MySQL进阶
三大范式
第一范式:数据库表的每一列都是不可分割的原子数据项
第二范式:在1NF的基础上,非主属性必须完全依赖于码(在1NF基础上消除非主属性对主码的部分函数依赖)
第三范式:在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除非主属性对主码的传递依赖)
另外补充:
BC范式:在3NF的基础上,消除主属性对键的部分依赖和传递函数依赖(此外还有第四范式、第五范式。)
名词解释:
函数依赖
A→B,通过A属性的值,可以确定唯一B属性的值,则称B依赖于A(A是B的充分条件)
例如:学号→姓名,(学号,课程名)→分数
- 完全函数依赖:A→B,A是B的唯一充分条件
- 部分函数依赖:A→B,并且A的一个真子集A’也可以退出B,A’→B,就称为部分函数依赖。
- 传递函数依赖:A→B,B→A,通过A可以确定唯一的C
码
- 候选码:能唯一标识一组元组,而其子集不能
- 主属性:候选码的属性
- 非主属性:不是主属性就是非主属性
Mysql基本架构
大的层面分为两层,Server层 与 存储引擎层:
Server层有五个部分组成、存储引擎有很多实现
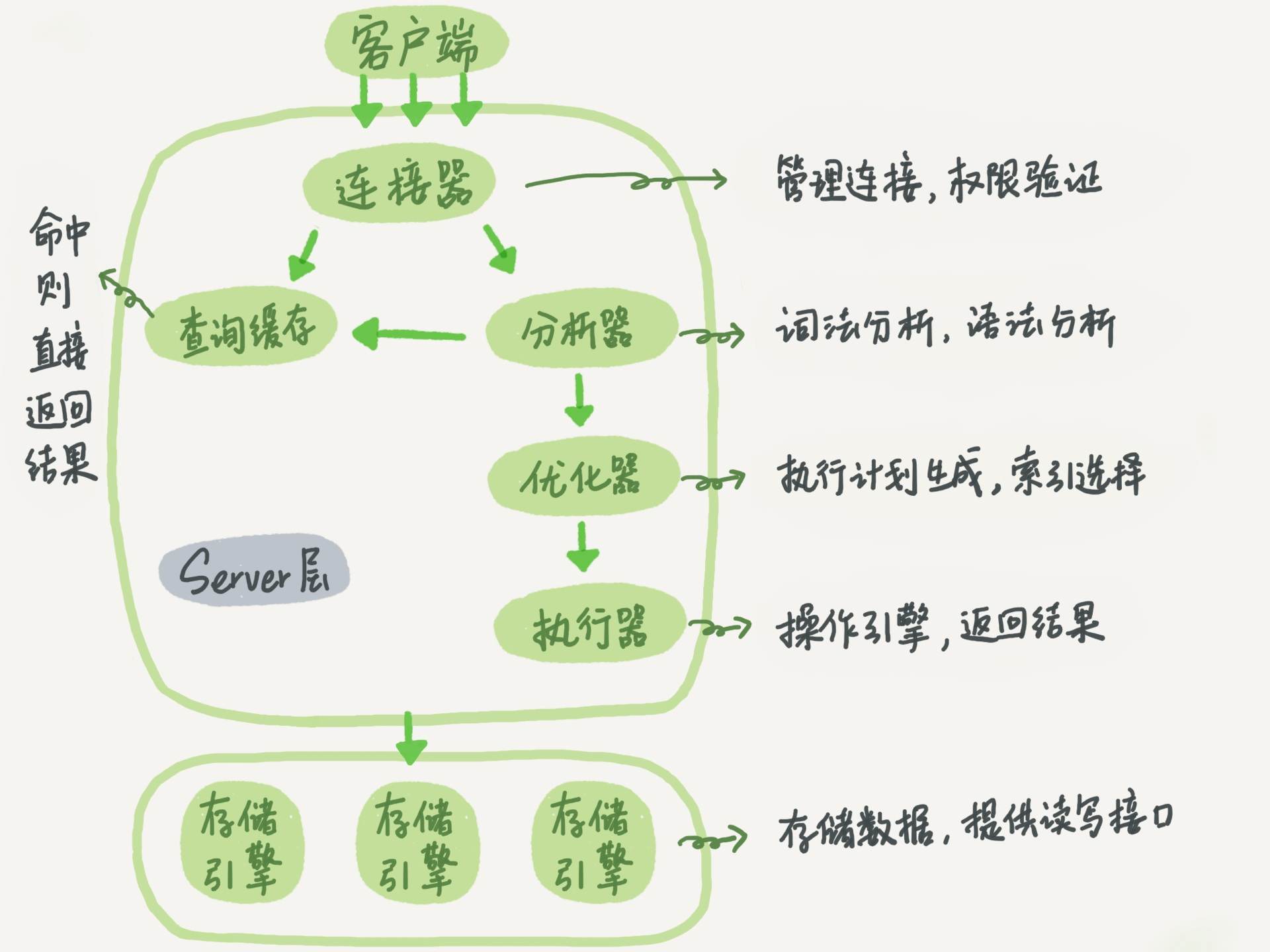
连接器——管理连接、权限验证
有两个作用:
- 管理连接
- 获取权限:如果用户名密码认证通过,连接器会到权限表里面查出你拥有的权限。之后,此连接的权限判断逻辑,都将依赖于此时读到的权限
(注意:成功连接后,即使管理员对此用户的权限进行修改,也不会影响已经存在的连接权限)
长连接:用户连接成功后,一直使用一个连接来持续请求
短连接:每次执行很少的sql就断开连接,下次重新创建连接
注意:
连接时间由参数
wait_timeout控制,默认8小时建议使用长连接,避免浪费资源
为什么全部使用长连接后,有些时候MySQL占用内存涨得特别快?
因为Mysql在使用时,临时使用的内存是在管理连接的对象内的,所以会导致占用内存涨得快,导致内存占用太大,被OS强行杀掉~
解决措施:
- 定期断开长连接。使用一段时间或在一个大的查询后断开,下次重连。
- 执行
mysql_reset_connection(Mysql5.7 +版本),可以初始化连接资源
查询缓存——命中返回
每次查询的结果,都会放在查询缓存中,这里相当于一个K-V映射。
K是你的查询语句,V就是查询结果
Mysql发现你查询的语句一样,那就会直接返回
注意:
- 不建议使用查询缓存!因为容易过期,只要有一个更新语句,查询缓存就会失效
- 系统配置表(长期不会更改的表)才适合用查询缓存
- 可以设置参数
query_cache_type为DEMAND,这样默认的sql都不会使用查询引擎 - Mysql 8.0彻底去掉了查询缓存功能
分析器
识别分析你的Sql语句(比如说看看你用了什么关键字,是什么类型的语句等等),如果有问题抛出异常
优化器——语句优化
可以加快查询速度,确定执行方案
进阶:
- 在有多个索引的时候决定使用哪个索引
- 在使用join时决定连接方式
优化器如何估计成本
优化器需要估计每个可能的索引的选择性和成本,通过index dive技术来估计成本:
- 首先判断索引的区分度(基数),即该索引是否可以帮助过滤掉大量的无关数据,这个值通过统计信息进行判断。(可以使用
ANALYZE TABLE employees;来更新优化器的统计信息) - 估计代价:
- 比较使用索引的成本和全表扫描的成本
- 如果使用普通索引,考虑回表的代价
执行器
先判断你有没有操作这个表的权限,然后才回去执行
以一个Sql为例:
1 | select * from T where ID = 10; # 假设表T没有索引 |
执行流程为:(假设表T没有索引)
- 调用执行引擎读取第一行,判断ID是否为10
- 读取下一行,重复,直到最后一行
- 返回结果集
如果有索引流程也差不多:
- 调用执行引擎:取满足条件的第一行
- 重复执行满足条件的下一行
- 返回结果集
MyISAM 与 Innodb
其他存储引擎可以使用show engines;查看
| 对比项 | MyISAM | Innodb |
|---|---|---|
| 外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 行表锁 | 表锁,即使操作一条数据也会锁住整个表 | 行锁,操作时可以只锁住某一行;适合高并发 |
| 缓存 | 只缓存索引,不缓存真实数据 | 不仅缓存索引,还会缓存真实数据;对内存要求高 |
| 表空间 | 小 | 大 |
| 关注点 | 性能 | 事务 |
Innodb独立表空间
Innodb中的每一个表,都会有一个.idb文件,这个文件就是一个独立表空间:
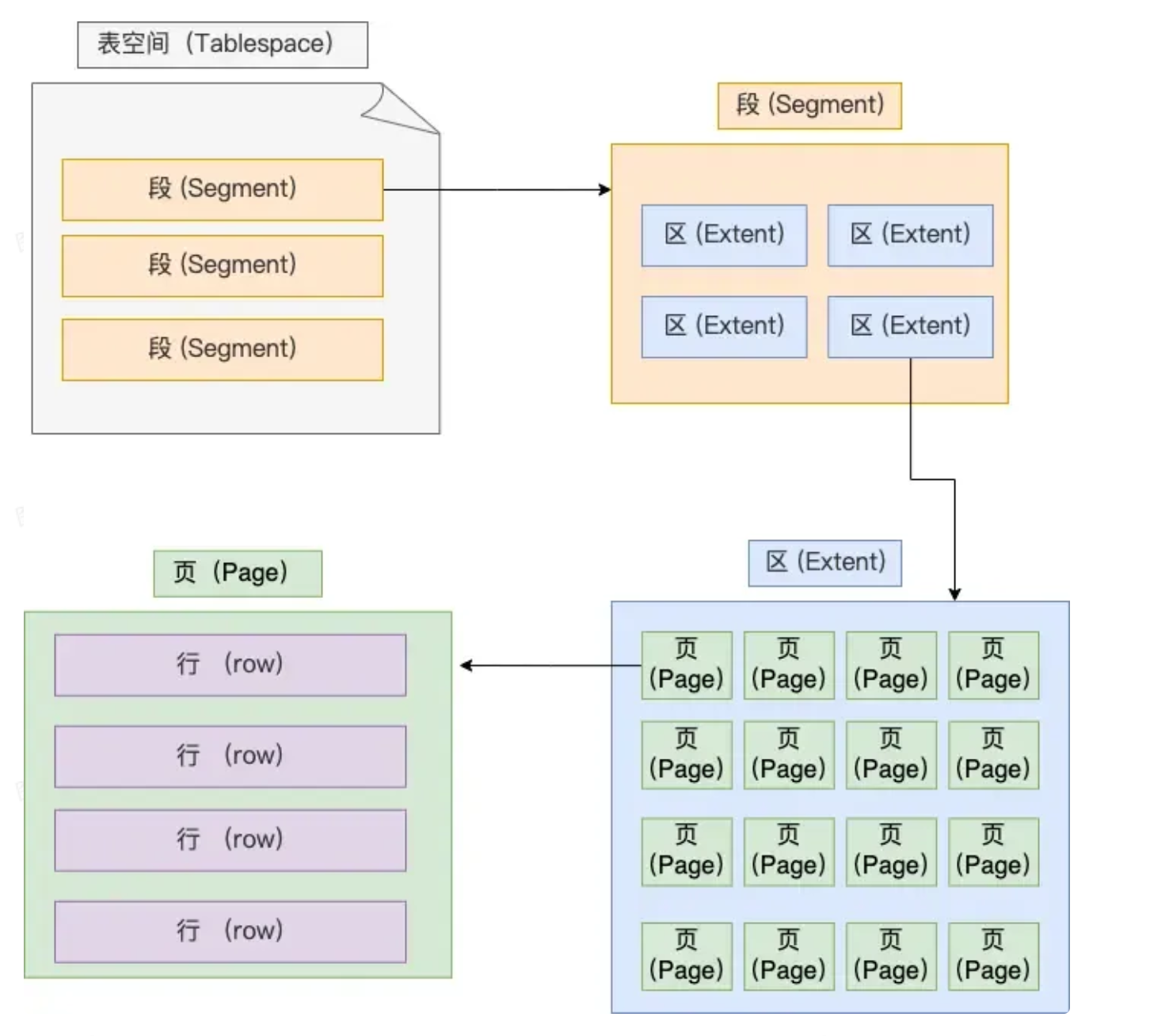
- 段(Segment):一个表空间会有很多段,常见的段有:
- 数据段:存放B+树的叶子节点
- 索引段:存放B+树的非叶子节点
- 回滚段:存放回滚数据的区的集合(MVCC使用)
- 区(Extent):数据量大会有分区,每一个分区大约1MB,一页16KB,大约一个区有64页,在物理存储时,尽量使B+树相邻的页放在相邻的物理位置上,提高顺序IO的性能。
- 页(Page):页是Innodb读取数据的最小单位,一页16kb(是OS的页的四倍)
- 行(Row):Innodb有四种行格式,Redundant(已淘汰)、Compact、Dynamic(5.7默认)、Compressed
Innodb如何存储Null值
数据行存储NULL值
这里重点介绍Compact,后面两个都是基于Compact的优化:
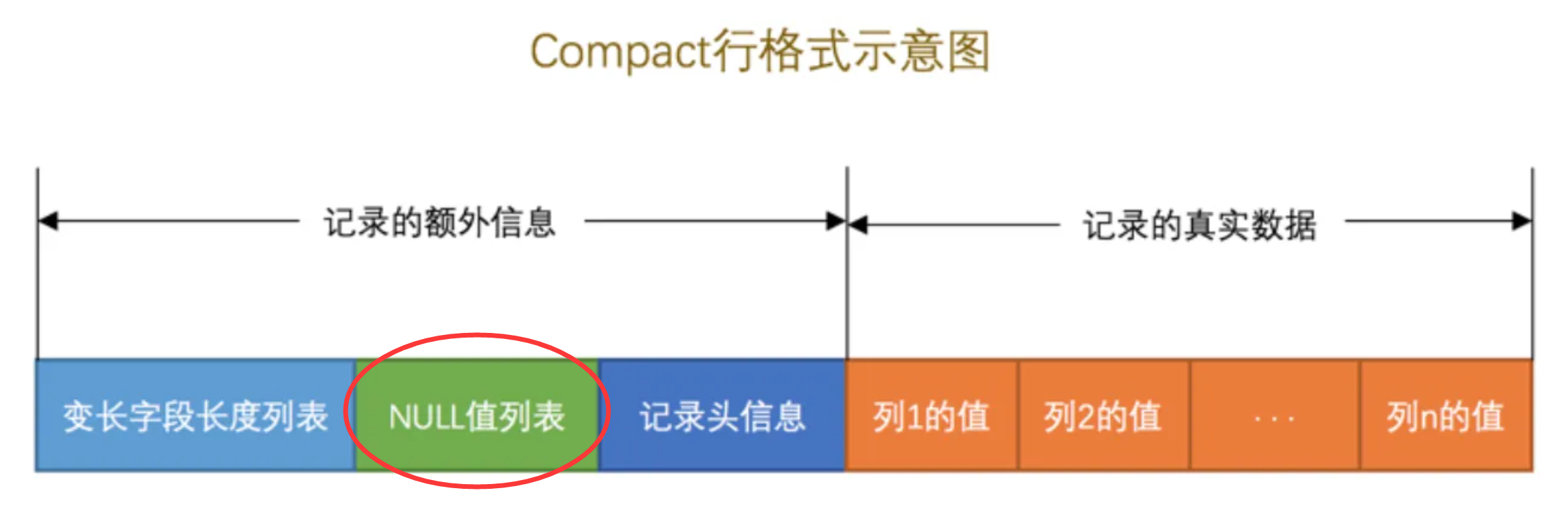
如果表中不是所有字段都设计为NOT NULL,那么就会存在这个额外信息NULL值列表
该值是一个bitmap,每一位代表对应列是否允许为null,并且该值占一个字节,如果允许为null的列存在9个,那么就会占用两个字节,以此类推。
行数据的额外字段中还有头信息中存储着mvcc的关键字段:
- DB_TRX_ID:创建或修改记录的事务ID
- DB_ROW_ID:隐藏主键
- DB_ROW_PTR:回滚指针
索引存储NULL值
主键索引是不允许为null的,普通索引是允许为null的,实际的结构中是这样的:
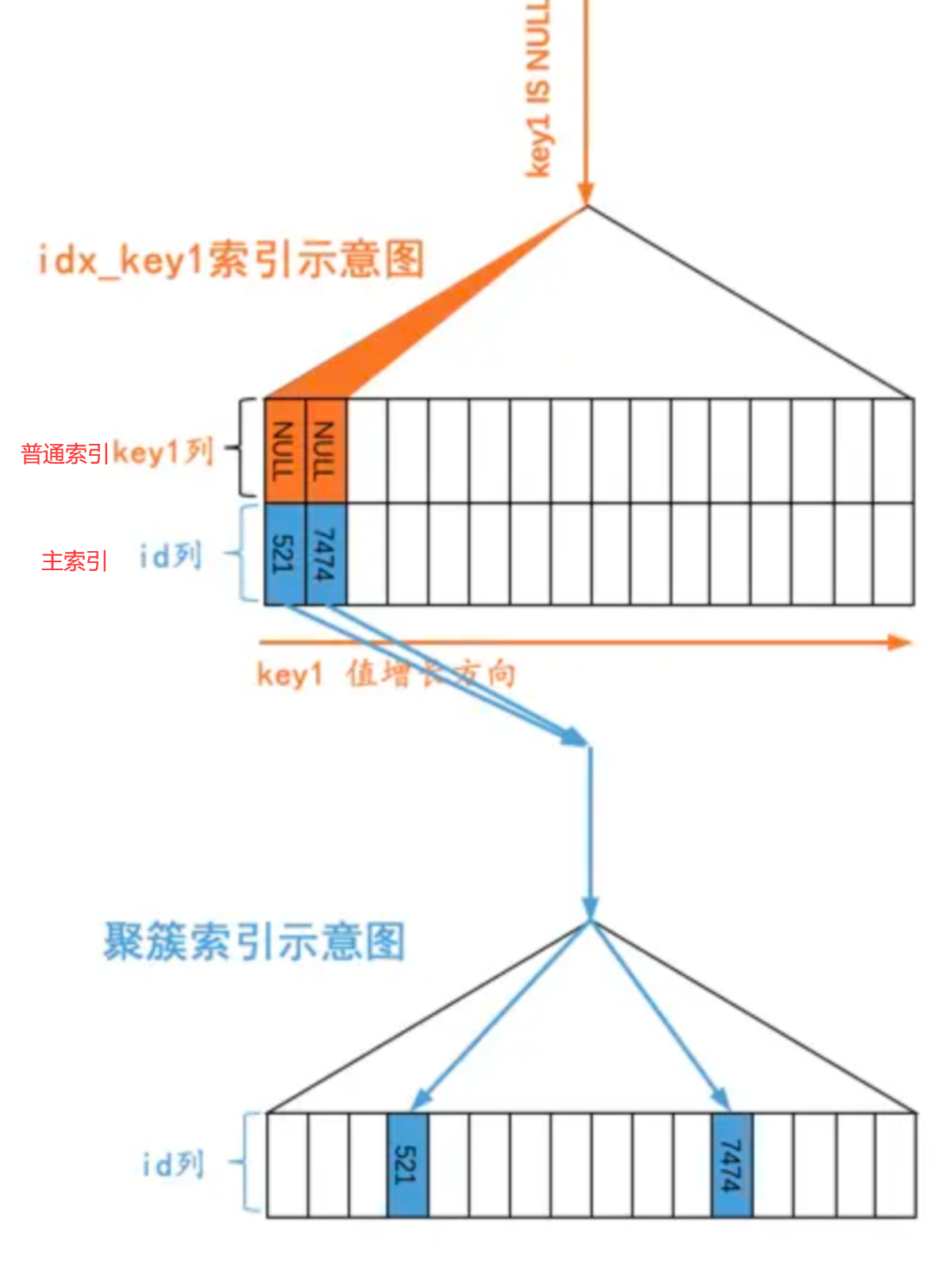
所有的NULL值会被认为是最小的值,被放在B+树的最左侧。
因此如果使用这样的sql语句去查询:
1 | select * from s1 where key1 is null -- key1是一个普通索引 |
mysql的执行逻辑是,在辅助索引树上找到null,挨个回表查询聚簇索引树。
因此:在我们使用is null或is not null时是否走索引是有待商榷的,在成本比较小的时候,会使用索引,成本大于查全表时,就不会走索引。
Explain
用来查看执行计划,这里给出官网资料
以一个简单的表为例,说明一下Explain的使用:
表temp:id为主键
| id | k |
|---|---|
| 1 | 2 |
1 | explain SELECT k FROM `temp` where id = 1; |
输出结果:
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | temp | (null) | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | (null) |
对各个字段进行说明:
其中的核心字段有:id、table、select_type、type、key、rows、Extra
