NIO
Java NIO
NIO
NIO:可以叫做Non-Blocking IO,也可以称为New IO,个人觉得第二种比较合适,因为非阻塞只是NIO的特点之一
(但是非阻塞确实是核心中的核心,所以怎么叫都是可以的)
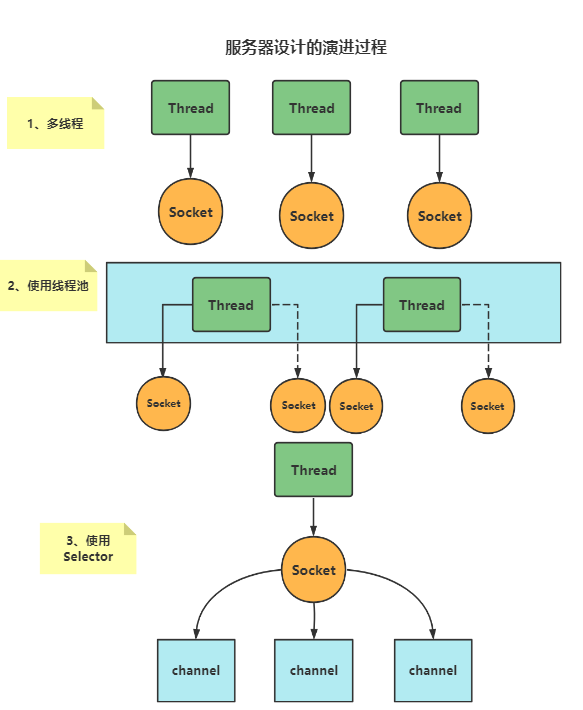
1、在没有NIO下,如何实现一个服务器?
【法一】使用多线程开发
- 特点:一个Socket连接,使用一个线程来进行管理
- 优点:一对一的服务,适合于连接数少的场景
- 缺点:
- 内存占用高(一个Socket需要一个线程,如果很多连接同时进入,那么就会占用很多的内存)
- 线程上下文切换成本高
【法二】使用线程池
- 特点:使用线程池思想,控制线程数量
- 优点:避免了创建大量的线程导致内存占用过高的问题,适合短连接场景
- 缺点:属于阻塞模式(即一个线程同时只能给一个socket连接提供服务),线程的利用率不高
【法三】使用NIO的Selector
- 特点:用一个线程管理Selector,Selector去管理注册在此的通道(下面会详细介绍)
- 优点:适合连接数多,但是流量低的场景(low traffic)
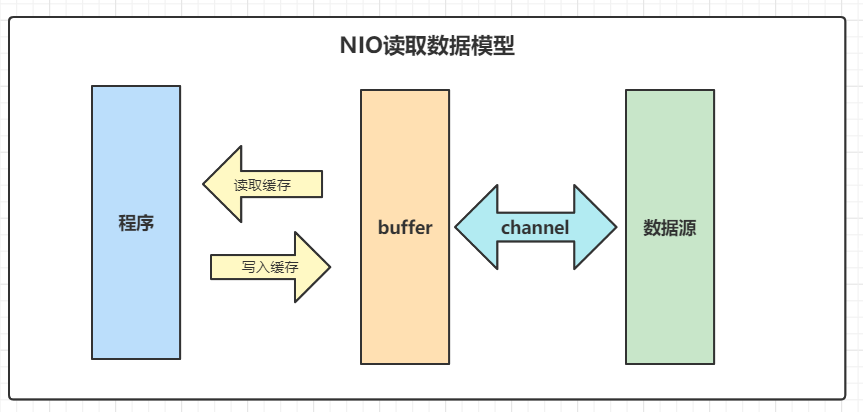
2、JavaNIO由三个核心组件构成:
ChannelBufferSelector
除了这三个还有其他组件,如Pipe、FileLock等等
3、NIO与BIO的对比:
- BIO是面向流的;NIO面向缓冲区
- BIO只能向后读,不能向前读;NIO可以向前也可以向后读
- BIO是单向的,一端要么读要么写;NIO中通道是双向的,一端可读可写
- BIO是阻塞的;NIO是非阻塞的
4、程序在NIO中的读取数据过程如图:
Buffer
Buffer 缓冲区:可以理解为一个数组,通道必须与Buffer一起使用
具体的实现类有:
ByteBuffer CharBuffer ShortBuffer IntBuffer LongBuffer FloatBuffer DoubleBuffer分别对应除了boolean之外的八种基本数据类型
Buffer常用API
具体的实现类有:
ByteBuffer、CharBuffer 、ShortBuffer 、IntBuffer 、LongBuffer 、FloatBuffer 、DoubleBuffer分别对应除了boolean之外的八种基本数据类型(常用的是ByteBuffer与CharBuffer)
核心API:
put(value):将value写入缓存(从当前的position开始写入,并增加position的值,即相对位置的写入)get(arr[]):读取position位置下的数据到一个数组中(如果不传参数,默认读取一个字符)hasRemaining():判断position与limit之间的距离,如果还有数据可以处理,那么就返回trueclear():清空缓冲区(清空的原理并不是真的清空了,只是将position的位置为0,limit设置为capacity,即切换回写模式)flip():可以将缓冲区由写模式切换到读模式(将limit设为position的位置,再将position设置为0)compact():压缩,将未读取的数据(即position与limit之间的数据)向前移动,然后position指向最后一个未读取的数据之后,然后limit指向capacity
其他API:
capacity(); limit() ; position():返回当前capacity/limit/position的值mark():标记当前position的位置,当调用reset方法时,会重置到mark标记过的位置(只能在 0-position之前)remaining():返回position与limit之间的距离reset():重置position到mark标记过的位置rewind():将position设置为0(即让position回到初始的位置),取消mark标记位
创建buffer
allocate(long):创建一个指定大小的缓冲区;是一个静态方法;(注意:buffer对象不能new,只能通过allocate分配)warp():把已存在的数组包装为一个Buffer对象(无论操作两者中的哪一个,另一个也会变化,因为就是同一个数组)
注意:
这两种创建方式,都是间接的创建了一个缓冲区(间接:是指这个缓冲区在JVM堆中)
如何将一个字符串转换为一个ByteBuffer数组?
