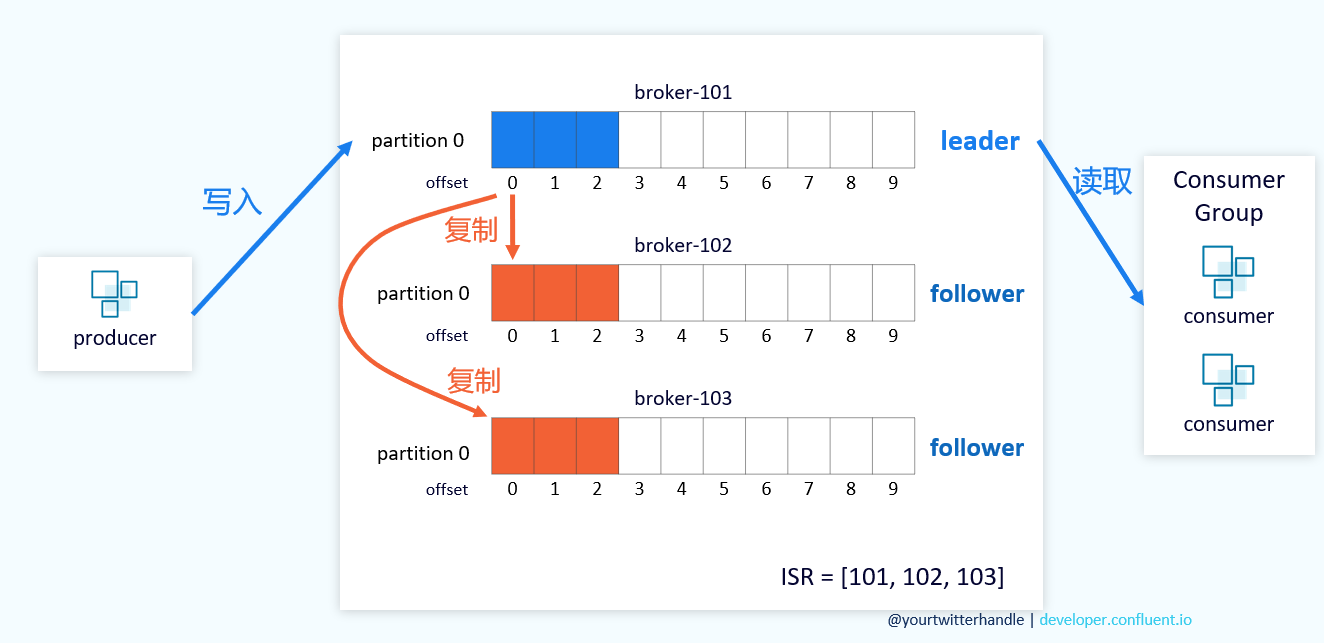
- 与Hadoop的分区容备不同的是,kafka的副本分为Leader和follower,Leader负责读写请求,follower不负责读!只是实时复制leader的变化。
- 图中还显示了一个ISR的集合,这个集合存储了分区的副本的ID,如果有一个副本掉队,就会删除,等到其跟上leader的进度,才会将其填入。
Broker:主题的服务器端(消息代理),他有两个主要的作用
- 接收和处理客户端发送来的请求
- 消息持久化:将消息写入到磁盘
Kafka集群结构
3.0之前的kafka需要Zookeeper来配合使用
- 一台服务器可以有多个Broker(但是一般一个服务器只维护一个Broker)
- 一个Broker可以有多个Topic(不同Broker的Topic是一样的)
- 一个Topic可以有多个Partition
- 一个Partition可以有多个Replication
如图示:
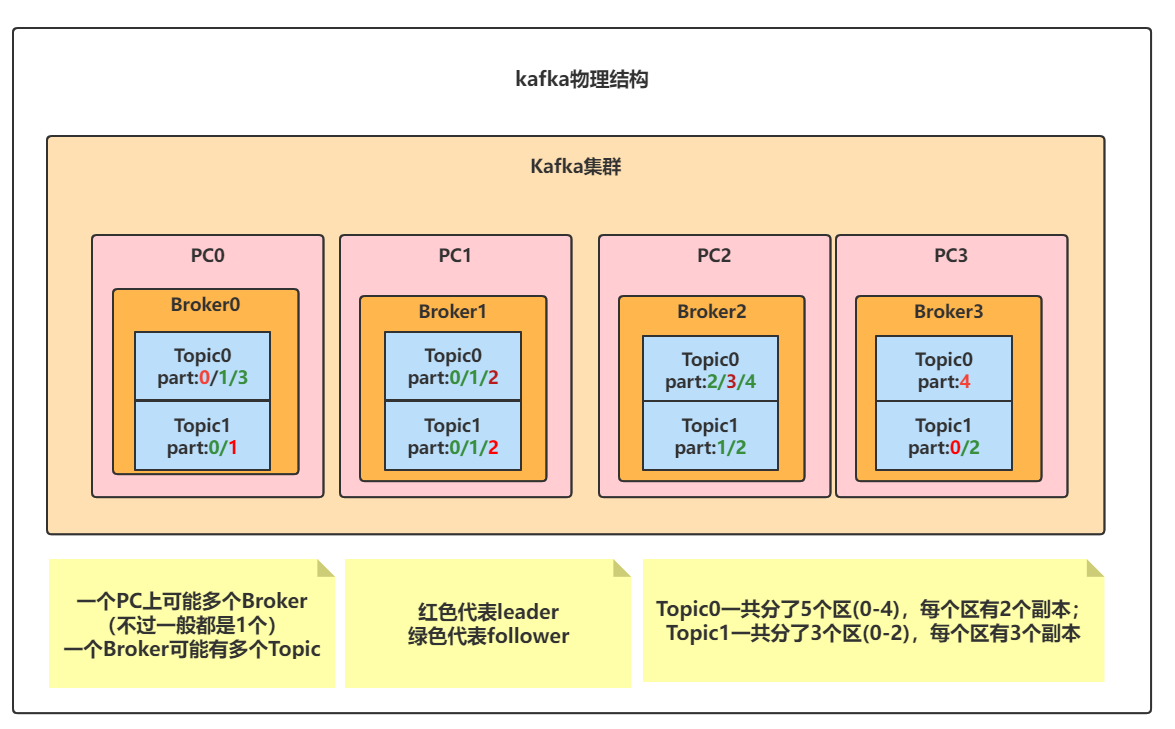
上图表示的集群中:有4个Broker,2个Topic;Topic0有5个分区(0-4),每个分区有2个副本;Topic1有3个分区(0-2),每个分区有3个副本;标为红色的副本表示其为leader,绿色的为follower;
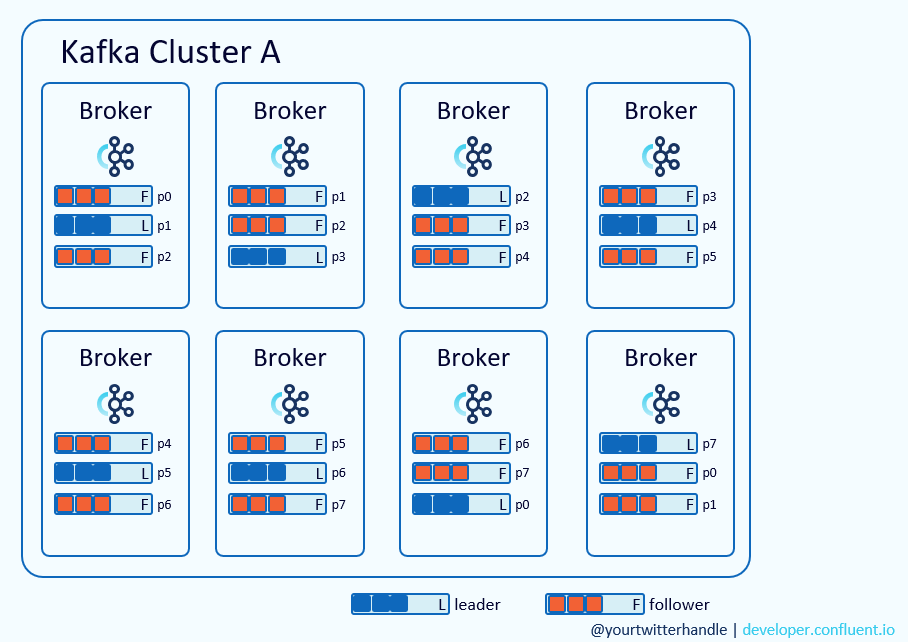
在上图的集群中:有8个Broker,1个Topic;8个Partition;每个Partition有3个replication