id+table:通过这两个字段,可以判断查表的顺序select_type:查询语句的类型SIMPLE:简单查询,即不涉及UNION或子查询PRIMARY:主查询,复杂的SQL查询中最外层的查询SUBQUERY:子查询中的第一个SELECT语句UNION:UNION中的第二个及之后的SELECTDERIVED:派生表的查询,例如 FROM 子句中的子查询
partitions:该列显示的为分区表命中的分区情况。非分区表该字段为空(null)。type:表之间通过什么方式建立连接的,或者通过什么方式访问到数据的,下一节详细介绍possible_keys:可能会被使用的索引,实际不一定会使用,但是一般都以key为准key:实际使用的索引,如果为null,则没有使用索引,否则会显示你使用了哪些索引key_len:索引占用的字节数(下一节具体给出了各种类型占用的字节数)ref:表示where语句或者表连接中与索引比较的参数rows:优化器大概帮你估算出你执行这行函数所需要查询的行数。Filter:按条件查询的行数与总行数的比值,是一个百分数Extra:显示额外信息
type属性
从左到右,性能越来越差
1 | NULL > system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL |
NULL:能够在优化阶段分解查询语句,在执行阶段用不着再访问表或索引的查询1
2explain select 20*10; # 计算一个数字
explain select Max(id) from temp; # 查最大值,优化器自动去最边叶子结点取值,无需查表或索引SYSTEM:此表只有一行记录(等于系统表),这是const类型的特例,平时不大会出现,可以忽略。const表示使用主键或者唯一性索引进行等值查询,最多返回一条记录(性能好,推荐使用,因为只有一行,所以列值可以被优化器视为常量)1
2
3
4SELECT * FROM tbl_name WHERE primary_key=1;
SELECT * FROM tbl_name
WHERE primary_key_part1=1 AND primary_key_part2=2;eq_ref用于联表查询的情况,表连接使用到了主键或唯一键联合查询。1
2
3
4
5
6SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;ref表示使用非唯一性索引进行等值查询1
2
3
4
5
6
7
8SELECT * FROM ref_table WHERE key_column=expr;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;fulltext:使用FULLTEXT索引执行- 一种全文搜索的匹配方式,使用倒排索引
- 一张表只能存在一个
fulltext索引,但是可以有多个列 - 创建
FULLTEXT索引的列必须是CHAR、VARCHAR或TEXT数据类型
ref_or_null与ref相同,区别是可以包含null值的行index_merge表示查询使用了两个以上的索引,最后取交集或者并集,常见and,or的条件使用了不同的索引- 但是实际上由于要读取多个索引,性能可能大部分时间都不如
range
- 但是实际上由于要读取多个索引,性能可能大部分时间都不如
unique_subquery:会替换某些eq_ref子查询IN,一个索引查找功能,完全替代了子查询,以获得更好的效率1
value IN (SELECT primary_key FROM single_table WHERE some_expr)
index_subquery:同上,但是使用非唯一索引1
value IN (SELECT key_column FROM single_table WHERE some_expr)
range索引范围查询1
2
3
4
5
6
7
8
9
10
11SELECT * FROM tbl_name
WHERE key_column = 10;
SELECT * FROM tbl_name
WHERE key_column BETWEEN 10 and 20;
SELECT * FROM tbl_name
WHERE key_column IN (10,20,30);
SELECT * FROM tbl_name
WHERE key_part1 = 10 AND key_part2 IN (10,20,30);index使用索引进行全表扫描,通常比All快- 因为,索引文件通常比数据文件小,虽然
all和index都是读全表,但index是从索引中读取的,而all是从硬盘读的
- 因为,索引文件通常比数据文件小,虽然
ALL全表扫描,如果一个查询的type是All,并且表的数据量很大,那么请解决它!!!
key_len属性
每种类型所占的字节数如下:
| 类型 | 占用空间 |
|---|---|
| char(n) | n个字节 |
| varchar(n) | 2个字节存储变长字符串,如果是utf-8,则长度 3n + 2 |
| tinyint | 1个字节 |
| smallint | 2个字节 |
| int | 4个字节 |
| bigint | 8个字节 |
| date | 3个字节 |
| timestamp | 4个字节 |
| datetime | 8个字节 |
| 字段允许为NULL | 额外增加1个字节 |
extra属性
表示额外的扩展信息,常见的有:
Using where:使用where条件查询,但是没有使用索引Using index:用到了覆盖索引(即在索引上就查到了所需数据,无需二次回表查询),性能很好Using filesort:使用了外部排序,即排序的字段没有用到索引Using temporary:用到了临时表,如果ORDER BY或GROUP BY中的列没有索引,MySQL 可能会使用临时表来完成排序或分组操作Using join buffer:在进行表关联的时候,没有用到索引,使用了连接缓存区存储的临时结果Using index condition:使用到了索引下推Range:使用了范围扫描Fulltext search:使用了全文搜索
Mysql日志
Mysql三种日志:bin log、redo log、undo log
WAL(Write Ahead Logging):先写日志,再写磁盘
这里先做一个简单的介绍:
bin log:存放所有的更新操作redo log:配合bin log使用,也是存放所有更新操作undo log:负责事务的原子性,保证可以回滚
其中bin log属于Mysql Server层级别、redo log与undo log属于Innodb存储引擎级别
bin log与redo log
bin log与redo log会一起使用,bin log相当于总账本,而redo log想当于记录今天流水的账本,之后Mysql会将redo Log的内容写到bin log内(二阶段提交,下文会介绍)
注意:
bin log与redo log大小固定redo log可以设置为一组四个文件,每个文件大小为1GB
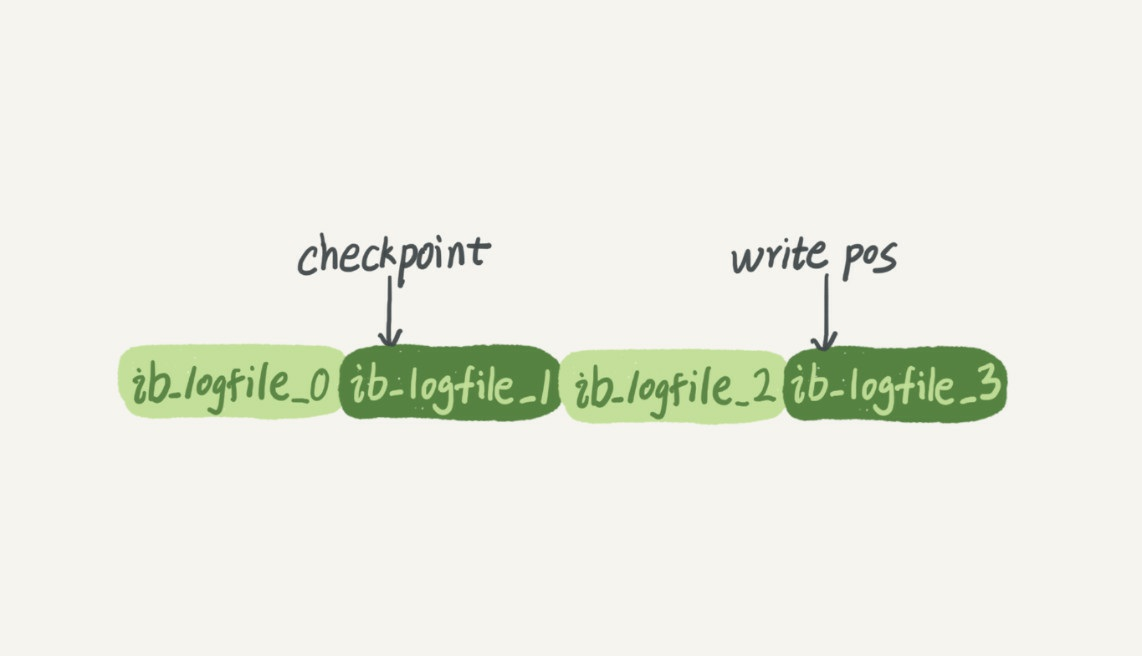
checkpoint:擦除的位置,checkpoint之前的数据将数据更新到数据文件
write pos:记录当前位置
两个指针都是循环写,即写到最后,又从头开始,循环使用这一部分空间
redo log实现了crash safe
crash safe:保证Mysql出现故障后,之前的数据也不会丢失的能力
bin log与redo log的基本作用
binlog(binary log):记录对数据库的修改操作(增删改、表结构修改),会校验事务的完整性(事务begin commit),也有备份点用于还原数据。主库可以使用binlog去备份出从库
redolog:WAL写前日志,在写入binlog数据前,先写入redolog,作为crash safe的安全保障手段,redolog可以恢复在断点时那些没能刷回磁盘的数据。
为什么要有redolog?