有三种方式:
1、使用ByteBuffer的wrap方法
2、使用Charset
3、创建ByteBuffer再put字符串的字节数组
1 | String str = "hello"; |
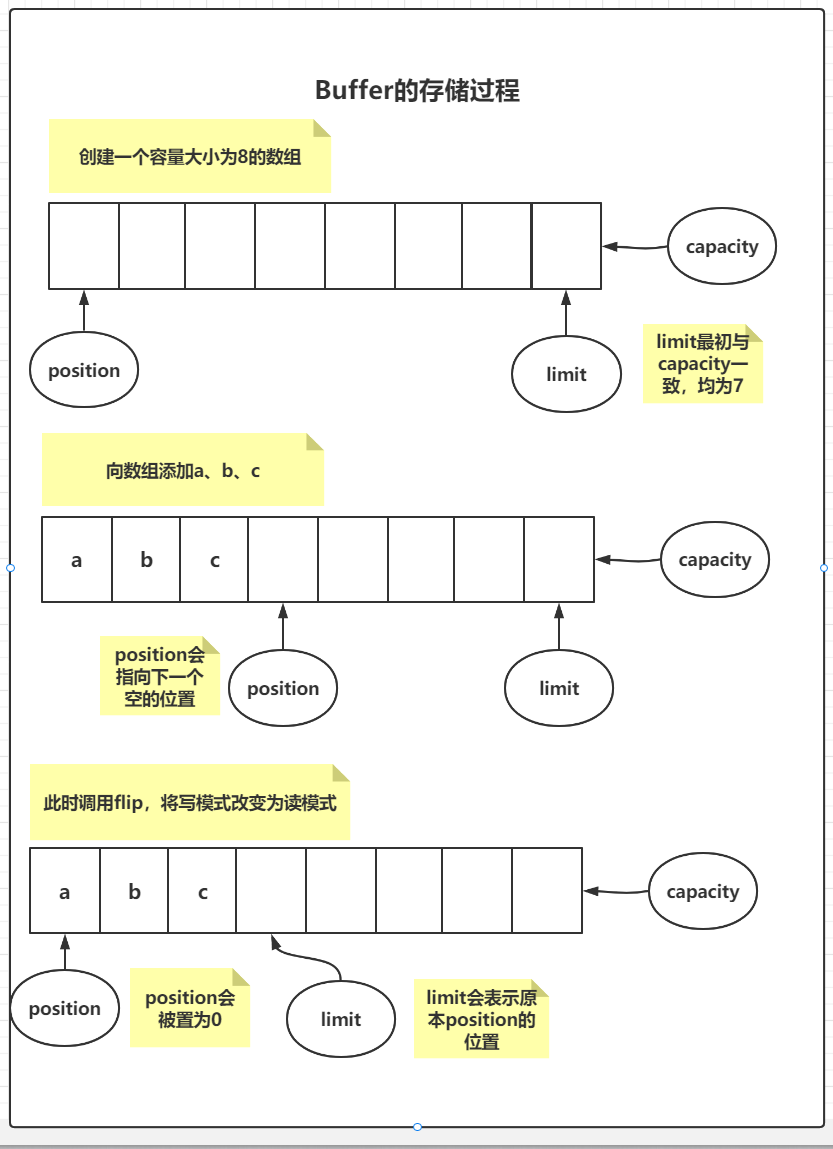
Buffer的属性及属性的变化过程
Buffer有四个重要的属性:
capacity:表示当前Buffer的容量大小;创建时指定,创建后不能修改;如果写满了capacity,那么需要等清空后才能写入数据position:表示当前的位置,初始时为0,每读写一个数据,position就+1,最大为capacity-1limit:指第一个不能被读或写的位置(即可以表示只能读取或写入多少个数据)mark:设置一个标记位,当进行reset时,会将position的值变为mark原本标记的值
四个属性有这样的大小关系:0 <= mark <= position <= limit <= capacity
下面有个图,可以清晰的表示整个过程
理解了这样的变化过程,再来看读取数据时的代码,就懂了:
1 | while (true) { |
直接缓冲区
首先要明确一个概念:只有byteBuffer才有资格参与IO操作,因为数据全为01,只有byteBuffer存储的才是01二进制,所以只有它才能IO操作
为什么要用直接缓冲区?