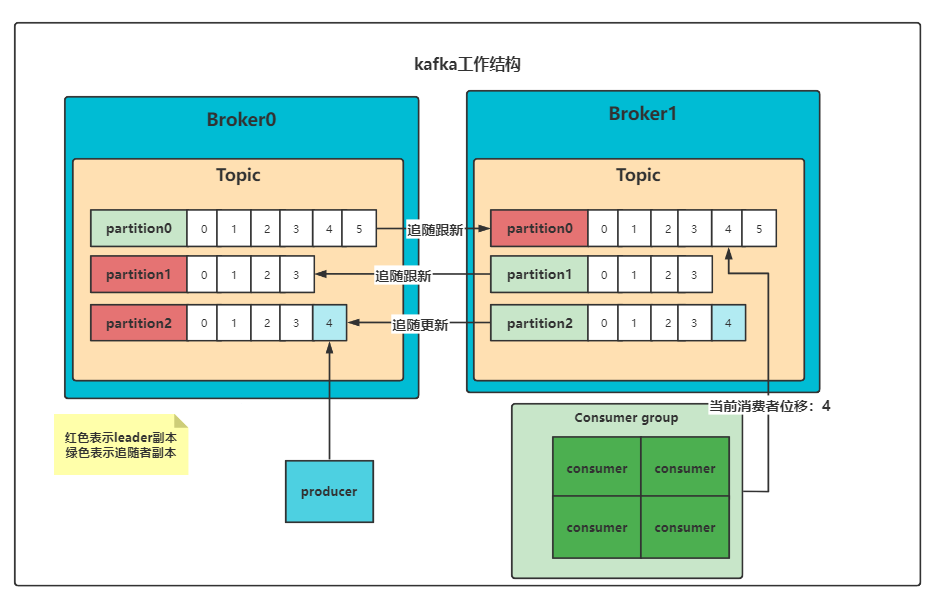
Kafka工作总共有三层结构:
【第一层:主题层】
- 每个主题可以配置M个分区
- 每个分区又可以配置N个副本
【第二层:分区层】
- 每个分区可以有多个副本
- 但只能有一个领导者副本,其他全为追随者副本
【第三层:消息层】
- 分区是一个有序的消息队列,消息的位移从0开始
Kafka的消费者
Kafka的Consumer为什么是一组一组的Consumer group?
为了实现P2P模型,前面说到,kafka不仅提供了发布订阅这种模型,而且支持P2P这种方式,因此引入了消费者组
一个消费者组中的消费者都是消费相同主题的消费者
这样做也可以提高整个消费者端的吞吐量
Kafka的高可用
Kafka提供高可用的手段主要有两个:
- kafka集群
- 备份机制
kafka集群
即将:Broker进程分配在不同PC上,每台PC都可以运行很多Broker进程,通过Zookeeper将不同的PC联系起来,这样就构建成了kafka集群
为什么要这么做?
Broker是可以全部到一台机器上的,但是通常都会分配到不同的机器上
这样可以避免一个PC宕机的时候,其他的PC还能正常工作,依然可以继续对外提供服务
备份机制
类似于hadoop、redis、mysql,很多都有备份机制来保证高可用
在Kafka中,每一个主题有很多分区,每一个分区可以配置N个副本
(还是此图)
在这些副本中,分为两类:
- 领导者副本(Leader Replica):负责提供与客户端(消费者与生产者)的服务
- 追随者副本(Follower Replica):负责跟进领导者的副本(不提供服务)
(在Redis、Mysql中,从库是可以对外提供读服务的)
(在以前这也被称为master、slave体系(主从体系)但是由于漂亮国某些政治正确的原因,改为Leader Follower这种体系)
为什么kafka的主题要分区?
为了解决伸缩性问题,即如果leader副本积累了太多的数据,以至于一台Broker都无法存储了
分区就是为了解决伸缩性问题的
为什么kafka的追随者副本不设计为可以对外提供读服务呢?(就和redis、mysql一样)
两个原因:
- 首先mysql是为了负载均衡,平衡主库压力(主库需要负责读写操作),才设计从库来负责读,尽量分摊主库压力;而kafka中,每个Broker分布在不同的PC上,本来就进行了负载均衡
- 消费者组读取数据,有一个消费者位移,如果follower也要提供读服务的话,那么设计实现会比较复杂(涉及到一致性问题,需要同步leader与follower的进度)
kafka数据的持久化
kafka如何持久化数据?
kafka使用消息日志(log)来持久化数据,而且是追加写(类似于Mysql的bin log)
追加写满了怎么办?
kafka将日志又细分为多个日志段(Log segment),消息被追加写到最新的日志段中
写满后,kafka会自动切分出一个新的日志段,并将老的日志段封存起来
kafka在后台还有定时任务会定期的检查老的日志段是否能被删除回收