数据写入的过程是:先写入内存,缓存够一部分后,再刷脏页刷入磁盘中
内存的数据是易失的,如果发生断电,那么缓存的数据就会丢失掉,因此引入的解决办法是写前日志WAL
写入binlog前,先写redolog,这样可以减少数据丢失
redo log与 bin log的区别
三大区别:
- 级别不同:
redo log是InnoDB引擎特有的;binlog是MySQL的Server层实现的,所有引擎都可以使用。 - 存储内容不同:
redo log是物理日志,记录的是“在某个数据页上做了什么修改”;binlog是逻辑日志,记录的是这个语句的原始逻辑,比如“给ID=2这一行的c字段加1 ”。 - 写的方式不同:
redo log是循环写的,空间固定会用完;binlog是可以追加写入的。“追加写”是指binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
redo log 与 bin log 是如何联系的
它们有一个共同的数据字段,叫XID。
崩溃恢复的时候,会按顺序扫描redo log:
- 如果碰到既有
prepare、又有commit的redo log,就直接提交 - 如果碰到只有
prepare、而没有commit的redo log,就拿着XID去binlog找对应的事务
二阶段提交
由来:由于bin log 与 redo log属于不同的级别(bin log属于mysql
级别,而redo log与undo log属于Innodb级别),
为了保证数据同步,就得保证这两个文件一致,所以有了二阶段提交的概念
两状态提交:有两个状态
prepare与commit数据要进行更新时,会先写日志,再去更改数据,这个过程会先去写
redo log,将状态设置为prepare状态;(咔嚓~~~~如果此时断电,因为
binlog数据还没有写入,所以会丢弃redo log中的prepare这部分数据,并且进行回滚)然后再写
bin log;(咔嚓~~~~如果此时断电,因为
bin log已经写入,判断redo log中也存在,只不过状态是prepare,依然可以继续进行)提交事务,将状态改为
commit
二阶段提交过程:(这个图也能帮我们了解清楚,一条更新语句的执行过程)
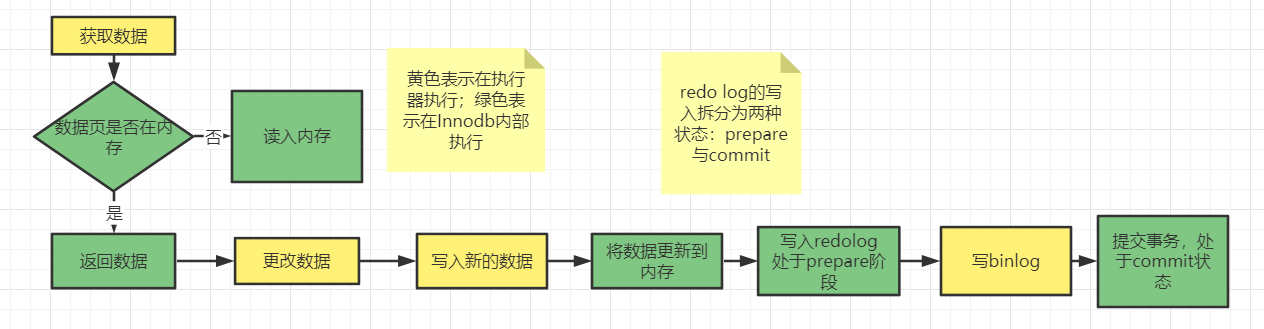
调换顺序存在的问题:
情况1:假设先写
redo log再写bin log:假如写完
redo log后mysql崩溃重启,由于写了redo log,所以会恢复这个数据,但是bin log没有写入,所以如果之后使用bin log恢复数据,就会与原库不同情况2:假设先写
bin log再写redo log:假如写完
bin log后mysql崩溃重启,由于还没写redo log,崩溃后恢复,两个文件不一致,判断此事务无效;虽然原库虽然会无此数据,但使用bin log恢复后,新的数据与原库不同;
binlog日志格式
binlog 日志有三种格式,可以通过binlog_format参数指定。
- statement
- row
- mixed
他们之间的区别是:
比如现在这样的一条语句update T set update_time=now() where id=1
statement:直接存储,
update T set update_time=now() where id=1,但是对于**now()、UUID()**操作不友好,获取当前的时间,这种操作再次执行时与原本的操作不会一致。row:会记录原始的数据值,不能直接查看,需要借助解析binlog的工具,比如
update_time=now()变成了具体的时间update_time=1627112756247,但是这种方式存储的数据量就比较大mixed是一种折中方案:MySQL 会判断这条
SQL语句是否可能引起数据不一致,如果是,就用row格式,否则就用statement格式
在不同场景下,可能会使用不同的日志格式:
- 要求数据一致性100%保证,使用ROW格式,比如canal
- 大部分的主从同步场景:
- MySQL 5.7之前:STATEMENT格式
- MySQL 5.7及以后:MIXED格式
双一规则
二阶段提交中,redo log和bin log可以保证数据的不丢失。
但是bin log和 redo log是如何做到写入数据的?如果写入的情况出现丢失怎么办?
简单来说
简单的来说双一规则就是两个参数,规定了刷盘的时机。
一个更新操作从开始到提交需要经过:
begin- 查数据,然后更新数据,更新数据的写入操作可能会写入到
change buffer内(这个此处不予深入讨论) - 先写入到
redolog buffer,之后会写入到page cache - 写入
binlog buffer,之后会写入到page cache commit- 再次写入到
redolog buffer,之后写入到page cache
我们要注意的是:
写入binlog和redolog并不是直接就能写进去的,他们在内存中都有buffer,每次想要持久化时,需要先write进入page cache(这是文件系统的缓存),然后再fsync真正的从内存刷回到磁盘中
write操作:一般每次事务都会writefsync操作:不一定,可以设置
那么执行多少次事务,才去进行一次
write与fsync操作呢?
双一,一次write一次fsync,发生一次事务,就刷一次盘,这是最安全的方式。
binlog 写入磁盘规则
binlog是如何写入磁盘的?
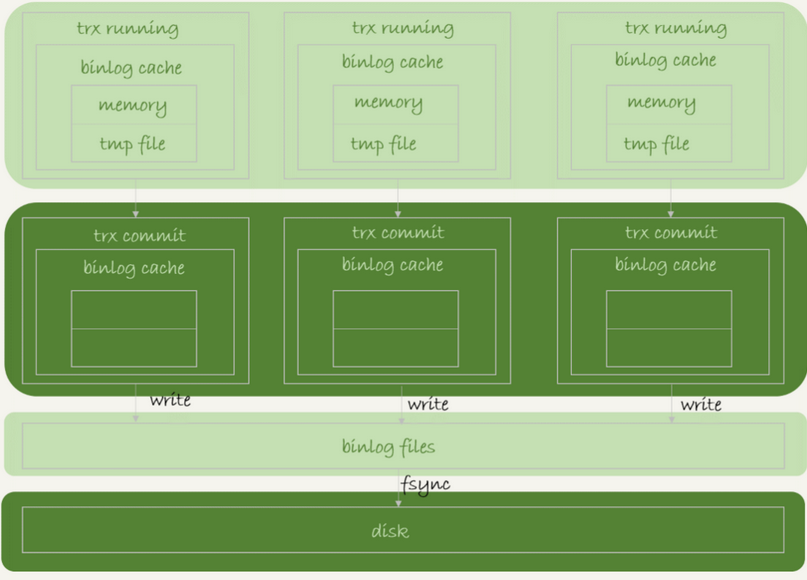
binlog有缓存机制cache,如图所示:
- 每个线程都有自己的
binlog cache - 每个线程都需要将结果写入到唯一的
binlog文件中 - 每个事务提交后会有两个过程:
write:将cache的数据wirte进bin log文件fsync:将binlog文件写入磁盘
Mysql提供了参数sync_binlog对事务的write和fsync操作进行控制:
每次提交事务,参数配置不同,fsync的次数也不同
sync_binlog=0:只write,不fsyncsync_binlog=1:每一次write进行一次fsyncsync_binlog=N:每N次write进行一次fsync
一般会将这个参数设置为“1”,双一规则的其中一个1就是这个。
redolog 写入磁盘规则
redolog在写入磁盘前,会先写入内存

- 写入
redolog buffer中,也就是内存中 - 写入到磁盘中,存于page cahce中,但是没有持久化(和 binlog一样 只是write,没有fsync)
- 持久化到磁盘中
同样,mysql提供参数innodb_flush_log_at_trx_commit,设置为几,就在几次事务提交后持久化到磁盘
这就是另外一个“1”。
因此,两阶段提交的过程涉及到两次刷盘的过程:redolog刷盘,binlog 刷盘
redo log组提交机制
如果每次都刷两次盘,那么也太吃性能了。
组提交机制就是为了提高性能的:
日志逻辑都有一个序列号 LSN
用于对应redo log的一个个写入点,LSN是单调递增的,对应redo log的一个个写入点,每一个写入长度为length的redo log,LSN的值就会加上length
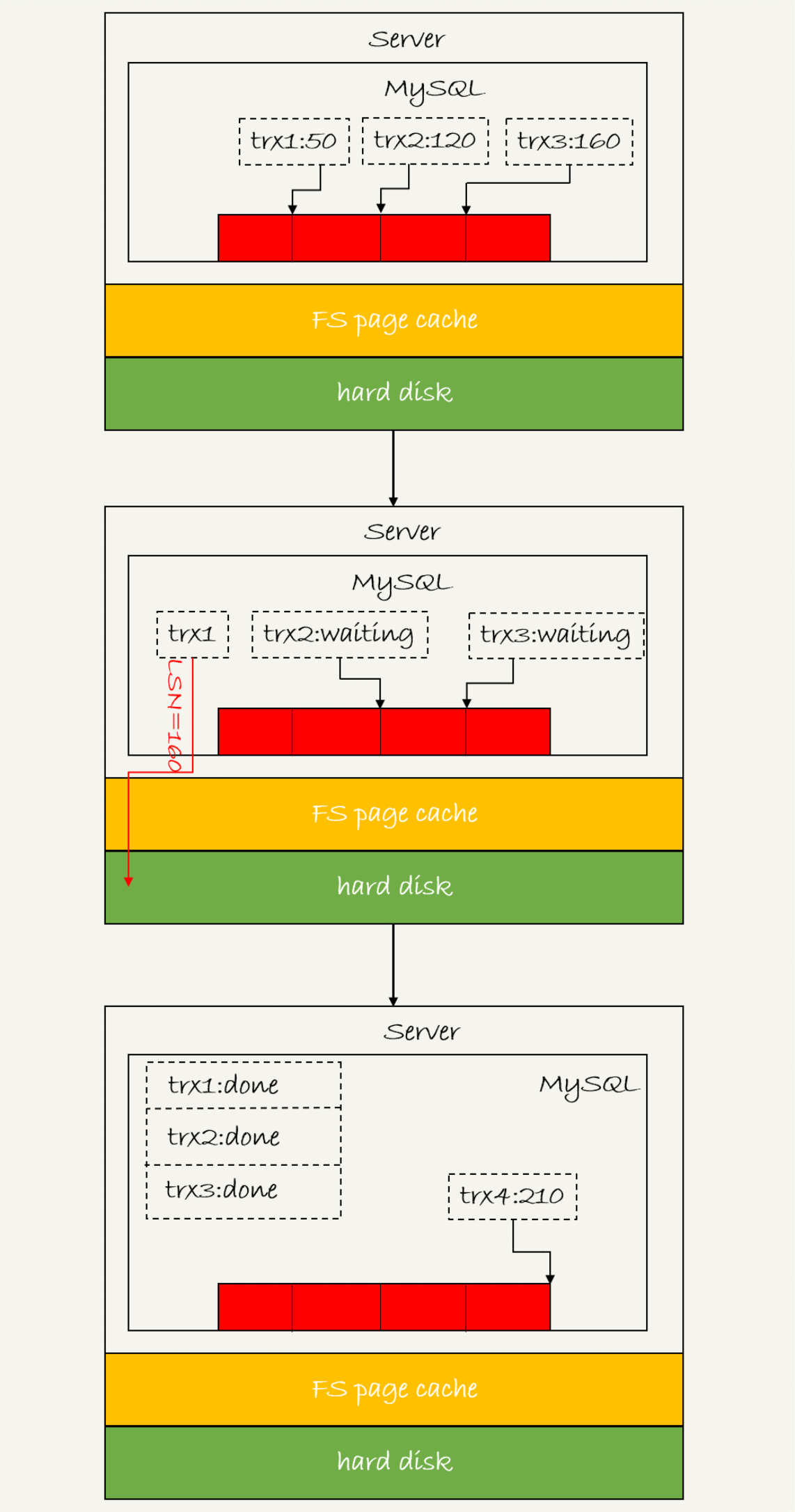
如图所示,有三个事务,每个事务有一个LSN序列号,现在要将trx1写入磁盘,那么就判断LSN值为160,那么LSN小于等于160的redo log,都会被redo log都会被持久化到磁盘中
这就是所谓的组提交,组越晚提交,提交的数量也就越多,节省IO时间
因此,加上write和fsync的话,二阶段提交的真实过程就是:
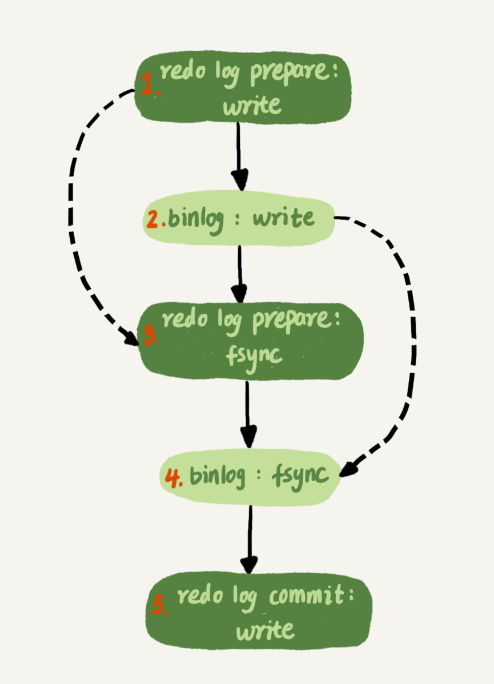
- write
redo log,进入prepare状态 - write
bin log - fsync
redo log - fsync
bin log - write
redo log,进入commit状态
一般来说,也是将数据库设置为双一设置。
在什么时候设置为非双一呢?
- 业务高峰期,如果有预支的高峰期,会改为非双一
- 备库延迟,让备库赶上主库
- 备库恢复主库副本
- 批量导入数据的时候
崩溃的判断规则
redo log崩溃恢复时的判断规则:
- 如果
redo log里面的事务是完整的(即有了commit标识),则直接提交; - 如果
redo log里面的事务只有完整的prepare,则判断对应的事务binlog是否存在并完整:- 如果是,则提交事务
- 否则,回滚事务
bin log如何保证完整性:
一个事务的binlog是有完整格式的:
statement格式的binlog,最后会有COMMIT;row格式的binlog,最后会有一个XID event- MySQL 5.6.2版本以后,还引入了
binlog-checksum参数,用来验证binlog内容的正确性
Mysql索引
B树、B+树
由来
每一种数据结构都是为了解决一种问题而提出的,B+树也不例外
我们知道数据库存放数据,目的是为了查询,而查询当然越快越好
索引就是为了提高查询速度而提出的(下文会介绍索引)
索引查询的原理大致就是K-V映射,这我们立刻就能想到哈希,但是哈希存在一些问题:哈希表需要全部放入内存、哈希表不能范围查询、哈希碰撞严重影响效率
于是提出使用树来进行存储,树有很多种,最常见的就是二叉树,为了加快速度,使用了二叉搜索树BST
但是遇到一些递增或递减的数据,会使BST的效率大大降低,于是提出了自平衡树AVL,但是AVL树便于查询,插入的效率会很低,于是又有了红黑树
红黑树确实实现了搜索与插入的平衡,但是红黑树依然不能克服二叉树存在的问题——随着插入的数据越多,树的高度越高
于是提出了B树一个自平衡的多叉排序树
总之,经历了哈希表、二叉树、BST、AVL、红黑树这些阶段,终于提出了B树
B树
首先了解**平衡二叉树,平衡二叉树每一个结点都维护了一个高度,一个节点是否是平衡的,取决于它的左孩子与右孩子高度的差值是否大于1**
其次就是要知道二叉排序树,二叉排序树节点的左节点小于自身,右节点大于自身。
但是二叉树有弊端,最坏情况下需要遍历树的高度,二叉树很容易达到一个很深的高度,高度越高,效率越低。
所以B树由此影响,提出了平衡多路查找树(一个多叉树结构的平衡排序树)
(注意:B树与B-树是同一个概念)
B树是这么一棵树:(五个规则)
- 根节点至少有两个节点(或者说根节点至少有一个元素)
- 中间节点包含 k-1 个元素和k个孩子,其中 m/2 <= k <= m(m是最多有几个叉)
- 叶子结点都包含k-1个元素,其中 m/2 <= k <= m
- 所有叶子节点都在同一层
- 每个节点中的元素从大到小排列
B树中存放的元素是
key-value值
B+树
B+树在B树的基础上,有着如下改变:
- B+树有两种类型的节点:内部结点(也称索引结点)和叶子结点。
- 内部节点就是非叶子节点,内部节点不存储数据,只存储索引,数据都存储在叶子节点。
- 内部结点中的key都按照从小到大的顺序排列,对于内部结点中的一个key,左树中的所有key都小于它,右子树中的key都大于等于它。叶子结点中的记录也按照key的大小排列。
- 每个叶子结点都存有相邻叶子结点的指针,叶子结点本身依关键字的大小自小而大顺序链接。(即叶子结点为一个链表)
- 父节点存有右孩子的第一个元素的索引
B+树的添加删除操作,可以看此篇blog,图文描述特别清楚,可以深刻理解B树与B+树的结构
为什么B+树很适合磁盘的存储逻辑?