使用非直接缓冲区可能会导致性能损耗(多一次拷贝过程)
假设给一个通道传入了一个非直接缓冲区,那么通道会先创建一个临时的直接缓冲区,将非直接缓冲区的数据复制到临时的直接缓冲区,使用这个临时的直接缓冲区去执行IO操作(多一次拷贝,增大了开销)
直接缓存区存在的问题:
- 直接缓存区绕过了JVM的堆栈,不受JVM控制,所以有可能我们创建的直接缓存区代价会更高
- 直接缓存区分配会较慢,因为Java需要调用OS的函数进行分配,所以会较慢
如何创建一块直接缓冲区?
调用ByteBuffer.allocateDirect(1024)即可
分散读与集中写
这主要是两种思想
分散读就是把原本的数据一次读到多个buffer中,集中写就是将多个buffer的内容一次性写入
这两种思想分别有两个接口代表:ScatteringByteChannel(有read方法)、GatheringByteChannel(有write方法)
都可以传入一个ByteBuffer的数组
1 | ByteBuffer bf1 = ByteBuffer.allocate(5); |
集中写同理
TCP的粘包问题
很多人觉得这并不是一个问题,而是一个TCP的特性,关键在于你怎么看待
什么是粘包问题?
- 以接收端来看:因为TCP是面向流的协议,所以不会保持输入数据的边界,导致接收端很可能一下子收到多个应用层报文,需要应用开发者自己分开,有些人觉得这样不合理,就起名为粘包
- 以发送端来看:用户数据被TCP发送时,会根据Nagle算法,将小的数据封装在一个报文段发送出去,导致不同的报文段黏在了一起
如何解决?
发送方可以关闭Nagle算法
- 设置
TCP_NODELAY就能关闭Nagle算法 - 但我不太认同这种做法,最好不要使用这种方法
- 设置
接收方对粘包无法处理,只能交给应用层:
固定消息长度:一条消息就发送一个固定大小的数据,然后填充空白
- 缺点:浪费带宽
格式化数据:每条数据有固定的格式(开始符,结束符),这种方法简单易行
- 缺点:但是这种方法需要保证传输的字符中没有该开始符与结束符,而且因为需要挨个遍历,传输速度不是很快
TLV格式:即Type类型、Length长度、Value数据,在类型和长度已知的情况下就可以方便的知道消息大小,分配合适的buffer
- 缺点:buffer需要提前分配,如果分配过大,影响server的吞吐量
- HTTP1.1是TLV格式(先传输类型)
- HTTP2.0是LTV格式(先传输长度)
此处举一个例子:(这里属于格式化数据的一种方式,使用到
\n作为分隔符)
网络上有多条数据发送给服务端。数据之间使用\n进行分隔,但由于某种原因这些数据在接收时,被进行了重新组合。
例如原始数据有3条为
1 | Hello,world\n |
变成了下面的两个 byteBuffer(黏包,半包)
1 | Hello,world\nI" m zhangsan\nHo |
如何解决?(但这种方法需要对字节挨个遍历,所以效率不是很高)
1 | public static void main(String[] args) { |
Channel
Channel:通道,类似于IO流,但是与流不同的是Channel是双向的(流是单向的)
IO流:如InputStream、OutputStream要么输入(读),要么输出(写)
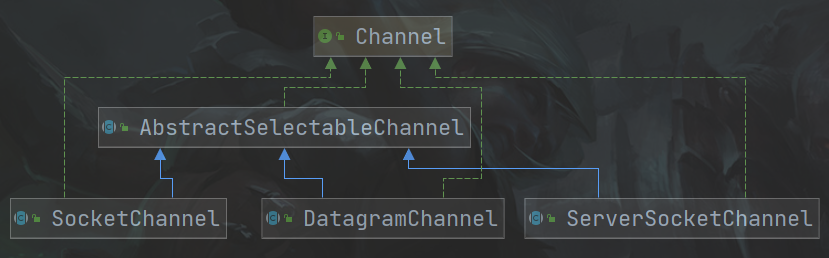
但是Channel是双向的,实现类如下
FileChannel:从文件中读写数据DatagramChannel:通过UDP读写网络数据SocketChannel:通过TCP读写网络数据ServerSocketChannel:可以监听新进来的TCP连接,就像Web服务器一样,对每一个新连接都会建立一个SocketChannel
特点:
- 通道的操作是双向的(可以只读、可以只写、还可以读写)
- 通道可以操作的数据种类很多(可以是文件IO、网络Socket都可以操作)
- 通道的操作是异步的
- 不能直接访问通道,需要与Buffer合作(通道读必须从一个Buffer读、通道写必须写到一个Buffer内)
- 通道不能复用!关闭了就没了
具体在Java中,就是一个接口,有两个方法
1 | public interface Channel extends Closeable { |
Channel全家福
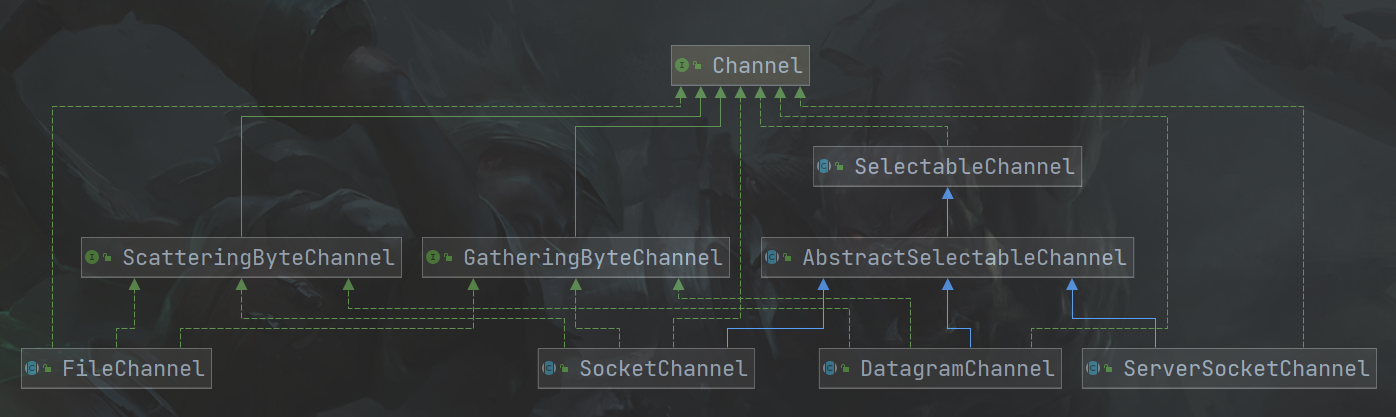
- 可以注意到FileChannel没有继承SelectableChannel类(**
FileChannel是阻塞的**) - 除ServerSocketChannel外,均实现了
ScatteringByteChannel与GatheringByteChannel接口
FileChannel
用来对文件进行操作的通道
1、获取
FileChannel的方式:(不能new来获取,有三种获取方式)
- 获取
FileChannel可以使用RandomAccessFile这个类 - 也可以使用
InputStream(这样创建的FileChannel只能读) - 也可以使用
OutputStream(这样创建的FileChannel只能写)
2、
FileChannel读取数据到Buffer中
- 通道的
read()方法,必须读入到一个缓存中,而且会返回读取到的字节数(或者说是,缓冲区中的字节数有多少) - 需要在缓冲的
buffer.hasRemaining()的循环中使用 - 如果读完,会返回-1
Demo如下:
1 | // 此文件有21字节,设置模式为读写均可 |
下面精炼一下读文件的Demo,可以记下来:
1 | try (RandomAccessFile rw = new RandomAccessFile("D:\\temp.txt", "rw")){ |
3、写数据到Buffer中
write方法,需要传入缓冲- 需要在缓冲的
buffer.hasRemaining()的循环中使用
1 | RandomAccessFile rw = new RandomAccessFile("D:\\temp.txt", "rw"); |
4、其他方法
positon():返回从文件开头位置到当前位置的字节数position(long):设置当前位置(注意:如果指定的位置超过了文件当前的位置,然后进行了写入,会导致文件中间部分没有被写(文件空洞))size():返回文件大小truncate(long):截取前指定大小的数据,后面的数据将会被删除
1 | RandomAccessFile rw = new RandomAccessFile("D:\\temp.txt", "rw"); |
5、
force方法与RandomAccessFile的模式
force(boolean)方法:- 此方法是为了保证对文件的所有更新操作都写回磁盘
- 参数为
false表示只写回文件内容 - 参数为
true表示既要写回文件内容,又要写回元数据信息(即文件的权限信息等)
RandomAccessFile(fileName, mode):传入一个文件的路径以及一个模式,此处的模式有四种r:只读,如果调用write会抛出异常rw:可读可写;如果文件不存在,将会被创建rws:可读可写,并且所有的更新操作每次都会被同步的写入磁盘,会写入文件内容以及元数据(即带有force(true)的rw模式)rwd:可读可写,并且所有的更新操作每次都会被同步的写入磁盘,会写入文件内容(即带有force(false)的rw模式)
6、通道间通信:
transferFrom与transferTo
通道之间可以传输数据,这两个方法仅仅是方向不同而已
(通道之间传输数据没有用到缓存,不知道底层实现是否用到了缓存)
transferFrom(ReadableByteChannel src, long position, long count):三个参数,第一个传入另外一个通道,第二个为起始位置,第三个传入想要传输的字节数
1 | RandomAccessFile rw1 = new RandomAccessFile("d:\\temp.txt", "rw"); |
注意:transferTo方法是有上限的(最大为2G,超过这个范围,那么只会传输2g的内容,剩下的数据就不会再传输了)
可以这样实现传输大于2g的内容:
1 | try ( |
Socket通道
此处的Socket通道泛指了三个实现了AbstractSelectableChannel的类:SocketChannel、DatagramChannel、ServerSocketChannel
(注意:SocketChannel我会专门提到他的名词,如果提到Socket通道,泛指的是三个类)
已经有了Socket,为什么要引入Socket通道?