- 磁盘的读取单位是页(4KB),B+树的设计中为了配合磁盘,每一个节点的大小就是N倍页的大小(Innodb的一页16KB,是4倍的OS的页)
- B+树的树高很小,为了减少IO次数
- 磁盘顺序IO访问的效率会更高,B+树很适合范围查询
B树与B+树适用的场景
B+树的内部节点只存储索引,因此树高会低很多,适合范围查询。
B树内部节点存储数据与索引,可以做专门的优化,对于访问频次高的数据可以调整到更靠近根节点的位置
Mysql三层B+树可以存储多少数据?
mysql使用innodb存储引擎,每一个节点都是一页,每一页存放16kb的数据,叶子节点存储数据,非叶子节点只存储索引
现在我们规定以下前提:
- 一页大小:16kb
- 非叶子节点的主键大小:假设为bigint类型,8byte
- 非叶子节点的页指针大小:6byte
- 叶子节点每一条记录的的大小:假设为1kb
第一层中的索引数量:
最少:2条(起码有两条才能有三层b+树)
最多:
16 * 1024 / (6 + 8) = 1,170,每个索引需要存放索引(8byte)和的页指针(6byte)
第二层中的索引数量:
- 最少:
1,170 + 1 = 1171(第二层起码有一页是满的,第二页起码得有1条) - 最多:
1,170 * 1,170 = 1,368,900(一页最多有1170条,最多有1170页)
第三层叶子结点的记录数:
- 最少:
1171 * 16 + 1 = 18,737(在三层结构下,1w条数据的查询和2kw条数据的查询开销是一样的) - 最多:
1,368,900 * (16kb / 1kb) = 21,902,400(每条数据1kb,那么每页能存16条数据,最后大约可以存储2kw条数据)
这是假设一行数据在1kb的情况下,如果是256byte,那么基本会扩大4倍,即约8kw。
结论:在前提一页为16kb、索引8byte、非叶子节点野指针6byte的情况下
每行数据大小为1kb,那么三层b+树数据总量在2kw左右
在此前提下,四层B+树呢?
第三层索引数量:
- 最多:
1,368,900 * 1170 = 1,601,613,000
叶子结点记录数:
- 最多:
1,601,613,000 * 16 = 25,625,808,000(约为200亿数据)
结论:千万级别一般是3层,十亿+级别一般是四层
MyISAM与Innodb不同的索引结构
索引的分类
- 单列索引
- 主键索引:唯一且非空
- 唯一索引
- 普通索引
- 联合索引:使用多个键构成的索引
- 全文索引:只能在CHAR、VARCHAR、TEXT类型字段上使用全文索引
对于这两个mysql引擎,他们实现的方式有所区别
MyISAM中的索引
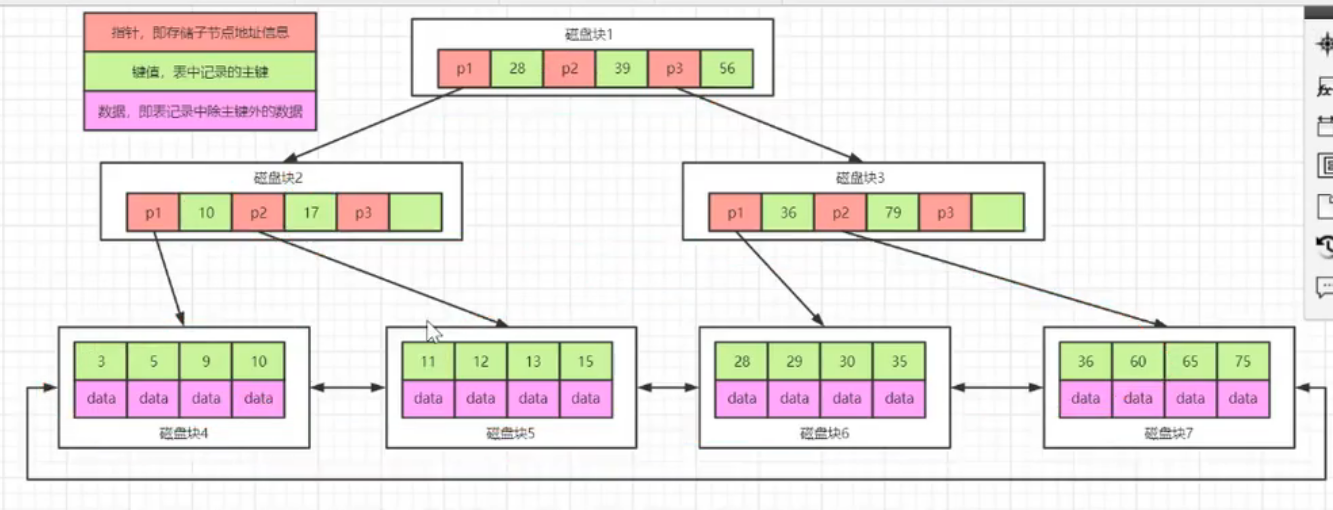
B+树我们知道,有内部结点与外部结点,内部结点就是索引,外部结点才会存放数据真正的值
在MyISAM中,如下图,索引一层一层,最后的叶子结点存放的数据是真实数据的地址,注意,存放的是数据的地址!!
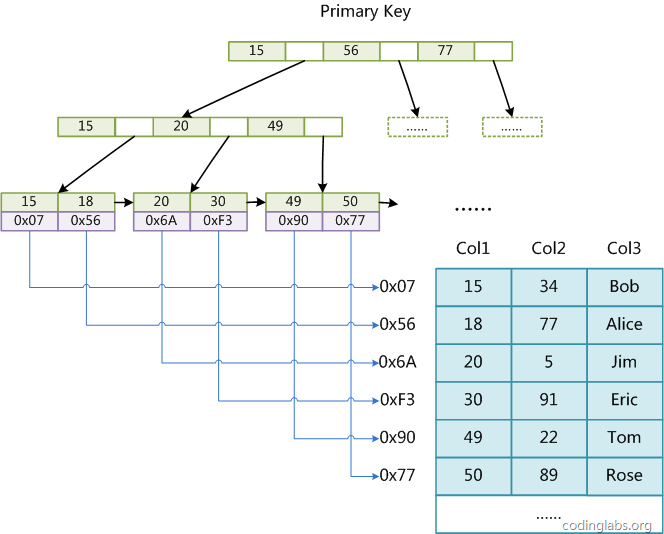
在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复
Innodb中的索引
最大的区别就是B+树叶子结点存放的是数据,区别与MyISAM中存放的数据的地址
表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。
这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引

这种索引叶节点包含了完整的数据记录。这种索引叫做聚集索引,相对而言,MyISAM中的索引就称为非聚集索引
聚集索引的特点:必须要按主键聚集,而且聚集索引只能有一个(Innodb有一个聚集索引与多个非聚集索引)
因此Innodb必须有主键,而MyISAM可以没有主键
如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键(唯一键)
如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段rowid长度为6个字节,类型为长整形
总结:
主键 -> 唯一键 -> 6个字节的rowid
除此外,在Innodb的辅助索引,与MyISAM也有区别,MyISAM的辅助索引结构与主索引完全一致,只是可以重复这一点区别
在Innodb中,InnoDB的辅助索引data域存储相应记录主键的值而不是地址
即辅助索引构建的B+树的叶子结点,存放的不是地址,而是主键的值
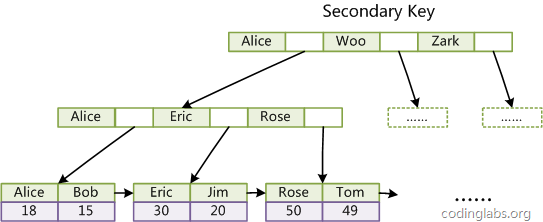
聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。(这也是为什么要用聚集索引的原因)
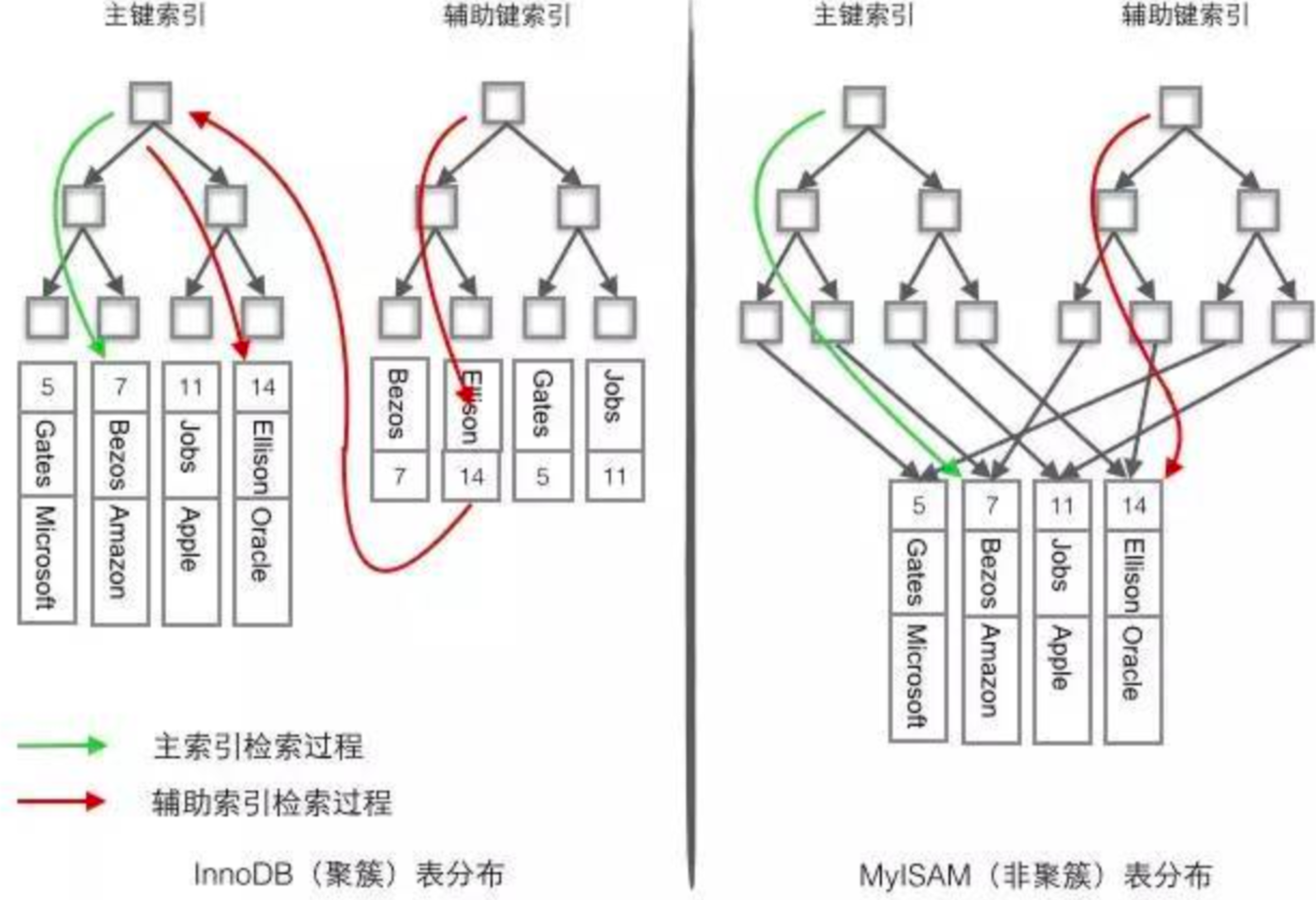
聚集索引和辅助索引
- Innodb:
- 主键索引是聚集索引,所谓聚集索引,是指会按照主索引去创建一颗B+树,此B+树的叶子节点存储的是数据行(所以会出现回表的现象)
- 辅助索引的叶子节点存储的是主键的值
- MyISAM是非聚集索引:
- 主键索引是非聚集索引
- 辅助索引和主键索引一样,叶子节点存储的都是数据行的地址
聚集索引的好处与坏处
特点:将数据存储在叶子节点上,这样找到了最终的索引,也就找到了数据(会比非聚集索引少一次IO)
好处:比非聚集索引少一次IO,会更快一些
坏处:首先是会有回表现象的发生,其次是对于修改删除的操作需要更新索引树,开销增大
为什么Innodb的辅助索引的叶子节点存储主键值,而不是存储地址?这样不就没有回表问题了吗?
MyISAM的实现中,辅助索引存储的就是实际的地址,如果Innodb也设计为这样,虽然不会有回表问题,但会有更大的维护成本:
数据是会不断变化的,它的地址也可能发生变化,比如:页分裂或者页合并
什么是页分裂?
在插入新的数据时,当前页可能已满,那么就需要新的一页去存储对应的数据。
一般来说,会将满的一页的数据,分成两页存储,各存储一半。
页分裂有可能会导致递归分裂
从结构而来的结论
使用占内存小的字段作为主键:因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大
不用非单调的字段作为主键:因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择
索引不是越多越好
不要对经常变动的数据加索引
总结
| 区别项 | MyISAM | Innodb |
|---|---|---|
| 数据结构 | B+树 | B+树 |
| 外部节点存放 | 数据的地址 | 数据本身 |
| 辅助索引与主索引的区别 | 结构相同;主索引不允许重复 | 结构不同;辅助索引外部节点存放的是主索引的值 |
回表
假设有一个表,有id name age gender四个字段,其中id为主键,name为普通索引
现在有这么一个SQL
1 | select * from table where name = zhangsan |
Mysql会如何去进行搜索?
首先name是一个普通索引,也会建立一个B+树,但是这个B+树是辅助索引,它的叶节点只会存放主键的值,所以mysql从name会查到主键id,进而才会查到整个记录(检索了2棵B+树)
这种现象就叫做回表
回表:根据普通索引查询到聚簇索引的key值后,再根据key值再获取到记录
索引覆盖
再有一个sql语句
1 | select id,name from table where name = zhangsan |
如何搜索?
根据辅助索引存储的为聚集索引的值这一点,我们可以知道,通过普通索引name去查询聚集索引id和name,只需要查询一棵树,这种现象较索引覆盖(查一棵B+树)
索引覆盖:
当只查询普通索引和聚集索引的内容时,只需要查普通索引即可的现象
最左匹配
现在对id name age gender四个字段,设置其中id为主键,<name,age>为索引列
有下列sql语句,mysql执行时,对哪种sql会使用索引?
1 | select * from table where name = ? and age = ? # 会 |
解释:
其中1与2是因为mysql有优化器,会将sql语句自动调整顺序,即2在执行时是按1执行的
为什么3没使用索引,而4使用了呢?
这是因为我们设置联合索引是<name,age>,其中name为左,所以会,这种现象叫最左匹配
满足最左匹配,在读取时会使用索引,更加高效!
联合索引什么样的查询会用到索引(深入最左匹配)
还是此篇blog,强烈建议仔细阅读此篇blog,本文主要对此文进行了总结,原文有更多示例与论证,对不同情况下的查询都进行了分析,此处做一个总结:
设有titles表的主索引为<emp_no, title, from_date>(联合索引:有多个列一起组合为一个索引)
全列匹配:对于主索引的每一列都进行精确匹配(这里精确匹配指“=”或“IN”匹配)例如搜索条件为
WHERE emp_no='10001' AND title='Senior Engineer' AND from_date='1986-06-26',每一个都给了一个精确的值- 这时会用到索引
- (而且mysql查询优化器会自动对查询的顺序进行优化)
最左前缀匹配:当查询条件精确匹配索引的左边连续一个或几个列时,如
<emp_no>或<emp_no, title>时- 会用到索引
- 但是只会用一部分,此处就只用了
<emp_no>的索引(最左)
查询条件用到了索引中列的精确匹配,但是中间某个条件未提供:例如查询的索引是
<emp_no, from_date>,此时和情况2相同,也只会使用左边的索引;区别是:由于title不存在而无法和左前缀连接,因此需要对结果进行扫描过滤from_date- 可以使用添加辅助索引的方法,使mysql使用上
from_date这个索引,增快效率 - 如果缺少的中间索引(此例中的
title)的值种类不多的时,可以使用IN来进行填坑
- 可以使用添加辅助索引的方法,使mysql使用上
查询条件没有指定索引的第一列:没有指定最左索引,例如
WHERE from_date='1986-06-26':- 没有联系到最左前缀,不会使用索引
匹配某列的前缀字符串:例如
WHERE emp_no='10001' AND title LIKE 'Senior%',如果通配符%不出现在开头,则可以用到索引,但根据具体情况不同可能只会用其中一个前缀范围查询:对某一列进行范围查询,例如
WHERE emp_no < '10010' and title='Senior Engineer'- 范围列可以用到索引(必须是最左前缀),但是范围列后面的列无法用到索引。
- 同时,索引最多用于一个范围列,因此如果查询条件中有两个范围列则无法全用到索引。
查询条件中含有函数或表达式:使用函数或表达式,例如
WHERE emp_no='10001' AND left(title, 6)='Senior'- 不会使用索引
- 因此在写查询语句时尽量避免表达式出现在查询中,而是先手工私下代数运算,转换为无表达式的查询语句
like”%xxx”一定不会走索引吗?
也不一定,如果能触发索引覆盖,还是会走索引的,比如:
1 | create table `user`( |
这种情况下会走索引,而且查询计划是index也就是使用索引的全表查询(会查询整个name的辅助索引的B+树)
虽然效率也不是很高,但要比走主键索引快(因为不需要回表)
索引下推
5.7版本后退出的新功能,首先要知道mysql大致分为三层:
- client:交互
- server:服务
- 存储引擎:存储
对于SQL
1 | select * from table where name = ? and age = ? |
没有索引下推之前:首先根据name从存储引擎获取符合规则的数据,然后在server层用age进行过滤筛选
有索引下推后:直接用两个索引从存储引擎获取数据(省去了server层与存储引擎交互的过程)
索引优化
给合适的列建立索引
索引可以加快查询的速度,但是并不是每次查询都要建立索引
索引虽然加快了查询速度,但索引也是有代价的:索引文件本身要消耗存储空间
两种情况,不建议建立索引:
- 表的记录较少,在一两千条之内,以2000作为分界线,2000条以上再建立索引
- 索引的选择性较低
选择性:
选择性(Selectivity),取值范围为(0, 1],是指不重复的索引值(也叫基数,Cardinality)与表记录数(#T)的比值:
Index Selectivity = Cardinality / #T
选择性越高的索引价值越大
前缀索引
用列的前缀代替整个列作为索引key,当前缀长度合适时,可以做到既使得前缀索引的选择性接近全列索引,同时因为索引key变短而减少了索引文件的大小和维护开销
兼顾了性能与开销
永远使用与业务无关的自增字段作为主键
Innodb聚集索引,会把数据记录记录在一个叶子结点上
如果使用自增字段,那么他会按序排放,没有额外的操作,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)
如果不使用自增字段,B+树本身维护自己的有序性,就有一定的开销,频繁的移动、分页操作造成了大量的碎片
唯一索引&普通索引
唯一索引与普通索引,如果不考虑业务的要求(比如说,不要求键唯一),那么这两个索引谁更快呢 ?
比如这个例子:
1 | select id from T where k=5; # id是主键 |
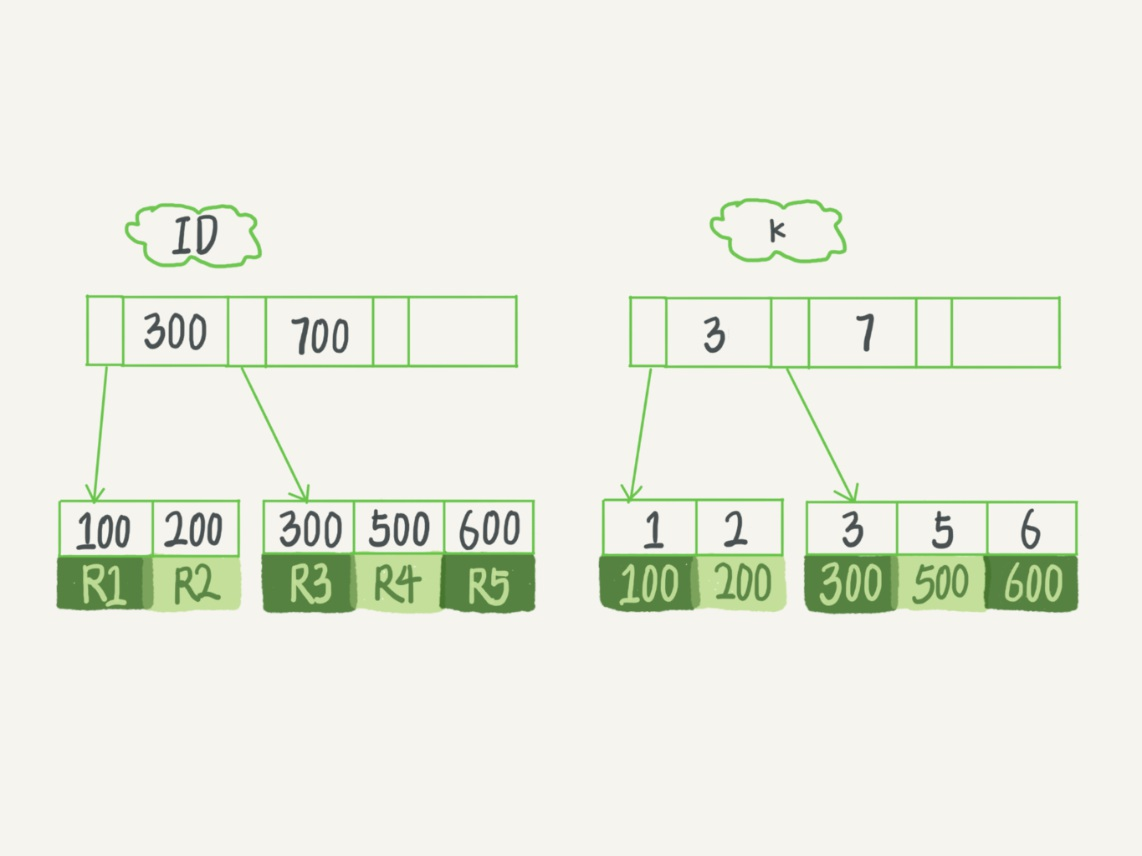
查询操作
找k为5的记录
- 如果
k为普通索引:查询到第一个满足k=5的记录后,继续向下找,直到第一个不满足k=5条件的记录 - 如果
k为唯一索引:查询到第一个满足k=5的记录后,就停止查找。
好像唯一索引要快一点?但其实速度都差不多
Mysql的读是按页读的,每页16kb,所以在把对应的页调入内存后,普通索引多的那些判断对于CPU来说,九牛一毛,所以性能差不多
更新操作
先说结论,普通索引要快一点(由于change buffer)
change buffer
操作磁盘,是最影响速度的一步,所以所有的缓存都是为了统一的进行与磁盘的操作
所以change buffer作用如下:在不影响数据一致性的前提下,将Innodb的更新操作缓存在change buffer中,之后再将数据写入磁盘
什么条件下会使用change buffer?
对于唯一索引来说,更新操作都得首先判断是否重复,所以唯一索引必须先从内存中读出数据,已经读到内存中了,也就没必要使用change buffer了
这里回到上一节的那个问题,更新操作
第一种情况:要更新的目标在内存中
- 唯一索引:找到记录,判断是否重复,更新
- 普通索引:找到记录,更新
这种情况下,也没什么区别
第二种情况:要更新的目标在磁盘中
- 唯一索引:从磁盘中将数据读入到内存中,然后判断是否重复,更新
- 普通索引:找到记录后,更新到change buffer
显然,普通索引完胜
change buffer 与 redo log buffer的区别
这两个区域都是为了提高效率的,而且功能好像也有点类似,这里做一个区分:
buffer pool代表内存,change buffer 就在其中
system table 表示系统表空间,data表示数据表空间
执行如下操作:
1 | insert into t(id,k) values(id1,k1),(id2,k2); |
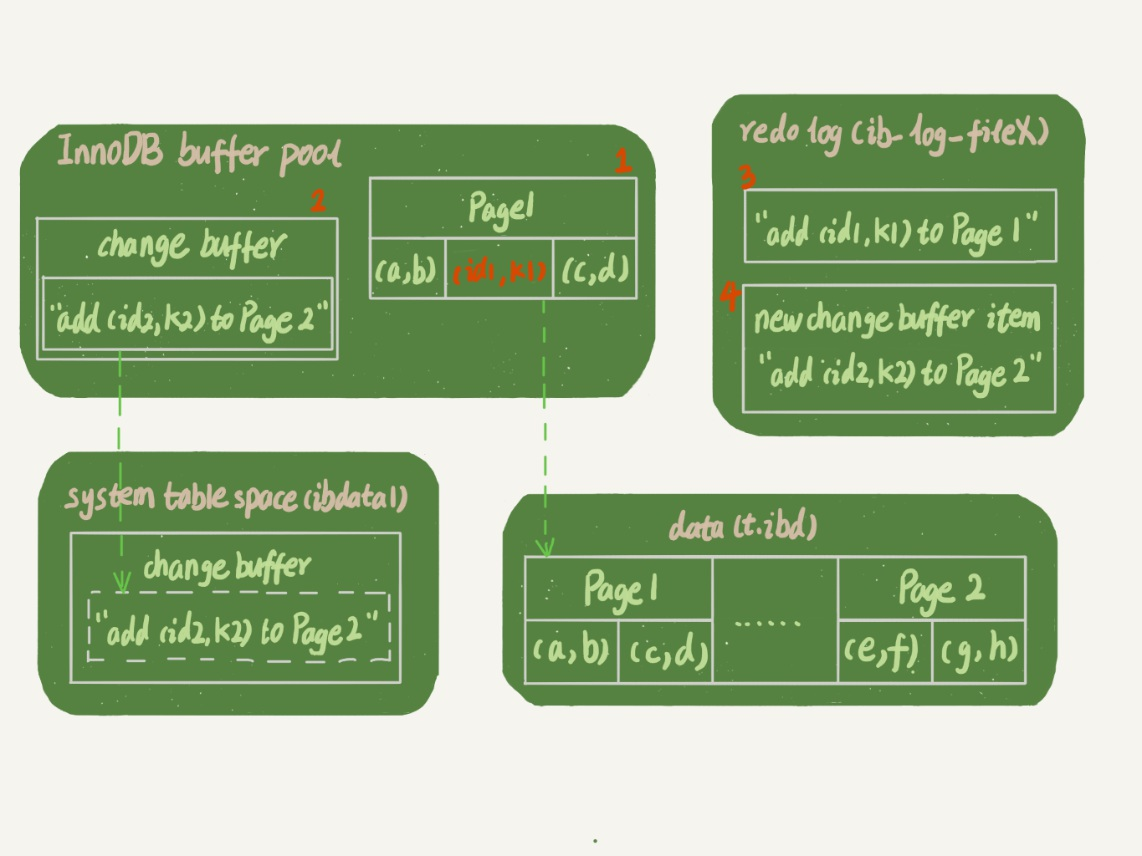
- page 1 在内存中 ,直接插入
- page 2 不在内存,就更新内存的change buffer
- 将上述记录写到
redo log内
如果是读操作:
1 | select * from t where k in (k1, k2) |
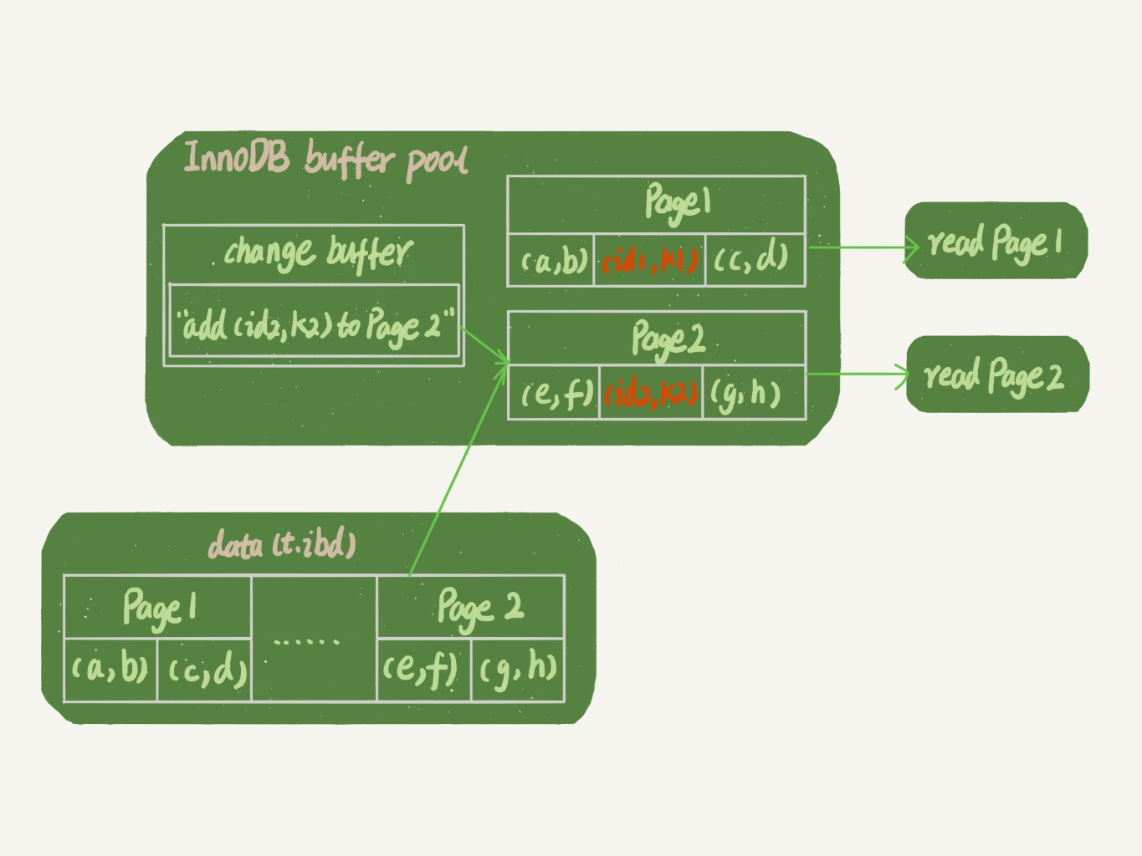
- page 1 在内存,直接读出来
- page 2 不在内存, 从内存读出,然后应用change buffer的操作,返回结果
结论
- 如果没有业务的需要,建议使用普通索引:普通索引的写速度是要大于唯一索引的,
change buffer节省随机读磁盘的IO损耗redo log节省随机写磁盘的IO损耗
索引的其他问题
1、 mysql的数据存在哪里
存放在磁盘中(毫无疑问)
2、 Mysql在磁盘是如何读取数据的
按页读取,页由OS确定,一般为4K或8K,只能按页读取,也就是只能读4的整数倍
mysql的Innodb引擎在读取时每次读取16kb
3、 索引存放在哪里
存放在磁盘中,启动mysql后,索引会被加载到内存中(为了防止断电后重新生成索引)
4、 使用哈希存的利弊:
利:O(1)级别查询速度
弊(三点):1. 哈希冲突会导致查询速度下降;2. 哈希表需要全部放在内存中使用,耗内存量大;3. 不支持范围查询,如果要范围查询需要对整个哈希表进行遍历
在mysql数据库中:memory引擎使用Hash、Innodb引擎自适应(由引擎来选择使用Hash还是树)
5、 为什么使用B+树而不是红黑树
红黑树虽然实现了查询与插入的近似相同,但是树高依然不能限制(这是由于红黑树依然是一棵二叉树)
随着数据的大量插入,树的高度会使整个查询的效率变慢
而B+树会大大降低树高
6、 为什么使用B+而不是B树
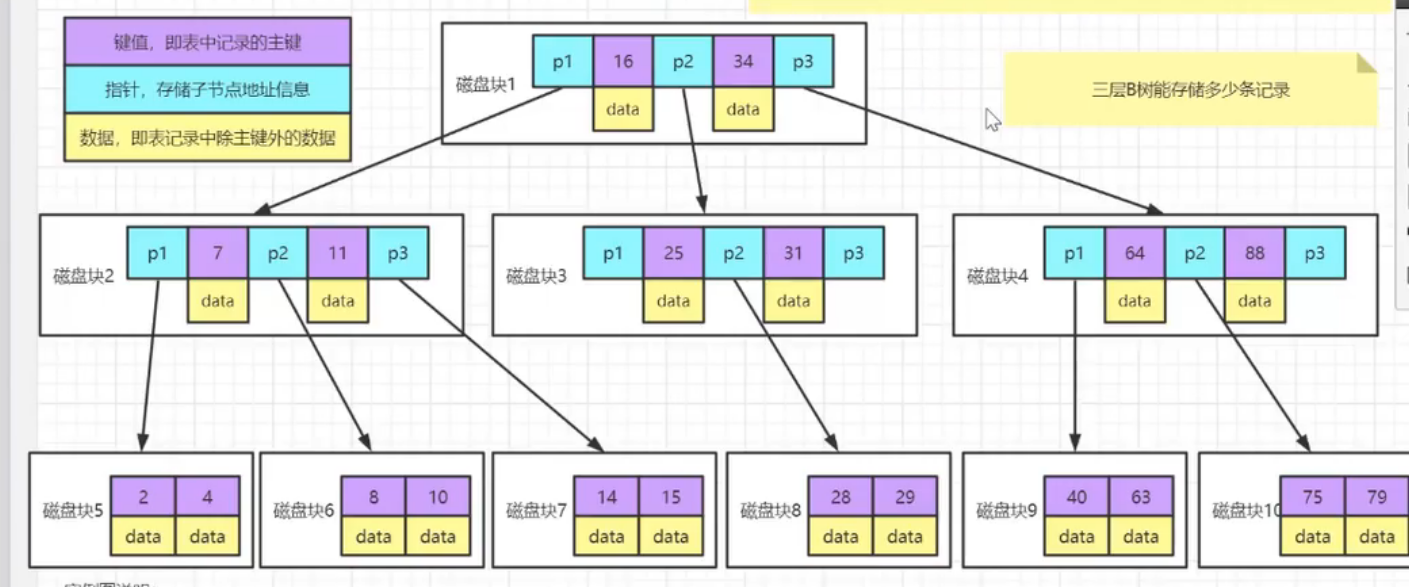
B树实现效果如图,B树每一个磁盘块将数据与索引存放在一起
我们假设data占用1kb大小、索引占用的大小忽略,Innodb中默认一次读块16kb,那么一个块内就可存放16个记录
如果是三层的B树,那么就有16^3=2^12=4096条记录,这显然还是太少了
限制B树的原因是:将索引与数据存放到了一起
而B+树,分开内部与外部节点,内部结点纯放索引,而外部节点纯放数据,就解决了这个问题
7、 B+树的阶是由自己指定的吗?