传统的Socket会为每个Socket连接创建一个线程,但是Socket通道仅仅只开辟一个或几个线程就可以提供成百上千的服务,大大提高了性能!
好处:
1、节省了线程切换的上下文开销
2、便于管理!
Socket通道的特点
ServerSocketChannel只负责: (不负责读写)- 监听传入的连接
- 创建
SocketChannel对象
DatagramChannel与SocketChannel负责真正的读写操作- Socket通道可以被重复使用
- Socket通道可以设置为非阻塞模式
ServerSocketChannel
ServerSocketChannel:可以理解为一个实现了非阻塞模式的ServerSocket
特点:
socket():可以获得ServerSocket对象,然后调用其bind()方法去绑定一个端口(注意:ServerSocketChannel本身没有bind方法!!(JDK1.7有了bind方法,默认绑定本地地址))ServerSocketChannel有accept()方法,会返回一个SocketChannel对象;但是使用ServerSocket的accept()方法就还是阻塞的- 如果返回的对象为
null,说明当前没有连接
- 如果返回的对象为
- 因为继承了
AbstractSelectableChannel类,所以可以设置为非阻塞模式
ServerSocketChannel对象的创建:
不能new,需要调用ServerSocketChannel的静态方法open()
核心API
accepct():方法是阻塞方法(如果不设置为非阻塞)bind():绑定一个端口configureBlocking(boolean):默认为true(阻塞模式)
使用单线程+Channel实现服务器:
1 | // 0. byteBuffer |
缺点:我们使用了死循环来一次次判断连接情况(这样也会浪费CPU的资源)
因此有了Selector来解决这个问题(使用Seletor后,代码的逻辑会发生变化,具体看下一节)
SocketChannel
SocketChannel:一个用来连接到TCP套接字的通道
特点:
- 实现了可选择通道,可以被多路复用
- 基于TCP传输协议
- 支持两种模式:阻塞与非阻塞(同样也是通过
configureBlocking调节)
如何创建SocketChannel
ServerSocket对象的accept方法会返回SocketChannel对象- 直接使用
SocketChannel.open()也可以创建SocketChannel对象
核心API
configureBlocking(boolean):默认为true(阻塞模式)read(ByteBuffer):读write(ByteBuffer):写
DatagramChannel
Selector
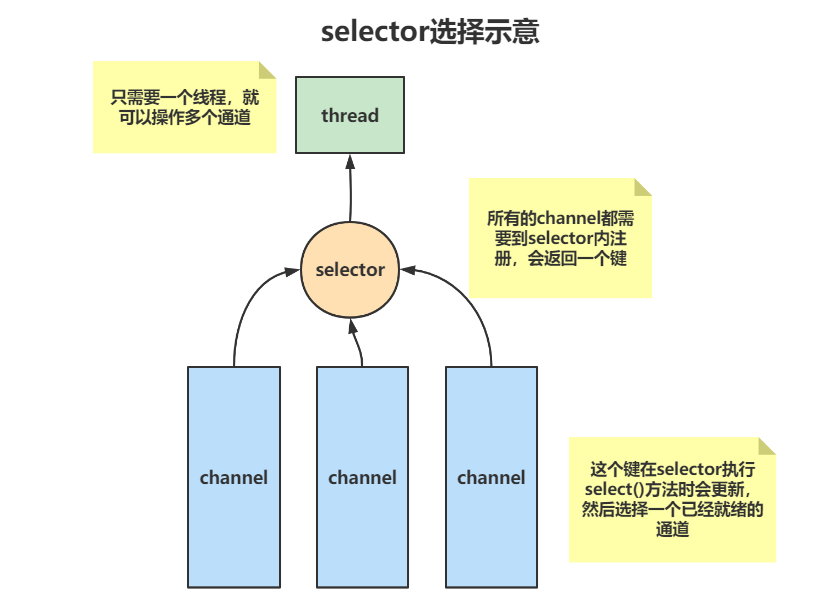
Selector :选择器提供了一种选择执行已经就绪的任务的能力
允许单线程处理多个通道,大大提高了效率
Selector选择的原理
1、每一个Channel都需要在Selector上注册
2、注册后会返回一个选择键,选择键代表了当前通道是否已经就绪的信息
3、每执行一次select方法,都会更新所有的选择键,然后选择一个已经就绪的通道
注意:
- 这些Channel必须是
SelectableChannel的子类(比如:FileChannel就不是其子类,也就不能被选择)
Selector有关的三个类
Selector:选择器类负责管理在此注册的通道的集合信息以及他们的就绪状态SelectableChannel:可选择通道,是一个抽象类,继承这个类的类为可以进行选择的类(FileChannel就没有继承这个类)SelectionKey:选择键类,封装了通道与选择器之间的注册关系,含有两个比特集(一个代表注册关系所关心的通道操作,一个代表通道已经就绪的操作)
Selector
如何建立一个Selector系统?
1、创建Selector:不能new,需要调用Selector.open()方法
2、设置通道为非阻塞(只有非阻塞的通道才能注册到选择器)
3、通道注册:调用register(selector, OP)进行注册,两个参数,第一个为选择器,第二个参数为想让选择器关心的操作,会返回一个SelectionKey对象
此处可以设置的关心的操作OP有:
1 | SelectionKey.OP_READ = 1<<0; // 是否有可读的通道就绪 |
如果我们想要关心多个操作,可以通过|位或运算符将OP连接起来
1 | channel.register(selector, SelectionKey.OP_READ | SelectionKey.OP_WRITE) |
4、select()轮询:查看是否有就绪的通道,会返回当前就绪通道的数量
Selector维护的三个集合
Selector维护了三个集合:keys集合、selectedKeys集合、cancel集合
keys():此集合保存已注册的键(此集合不能修改!)selectedKeys():此集合保存关心事件发生的键,此集合我们只能移除,不能添加(添加是自动进行的)- 注意这个集合的特点:会自动添加集合,但是不会自动删除集合
- 因此我们在处理完成后要主动
remove掉,要不然会报异常
- 已取消键的集合,使用
cancel()方法后的键都会放在这里
Selector的核心就是
select方法,它的执行过程为:
- 检查已取消集合:如果集合非空,就将集合内所有的键从另外两个集合中移除,然后注销其相关的通道
- 检查selectedKeys集合:确定每个通道所关心的操作是否已经就绪
- 返回值:返回上一次调用select后进入就绪状态的通道的数量
SelectionKey
选择键: 表示通道与Selector之间的注册关系,注册一个通道就会返回一个SelectionKey
相关API:
channel:返回对应的通道selector:返回通道注册的选择器cancel:取消注册关系isValid():判断注册关系是否有效interestOps():以整数的形式,返回所关心操作的bit掩码,可以用此来判断选择器是否关心通道的某个操作1
2Boolean isAccept = interestOps & SelectionKey.OP_ACCEPT == SelectionKey.OP_ACCEPT;
// 判断一下与的结果是否与Accept相等isAccept()等操作:上面的这种方式判断太麻烦了,API直接就有相关判断方法
selector的要点辨析
1、select方法什么时候会不阻塞,向下执行?
总共用如下几种情况:
- 发生事件时
- 客户端发起连接请求,触发accept事件
- 客户端发送数据、正常关闭、异常关闭都会触发read事件
- 如果要发送的数据大于缓冲区,会触发多次read事件
- channel可写,触发write事件
- 在Linux下nio bug发生时
- 调用
selector.wakeup() - 调用
selector.close() - selector所在线程
interrupt
2、事件可以不进行处理吗?
不可以,事件要么就remove,要么就cancel,不可以不进行处理
如果不进行处理,select每次都会返回这个事件,白白浪费CPU的资源
3、用完key为什么要remove?
Selector维护的集合SelectedKeys添加是自动的,删除需要我们手动进行,一旦有我们关心的事件发生,那么Selector就会将此key添加到这个集合内
如果我们用完key,没有remove,那么此集合内就还会存在这个key,在使用这个key进行操作的时候,就可能会出现异常(比如空指针异常)
注意:remove只是将这个集合内的该键删除了,如果对应的事件还会继续发生,那么这里光删除集合内的key是没有用的,应该cancel掉对应的事件
4、处理read事件要注意的事情
【一】处理好客户端的正常与异常断开
正常断开依靠read方法返回值
异常断开依靠catch抓住异常后,将此key取消掉
1 | try{ |
【二】处理好消息边界
例如我们开辟一块buffer为4字节的缓冲区,客户端传输两个汉字“中国”,默认字符集UTF-8对于1个汉字占用3个字节,就要处理好消息边界的问题!
(如何解决消息边界问题下一节详细介绍)
5、处理write事件要注意的事情
我们发送的数据可能不是一次性发送的!
1 | ByteBuffer buffer = Charset.defaultCharset().encode(sb.toString()); |
这样处理虽然可以保证数据全部发完,但是不符合NIO非阻塞的思想
好的处理方式应该是,如果我们一次性发不完,可以先去处理其他事情(避免一直发送导致发送缓冲区满,导致轮询)
完整代码如下:
1 | while (true){ |
处理消息边界
在Buffer一节,介绍过什么是TCP粘包,这里因为read操作涉及到了粘包,所以我们要对其进行处理!