不是,是由mysql自己调节的
8、key与index的区别
key包括两部分:约束与索引
index就是单纯的索引,帮助辅助查询使用
索引失效的原因
- 不满足最左前缀原则
- 使用了函数表达式
where YEAR(created_time)= %xxx - 存在隐式类型转换:比如
where age='25',可以查,但会导致索引失效 - 使用了
where name = %xxx - 使用了OR操作符:
where name='xx' or age=30,使用了or,如果其中有一个没有索引,就会使索引失效 - 数据量太小:数据量较小索引可能会增大查询时间
- 数据分布不均匀:索引的区分度很小
- mysql的统计信息没有算准:可以手动
ANALYZE table来重新统计信息
优化器对索引的选择
在最开始讲Mysql基本架构的时候说过,优化器会对我们的SQL语句进行优化,会选择使用哪一个索引来进行搜索
优化器的选择依据
优化器选择索引的依据:有很多,最主要的有三个
- 扫描行数
- 考虑基数
- 考虑实际扫描行数
- 考虑回表
- 是否使用临时表
- 是否排序
如何判断扫描行数?
优化器优化的时候,还不能知道这个语句会扫描多少个记录,那么他是如何知道扫描的行数有多少?
通过统计信息来判断,对于索引就是索引的区分度,也就是基数
Cardinality
可以用show index from 表来查看索引的基数
Mysql 如何得到基数的值?
进行采样统计,选择N个数据页,计算这些页面上不同的值,求一个平均值,再乘以这个索引的页面数,就有了这个索引的基数。
基数也不是不变的,当改动大于一个值,就会重新计算统计信息。我们可以使用analyze table t来要求Mysql重新计算统计信息
统计信息存放的位置:
可以设置参数innodb_stats_persistent的值:
- 为on:持久化存储
- 为off:只存储在内存中
索引选择异常和处理
选错异常了怎么办?
【法一】使用force index强制指定一个索引(这属于程序员的操作)
【法二】修改语句,但不修改逻辑(这种情况少)
【法三】在有些场景下,我们可以新建一个更合适的索引,来提供给优化器做选择,或删掉误用的索引。
【法四】对于统计信息不准的情况,可以用analyze table 表名命令来要求重新计算
字符串的前缀索引
当遇到一些类似于邮箱、身份证号这种长的字符串时,查询的次数也很多,所以我们需要设置他们为索引,但是他们的长度往往会很长,所以前缀索引既可以节省内存,又可以作为索引提高查询效率
语法:
1 | alter table SUser add index index1(email); |
前缀索引的检索区别
- 使用前缀索引后,可能会导致查询语句读数据的次数变多
因为使用前缀索引,所以可能导致一次查树并不能得到结果,还需要回表继续进行搜索
- 前缀索引设置长度的依据,可以通过区分度来判断
比如使用这个语句
1 | select |
这样比较L4、L5、L6的值,我们就能知道前缀设多少长度才好
- 使用前缀索引,就舍弃了索引覆盖的优化
如果区分度不大该怎么办?
比如说身份证,如果要设置前缀索引,那么需要设置到很多字节之后区分度才会有提高,这种情况我们可以这么做
- 使用倒序索引
将身份证倒过来作为索引存储,查询时这么查
1 | select field_list from t where id_card = reverse('input_id_card_string'); |
- 使用hash字段
也可以再添加一个字段,作为保存身份证的校验码,注意比较的时候,要将这个校验码和身份证一同做比较
比方说可以用CRC32函数
1 | select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'; |
倒序索引与使用hash字段作为索引的缺点:
- 不能进行范围查找
区别:
- 倒序索引不需要额外占空间
- hash字段做索引更加稳定一些
Sql语句为什么执行变慢了
Mysql抖动
Mysql抖动:Mysql执行过程中,时不时有一句的查询速度特别慢
首先知道两个概念:
脏页:数据页读入内存后,进行了修改,但是内存页还没有写回数据页,此时这个内存页就叫脏页
干净页:写回了磁盘的内存页就叫干净页
Mysql抖动的那个瞬间,很可能是在刷脏页
任何情况下都可能在刷脏页:
redo log写满了:导致必须得刷脏页- 要载入新的数据页,淘汰旧的数据页:如果淘汰的旧的数据页是脏页,那么必须得先将数据写回
- 系统空闲时:Mysql认为系统很闲,就会不停刷脏页
- Mysql正常关闭时,需要将全部脏页写回磁盘
四种情况中,只有情况1与情况2是我们应该着重考虑的,为了减小抖动,我们必须得设置合理的刷脏页机制
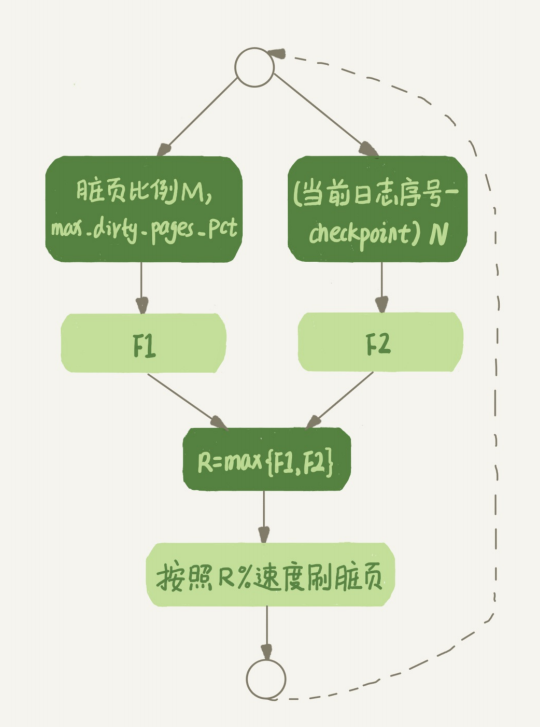
刷脏页的机制
情况1告诉我们得考虑redo log的写入速度
情况2告诉我们得考虑脏页的比例
在Mysql中,也是这么考虑的,它会按某种算法,计算两个数值的大小,取最大的那一个,作为当前刷脏页的速度
Count(*)的执行过程
Count的执行方式
在不同的MySQL引擎中,count(*)有不同的实现方式:
- MyISAM引擎把一个表的总行数存在了磁盘上,因此执行
count(*)的时候会直接返回这个数,效率很高; - 而InnoDB引擎就麻烦了,它执行
count(*)的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
为什么Innodb不学MyISAM,也将总行数记录下来?
因为Innodb支持了事务,所以一个时间内,对于总行数是不确定的
而MyISAM不支持事务,也就不需要考虑这些,直接记录一个总行数就行
为什么不能使用统计信息里面的
Table_rows,它不也是行数吗?
统计信息,都是优化器通过采用分析得到的,也就是说,并不是真正的行数
Count(*) Count(1) Count(主键) Count(字段)的区别
count(字段):首先明确count聚合函数,是返回当前不为null的数据的个数,所以查询字段,会返回当前字段不为null的个数Count(主键):InnoDB引擎会遍历整张表,把每一行的id值都取出来,返回给server 层。server层拿到id后,判断是不可能为空的,就按行累加(由于有读操作,还有判断操作,可见效率比较低)count(1):InnoDB引擎遍历整张表,但不取值。server层对于返回的每一行,放一个 数字“1”进去,判断是不可能为空的,按行累加(不取值,可见效率比查主键高一点)count(*):Mysql专门对此语句进行了优化,不会去取值,它的效率是最高的
速度排行:Count(*) ≈ Count(1) > Count(主键) > Count(字段)
Mysql如何对
count(*)进行的优化?
虽然count也是一行一行加起来的得到的数据,但是它有着优化:
主键索引树的叶子节点是数据,而普通索引树的叶子节点是 主键值。
所以,普通索引树比主键索引树小很多。对于count(*)这样的操作,遍历哪个索引树得 到的结果逻辑上都是一样的。因此,MySQL优化器会找到最小的那棵树来遍历
自己进行计数
当我们的表越来越大,count函数要执行的时间就会越来越长~
怎么解决?我们只能自己想办法计数
- 使用缓存系统保存计数,例如使用Redis
这种方法的好处,是比较快,但是坏处就是,崩溃后数据容易丢
- 在数据库保存计数
可以开启一个事务,来专门进行计数,可以解决崩溃后数据丢失的问题
Mysql主从复制
主从复制的由来
Sql的某些操作(比如备份),是表锁,表锁的期间,其他进程是不能访问数据库的,很影响服务
如果建立多个库,让其中一个库(主库)负责写,其他库负责读就可以提高效率
此外,为了进一步的扩大单个机器的IO性能,多库并用可以提高效率;而且还可以做热备份
什么是主从复制
主从复制:数据可以从一个数据服务器主节点复制到一个或多个从节点
在mysql中,采用了异步复制方式,这样从节点不需要一直访问主服务器来更新自己的数据,数据的更新可以在远程连接上进行
主从复制原理
Mysql5.6之前的主从复制

主库的DML操作会记录到binlog日志当中,并随后等待从节点的IO线程读取,并写入到Relay log中继日志当中,然后由sql线程读取加载到从节点执行,恢复数据
其中IO线程与Sql线程是只能轮流执行
细分一下,总过程由4步组成:
- 主库将DML操作与数据,写入到名为
binlog的日志文件中 - 从节点将开启IO线程,读取
binlog到内存中 - IO线程将读取的内容写入到
Relay log中继日志中,并关闭IO线程 - 从库开启Sql线程,读取并执行
Relay log的sql,将数据恢复到与主库一致
分析整个流程,会发现第四步是影响主从复制的主要原因(前三步都是顺序读取,而最后一步执行多个sql操作是随机读取,可能需要操作多个不同的数据块)