消息发送的异常情况
消息边界:发送一个消息可能有三种异常情况
buffer的大小不足以放下一个完整的消息。- 这种情况下,只能将buffer扩容
buffer空间足够,但是只放了1.5个消息,剩下的半个消息我们需要进行拼接(在Buffer一节,我们介绍了一个利用\n来截断消息的步骤)
如果buffer空间不足(即一条消息的大小就超过了buffer),nio是如何进行处理的呢?
例如:buffer空间为8字节,传输一条10字节的消息
服务器收到read事件,将数据读到8字节的缓存中,然后打印输出
然后,服务器会再次收到read事件,将剩下2个字节读入,打印输出
(即:服务器会变为多次read事件读取消息,因此对于这种情况我们需要扩容)
如何给buffer扩容
buffer不能是局部变量
最开始我们的代码是这样的,但是如果我们想要给一个buffer扩容,buffer就不能是一个局部变量
1 | //收到read事件 |
那么,不能是局部变量,我提到最外面可以不可以呢?
不可以,我们要保证一个线程的buffer是私有的,如果我们提到最外面,那么多个线程操控一个buffer,这就乱套了(线程不安全)
因此我们要借助附件attachment
注意:附件可以保证每一个线程间是私有的
regiser()传入的第三个参数就是附件,如果要获取附件,可以调用key的attachment()方法
1 | if (key.isAcceptable()) { |
什么时候进行扩容呢?
当然是buffer空间不够的时候,之前我们自己实现的split()方法最后是使用的compact()方法去完成拼接
如果一个消息大于buffer,那么他的\n的索引依然会大于limit
比如:
1 | buffer大小8字节 |
因此,扩容的时机就是position==limit
1 | SocketChannel channel = (SocketChannel) key.channel(); |
这样两次read事件,就能把消息拼接到一起了!
1 | buffer大小8字节 |
此处我们的扩容简单的进行了翻倍扩容,这是比较简单的实现,在Netty中,就设计的比较优秀了,此处我们只是抛砖引玉
buffer大小如何抉择有两种思路:
ByteBuffer需要设计为可变的buffer:
- 思路一:首先分配一个较小的buffer,如果不够用,再分配一个更大的buffer,并将原本的buffer数据copy到新buffer内
- 优点:消息连续好处理
- 缺点:数据copy消耗性能
- 思路二:用多个数组组成buffer,一个数组不够,就将多出来的内容写入新的数组
- 优点:避免了copy消耗性能
NIO服务器的完整DEMO
此DEMO是上述样例的完整品(没有write的处理部分),仅供参考使用
1 |
|
多线程优化
如何优化
前面我们都是使用单线程,即将所有的事件全部放在一个线程内进行操作,不能发挥多线程的优势
所以我们可以进行多线程优化:(这也是Netty的实现原则)
优化的手段
可以将ACCEPT请求与读写请求分开,如图:

有两类线程:
- boss线程:专门负责处理
ACCEPT事件 - worker线程:处理
READ与WRITE事件
boss线程只有一个,而worker线程可以根据服务器的CPU核心数来确定,并且可以加入负载均衡策略,让每一个worker线程一起出力。