所以在Mysql5.6之前的版本的主从复制延迟问题非常严重
于是Mysql设计者就开始思考,第四步的瓶颈在于操作多个数据块,随机读取造成时间延迟,于是着手向多线程转变
Mysql5.6的并行复制
改变:
- 5.6之前:Slave机上有两个线程IO与Sql线程,前者负责从master读取binlog文件 ,后者负责执行
- 5.6:加入
coordinator(协调者)线程,负责判断event是不是可以并发执行,并分配给worker(负责以前sql thread的任务);coordinator线程负责两个任务- 判断可以并行执行:选择worker线程执行事务的二进制日志
- 判断不可以并行执行或为DDL语句:等待所有
worker线程执行完成后再执行(coordinator也可以执行二进制日志)
如图:
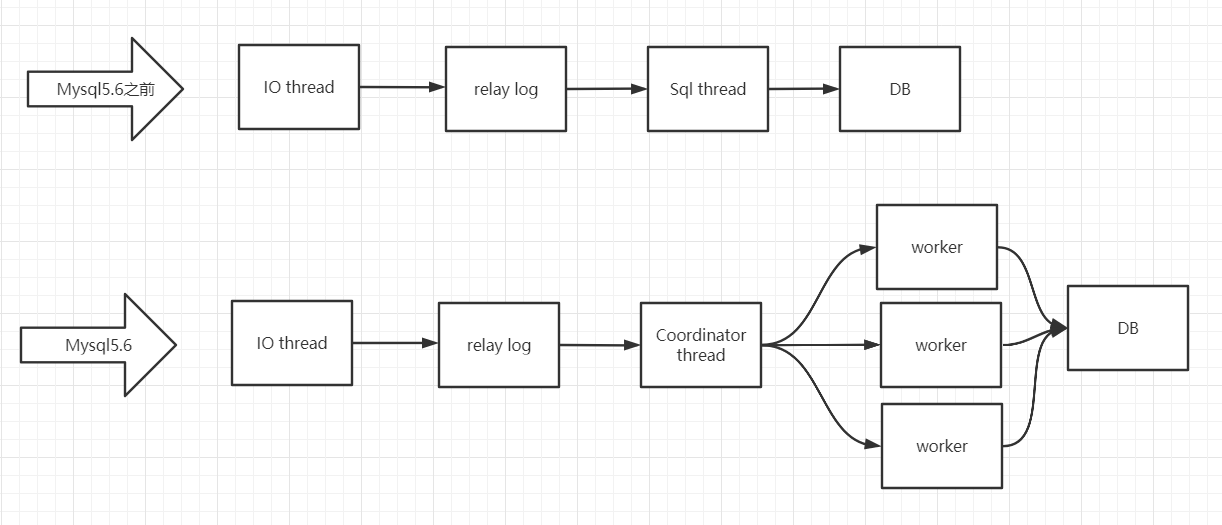
但是此时的并行粒度是库级别的,即不同库的才会进行并行执行,但是常见的情况是一库多表,于是粒度需要细致到表、行
Mysql5.7的并行复制
在5.6.3就尝试使用并行复制,到5.7正式实现了并行复制,完全解决了复制延迟问题,这里我们直接介绍mysql5.7的并行复制原理
enhanced multi-threaded slave MTS 官方称为MTS
引入组提交:涉及到binlog与redo log
通过对事务进行分组,可以优化减少生成二进制日志所需的操作数。
当事务同时提交时,它们将在单个操作中写入到二进制日志中。
如果事务能同时提交成功,那么它们就不会共享任何锁,这意味着它们没有冲突,因此可以在Slave上并行执行。所以通过在主机上的二进制日志中添加组提交信息,这些Slave可以并行地安全地运行事务。
分组后,每一个组的相关信息,都存放在GTID中
crash safe:有了redo log 之后,可以保证数据在断电后,也可以进行恢复,这种保证数据不会丢失的能力叫crash safe
Mysql事务&MVCC
当前读&快照读
- 当前读:读取的是数据的最新记录
- 快照读:读取的是历史版本的记录(读取快照的记录)
触发当前读的语句:
1 | select ... lock in share mode # 给此语句加一个共享锁 |
触发快照读的语句:
1 | select ... |
Innodb行记录的不可见字段
每一行都会包含几个不可见字段
有三个重要的不可见字段:
DB_TRX_ID:创建或修改该记录的事务IDDB_ROW_ID:隐藏主键,如果没有显示给主键且没有唯一键,就会创建这个主键,占有6字节,是长整型DB_ROW_PTR:回滚指针,事务失败的回滚位置(与undo log配合使用)
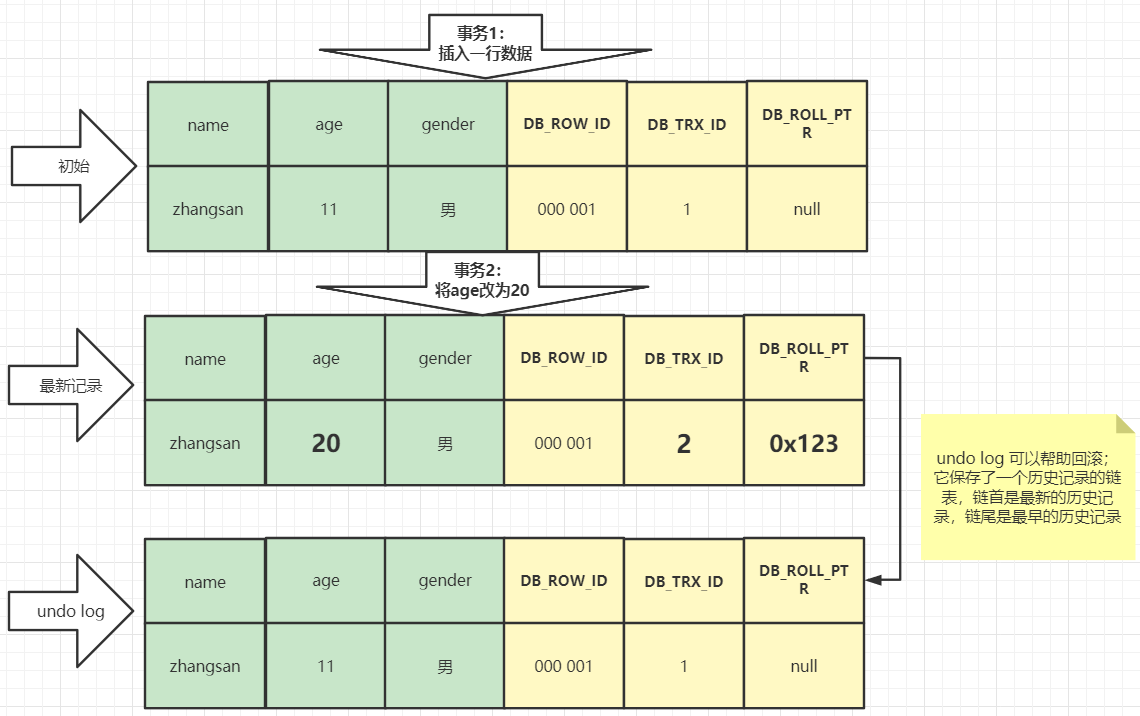
undo log:当多个事务操作同一行数据时,undo log就会保存这样的一个链表,链首为最新的历史记录,链尾为最早的历史记录,方便事务失败恢复
read view
readview:事务在进行快照读的时候产生的读视图
readview包含以下几部分:
trx_list:活跃的事务idup_limit_id:列表中事务最小的idlow_limit_id:系统尚未分配的下一个id
这些值可以与DB_TRX_ID进行判断(属于可见性算法的内容,这里不做详述)
我们来看这样的一个例子:
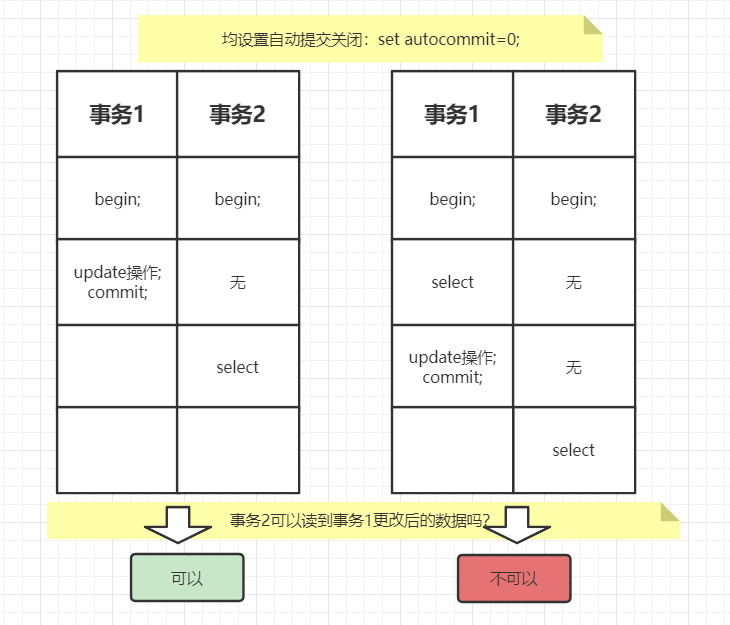
以我们的观点来看,mysql的事务隔离级别是RR可重复读的,就应该看不到更改的值,为什么上图情况1还看到了更新后的数据?
原因在于readview的生成时机不同:
对于不同的事务隔离级别,其
readview的生成时机不同:
- RC 读提交级别:每一次快照读都会生成新的
readview- RR 可重复读级别:只有第一次快照读会生成
readview;之后的读操作都会使用第一次生成的readview
正确的判断逻辑
总结如下:
- 事务自己的更新操作,自己是可以读到的
- 如果版本未提交,不可见
- 如果版本已提交:
- 创建快照前生成,可见
- 创建快照后生成,不可见
来一个例子练手:事务A与事务B最后读到的数据会是什么?
初始:表结构(id, k),数据为(1, 1),autocommit=1自动提交打开

首先解释一下:start transaction with consistent snapshot可以马上开启一个事务(会直接创建一个读视图)
(begin / start transaction并不是立即开启,只有执行到第一个Innodb语句才会开启事务)
结果:事务A读到的数据是(1, 1),事务B读到的数据是(1 ,3)
理解过程:
以事务A的角度分析:
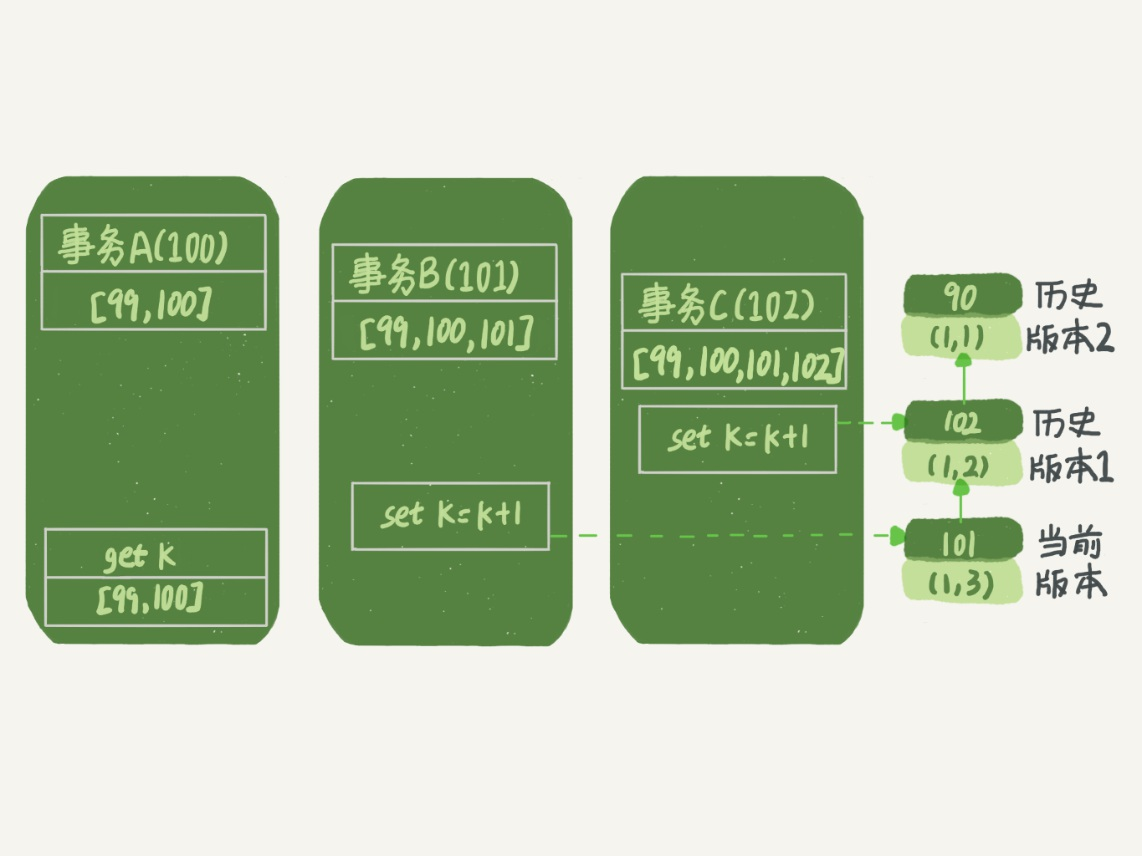
(图的解释:每个事务下面的第一个数组表示当前的活跃事务ID,右边的链表代表undo log,所以在ABC之前有个事务id为99,ABC各自的id为100、101、102)
获取k值时,发现当前版本为(1, 3),可是这个事务还未提交,所以会向前看,即看历史版本1,为(1 ,2),历史版本1虽然已经提交了,但是这个事务是在我创建完快照后才提交的,所以读不到,继续向前读。
以事务B的角度分析:
获取K值时,发现当前版本为(1 ,3),这个事务是我自己的,所以会读到。
还是这个例子,做一个小改动

结果:在事务B执行到update时,会发生锁等待,事务B需要等待事务C提交后才会执行(又将行级锁联系了起来)
ACID的实现原理
有了以上内容,我们就基本上能搞懂Mysql是如何实现ACID的:
- 原子性A:同时成功,要么同时失败;通过
undo log来实现 - 隔离性I:多个事务之间,相互独立;通过MVCC来实现
- 持久性D:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失;通过
redo log来实现 - 一致性C:在事务开始之前和事务结束以后,数据库的完整性没有被破坏;通过实现AID特性来实现
正确的事务启动方式
- 使用
begin;或start transaction,配套的有commit与rollback - 使用
set autocommit=0
一句话:关闭自动提交,每次显示的开启事务
也可以用commit work and chain来提交上一个事务并开启下一个事务
不要使用长事务!
为什么不要使用长事务?
长事务意味着系统里面会存在很老的事务视图。由于这些事务随时可能访问数据库里面的任何数据,所以这个事务提交之前,数据库里面它可能用到的回滚记录都必须保留,这就会导致大量占用存储空间
所以我们每次使用事务,都要记得 关闭自动提交,显示开启事务
也可以设置SET MAX_EXECUTION_TIME事务的最大执行时间
Mysql锁
全局锁
使用FTWRL可以加全局锁:整个库都处于只读状态
1 | Flush table with read lock |
使用场景:做全库备份
当然,全库备份有更好的方式——在RR级别下,使用事务进行备份
官方自带的工具mysqldump使用参数–single-transaction的时候,导数据之前就会启动一个事务,来确保拿到一致性视图。而由于MVCC的支持,这个过程中数据是可以正常更新的
所以,对于全是Innodb引擎的数据库,最好使用–single-transaction参数来进行备份
有RR,为什么还要FTWRL?
不是所有的引擎都支持事务,比如MyISAM,这种情况就只能FTWRL
要让全局只读,为什么不使用
set global readonly=true的方式呢?
- 某些系统使用
readonly的值会被用来做其他逻辑 - 如果出现异常,FTWRL可以释放锁,但是这种方式不行
表级别锁
MySQL里面表级别的锁有两种:
- 一种是表锁
- 一种是元数据锁(meta data lock,MDL)
表锁:
Mysql的表锁属于Server层实现的,和存储引擎无关,用法:
LOCK TABLES:上锁UNLOCK TABLES:释放锁
语法:设置表锁必须先关闭自动提交
1 | SET AUTOCOMMIT=0; |
元数据锁MDL:
无需显示使用,Mysql会自动加
作用:保证其他线程在读或写的时候,表的结构不会被更改
- 线程对表CRUD:Mysql加MDL读锁
- 线程更改表结构,如
alter:Mysql加MDL写锁
注意:MDL机制要注意
比如这个例子
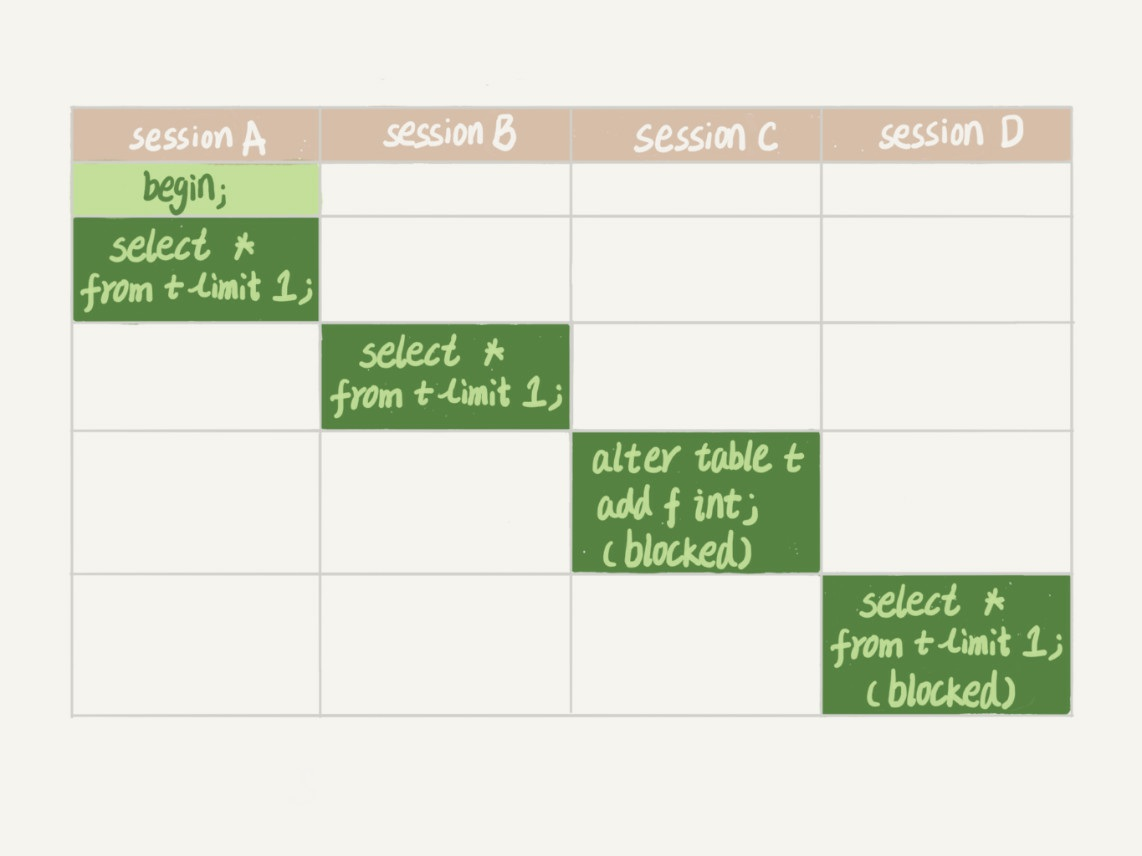
过程:
- SessionA读数据,mysql自动加MDL读锁
- SessionB读数据,无影响
- SessionC更改表结构,由于此表有MDL读锁,所以会进入阻塞
- SessionD读数据,由于SessionC被阻塞,SessionD也会被阻塞
如何安全的给小表加字段?