优化手段总结:
1、按事件分类,分给不同的线程执行
2、worker间实现负载均衡
实现逻辑
boss线程一开始就有,worker线程是慢慢创建的,具体的逻辑如下
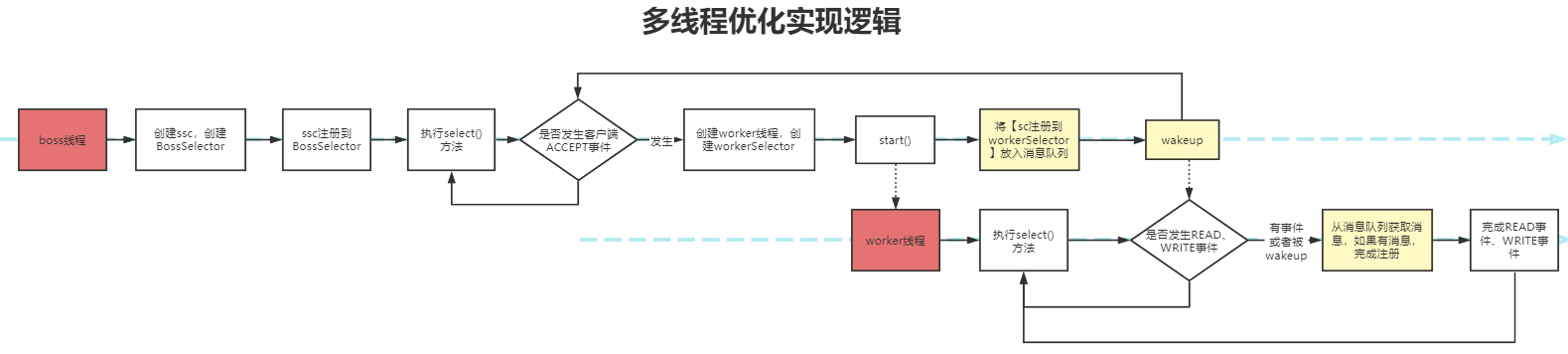
值得注意的是:要让select与注册全让worker线程来执行,通过消息队列+wakeup()方法来进行传输消息(即我标为黄色的部分)
这样可以避免出现执行顺序不正确带来的顺序问题。
实现代码
1 |
|
零拷贝
传统IO
例子:服务器从磁盘读取一个文件,然后用socket写回给客户端
代码如下:
1 | File f = new File("helloworld/data.txt"); |
从磁盘读入文件并发送,整个过程内部工作流程如下:
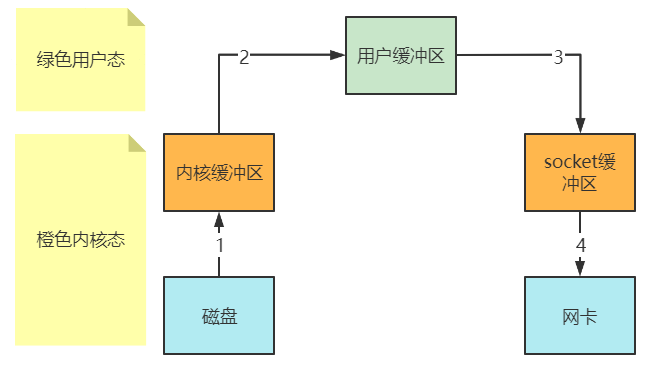
- Java代码调用
read方法去读取文件,由用户态陷入内核态,将文件读入到内核缓冲区内(期间Copy使用DMA技术,无需CPU参与) - 全部读入到内核缓冲区后,由内核态回到用户态,将内核缓冲区的数据写入到用户缓冲区(即
buff字节数组中)(期间Copy使用CPU) - 调用
write方法,将数据从用户缓冲区写入到socket缓冲区(CPU参与拷贝) - 向网卡写数据,由用户态陷入内核态,(DMA实现数据Copy,CPU不会参与)
- 发送完毕后,再从内核态返回到用户态
所以我们可以知道,简单的一个过程发生了:
- 2次用户态与内核态的转换
- 4次数据Copy
效率十分低下
NIO优化
NIO可以分配直接缓存,直接缓存的特点是OS与Java都可以访问的一块内存(Java可以使用DirectByteBuffer将堆外内存映射到JVM内存中使用)因此减少了一次copy

现在有:
- 2次用户态与内核态的转换
- 3次数据Copy
Linux2.1提供sendFile进一步优化
Linux2.1后,提出了sendFile方法,对应到Java就是通道的transferTo与transferFrom实现了拷贝数据(即不需要再将数据复制到用户态的缓冲区内)
此时可以直接将内核缓冲区拷贝到socket缓冲区
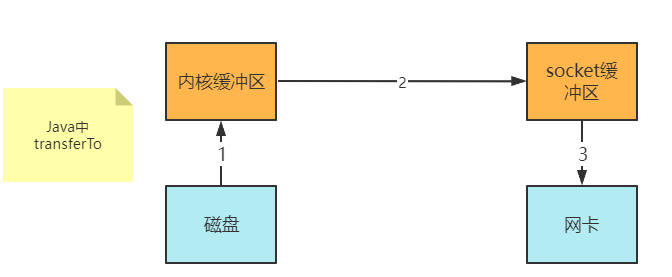
- Java调用
transferTo,陷入内核态(使用DMA将数据读入内核缓冲区) - 数据从内核缓冲区传输到socket缓冲区(CPU参与拷贝)
- 最后使用DMA将socket缓冲区的数据写入网卡,不会使用CPU
现在有:
- 1次用户态与内核态的转换
- 3次数据Copy
Linux2.4再进一步优化
Linux2.4后,再进一步优化,可以直接将数据传输到网卡
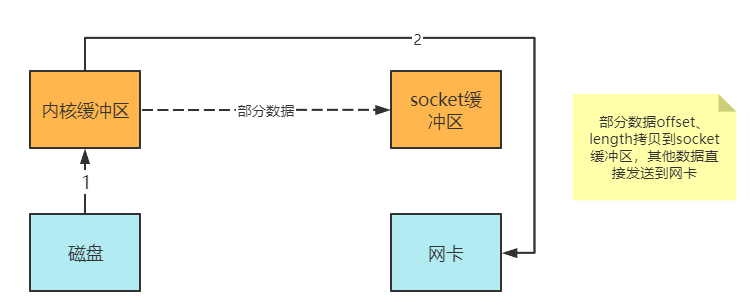
- Java调用
transferTo,陷入内核态(使用DMA将数据读入内核缓冲区) - 直将一些offset和length拷贝到socket缓冲区,几乎无消耗
- 将数据从内核缓冲区直接写入到网卡(DMA)
现在有:
- 1次用户态与内核态的转换
- 2次数据Copy
这也就是所谓的零拷贝
零拷贝:并不是真正意义的无拷贝,而是不会拷贝重复的数据到JVM内存中,因此成为零拷贝
零拷贝的优点:
- 更少的用户态与内核态转换
- 不利用CPU
- 适合小型文件传输