标准的办法:alter table语句里面设定等待时间(用NOWAIT或WAIT n)
如果在这个指定的等待时间里面能够拿到MDL写锁最好,拿不到也不要阻塞后面的业务语句,先放弃。之后开发人员或者DBA再通过重试命令重复这个过程
1 | ALTER TABLE tbl_name NOWAIT add column ... |
行级别锁
InnoDB 实现了以下两种类型的行锁:
- 共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
- 排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁。
为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB 还有两种内部使用的意向锁(Intention Locks),这两种意向锁都是表锁:
为什么要用意向锁?
为了解决表锁与之前可能存在的行锁冲突,避免为了判断表是否存在行锁而去扫描全表的系统消耗。
注意:意向锁是表锁
例如这么一个场景:
- 事务 A 锁住了表中的一行,让这一行只能读,不能写。
- 之后,事务 B 申请整个表的写锁。
- 如果事务 B 申请成功,那么理论上它就能修改表中的任意一行,这与 A 持有的行锁是冲突的。
- 意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的 IS 锁。
- 意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的 IX 锁。
锁的兼容情况
如下表:
| 列:当前的锁\行:请求的锁 | X | IX | S | IS |
|---|---|---|---|---|
| X | 冲突 | 冲突 | 冲突 | 冲突 |
| IX | 冲突 | 兼容 | 冲突 | 兼容 |
| S | 冲突 | 冲突 | 兼容 | 兼容 |
| IS | 冲突 | 兼容 | 兼容 | 兼容 |
(巧记:意向锁之间兼容,其他遇X则冲)
加锁方法
- 事务可以通过以下语句显式给记录集加共享锁或排他锁:
- 共享锁(S):
SELECT ... LOCK IN SHARE MODE。 其他 session 仍然可以查询记录,并也可以对该记录加 share mode 的共享锁。但是如果当前事务需要对该记录进行更新操作,则很有可能造成死锁。 - 排他锁(X):
SELECT ... FOR UPDATE。其他 session 可以查询该记录,但是不能对该记录加共享锁或排他锁,而是等待获得锁
- 共享锁(S):
- 普通的
select语句不加锁 update insert deleteInnodb会自动加排他锁- 意向锁是由Innodb自动加的
使用场景
select ... for update加排他锁:
为了让自己查到的数据确保是最新数据,并且查到后的数据只允许自己来修改的时候,需要用到 for update 子句。
select ... in share mode加共享锁:
为了确保自己查到的数据没有被其他的事务正在修改,也就是说确保查到的数据是最新的数据,并且不允许其他人来修改数据。
两阶段协议
两阶段锁协议:
行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放
例子:

事务B会被阻塞,直到事务A运行完成,验证了两阶段锁
两阶段锁协议告诉我们:如果一个事务要锁多个行,那么要把最可能造成锁冲突的尽量往后放!
正确的安排事务的执行顺序!
例子:学生A去电影院B买电影票
这个事务涉及到三个步骤:
- A的钱扣除
- B的钱增加
- 增加一条交易记录
如何进行排序呢?
如果有学生C也在电影院B买票,那么步骤2就会有锁冲突
因此2应该放在最后,比如执行3、1、2的顺序,这样做就会提高并发度!
死锁与死锁检测
死锁:两个事务各自拿了对方的锁,而又在等待对方释放的状态
比如这个例子:

上一节提到两阶段协议,所以事务A在更新完id=1的那行数据后,不会释放行级锁,造成死锁状态
怎么打破死锁的局面?
有两种策略:
- 直接进入等待,直到超时。(这个超时时间可以设置参数
innodb_lock_wait_timeout,默认为50s) - 主动发起死锁检测,死锁后,主动回滚死锁链条中某一个事务,让其他事务得以执行(
innodb_deadlock_detect设置为on,默认就是开启的)
显然,第一种方法的时间太长,对于一个在线服务来说根本不能接受,而且超时值设置太小,又会导致非死锁操作也被kill掉
第二种方式也是Mysql默认的方式,可以快速的发现死锁问题并处理,但是也存在负担
(试想每一个事务运行中,Mysql都要检查其他事务是不是拿了这个事务的锁,这样的检测负担很大!)
怎么解决更新热点行的性能问题?
比如说还是这个电影院,影院在做活动,可以低价预售一年内所有的电影票,而且这个活动只做一天。
【法一】:如果能保证不出现死锁问题,直接关了死锁检测(显然不太可取)
【法二】:控制并发度
- 限制客户端:可以限制同时只能有10个用户在进行操作,这样死锁检测的成本很低(不太可行,即使很少的客户端,每个客户端操作很少,也会有很大的并发量)
- 将并发限制放在中间件中:可行
【法三】:设计上优化,可以给电影院的账单行设为10行甚至更多,对齐求和就是总金额,这样也可以减少负担
如果要删除1w行数据,应该选择哪种sql?
- 直接执行
delete from T limit 10000;- 在一个连接中循环执行20次
delete from T limit 500;- 第三种,在20个连接中同时执行
delete from T limit 500;
当然要选择第二种sql,第一种Sql,执行时间太长了
第三种Sql显然会造成死锁
第二种,分次迭代删,才是最好的
索引与锁
在Innodb实现中,行锁是通过给索引上的索引项加锁来实现的(而在Oracle中是通过在数据块中对相应数据行加锁来实现的)
所以使用索引来检索,才会加行锁,除此外都加表锁
由于 MySQL 的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然多个session是访问不同行的记录, 但是如果是使用相同的索引键, 是会出现锁冲突的(后使用这些索引的session需要等待先使用索引的session释放锁后,才能获取锁)
间隙锁
当我们用范围条件而不是相等条件检索数据时,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;
间隙(GAP):对于键值在条件范围内但并不存在的记录
间隙锁(Next-Key锁):InnoDB也会对这个“间隙”加锁,这种锁机制就是间隙锁
很显然,在使用范围条件检索并锁定记录时,InnoDB这种加锁机制会阻塞符合条件范围内键值的并发插入,这往往会造成严重的锁等待。
因此,在实际应用开发中,尤其是并发插入比较多的应用,我们要尽量优化业务逻辑,尽量使用相等条件来访问更新数据,避免使用范围条件。
为什么要使用间隙锁?
- 防止幻读,以满足相关隔离级别的要求;
- 满足恢复和复制的需要(恢复时不能出现幻读现象)
Order by详解
排序在Mysql中,有两种处理方式:
- 全字段排序
rowid排序
以此sql为例,介绍两种排序
全字段排序
先来看此sql
1 | select city,name,age from t where city='杭州' order by name limit 1000; |
使用Explain命令去看一下执行计划,在Extra字段就会显示Using filesort,表示需要进行排序
Mysql会给每个线程分配一块内存用于排序,称为
sort buffer
上面的sql执行流程如图:

注意:按name排序这个过程,有可能在内存中,也有可能是外部排序
决定是在内存还是在外部,取决于sort_buffer_size
- 待排序的数据小于
sort_buffer_size:内存中排序 - 大于
sort_buffer_size:使用外部排序(会使用临时文件)
外部排序:使用归并排序法,会创建很多临时文件,各自排序,然后最后汇总为一个文件
rowid排序
如果Mysql认为,要排序的内容单行长度就很大,那么他会使用rowid排序
排序的过程如图:
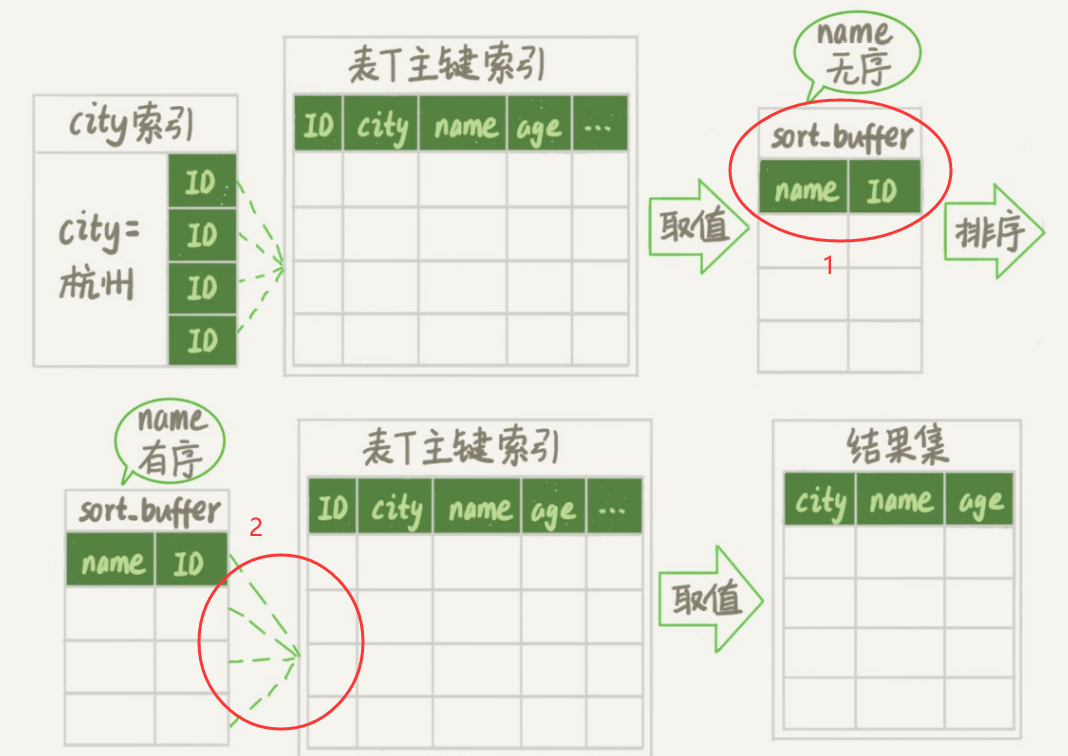
他和全字段排序的区别就在于我在图中圈住的部分:
- 首先
rowid排序在排序时,不会给sort_buffer读入所有字段了,而是读入待排序的键和主键 - 在排位序后,会用
id再去读出数据
由于2情况的发生,会导致读的行数会比全字段排序多一些
MySQL数据类型使用注意
1、整数的UNSIGNED属性
对于不需要存储负数的元素,可以使用此属性翻倍存储值
2、CHAR和VARCHAR的区别
- CHAR:不可变,固定大小,即使没有存满,也会补充空格填满
- VARCHAR:可变,存储额外的长度字段
3、VARCHAR(10)和VARCHAR(100)的区别是什么?
系数表示的都是存储的最大值。对于相同的内容,在磁盘存储时大小是一致的,但是如果提取到内存中,VARCHAR100可能会预分配更大的内存空间
4、DECIAML的存储方式
定点数存储方式:DECIMAL(M,D),M表示总位数,D表示小数位数
存储时,每9位占4字节
| 剩余数字 | 字节数 |
|---|---|
| 0 | 0 |
| 1-2 | 1 |
| 3–4 | 2 |
| 5–6 | 3 |
| 7–9 | 4 |
举个例子:
DECIMAL(18,9)列的小数点两边各有九位,因此整数部分和小数部分各需要4个字节。
DECIMAL(20,6)列有14个整数位和6个小数位。整数位中的九位需要四个字节,其余五位需要三个字节,六位小数需要三个字节
5、TEXT和BLOB
- TEXT用来存储更长的文本数据
- BLOB用来存储二进制大对象,比如图片、音视频
日常开发基本不用,因为:有限制,不能有默认值、无法内存中创建临时表、不能直接创建索引(只能指定前缀长度,创建前缀索引)
6、NULL和""的区别
NULL需要额外存储(BITMAP),""不占额外空间SUM、AVG、MIN、MAX等聚合函数会忽略NULL值COUNT操作中,COUNT(*)会统计null值与"",COUNT(列)不会统计null值,但会统计空字符串- NULL值比较要用
IS NULL
mysql的DATETIME和TIMESTAMP
- 存储内容:
- DATETIME:存储YYYY-MM-DD HH:MM:SS
- TIMESTAMP:存储自1970年开始的秒数,在2038年会用完
- 存储空间:
- DATETIME 8字节
- TIMESTAMP 4字节
- 时区相关:
- DATETIME:UTC时间,与时区无关
- TIMESTAMP:与时区有关,显示的值依赖于当前时区
- 默认值:
- DATETIME:默认为null
- TIMESTAMP:默认为当前秒数
mysql的TIMESTAMP2038年用完怎么办?
- 换用DATETIME
- 使用bigint存储秒数
其他相关问题
自增主键一定是连续的吗?
设置主键为auto_increacement,那么主键一定就是连续的吗?
不一定,可能存在这么几种情况:
- 设置过自增初始值和自增步长
- 唯一键冲突:比如插入数据
(null,1,123),判断id为null,就去取自增id,然后执行插入的时候,发现唯一键123冲突,插入失败,那么下一次插入时,自增ID就会跳过一个。 - 事务回滚:事务回滚后,不会回滚自增ID的值(为什么?因为回滚ID可能会导致两个事务在插入过程中出现主键冲突的问题)
- 批量插入:为了效率,不会挨个申请,而是一次性申请一批量
深分页优化
优化的原因
在Mysql中,经常会使用到limit关键字,比如
1 | select * |
mysql的实际处理并不是直接去取1000000之后的十条数据,而是取1000010条数据,然后忽略前1000000条,返回后十条数据。
因此对深度分页进行一些合理的优化可以提高sql速度
范围查询
在ID连续时,可以使用范围查询代替limit
1 | -- 第一种 |
要求:ID连续
为什么这种方式比limit快?
这种方式会:先找到id为1000000的索引位置,然后取十条数据后返回
limit方式:取1000010条数据(而且有1000000次回表),忽略前1000000次的数据,返回10条
延迟关联
把条件转移到主键索引树,减少回表的次数:
INNER JOIN方式:
1 | -- 第一种 |
子查询方式:
1 | # 通过子查询来获取 id 的起始值,把 limit 1000000 的条件转移到子查询 |
这种方式不如使用INNER JOIN
这种方式为什么快?
其实也是延迟关联的方式,子查询获取到ID集合后,才去拿数据,减少回表次数
覆盖索引
如果数据只需要获得ID与普通索引的值,能利用索引覆盖的特性,可以完全避免回表。
数据库字段设计规范
1、能用数字存储,就尽量用数字而不使用字符串
存储IP地址,就可以使用整数,mysql还有方法处理IP地址:
INET_ATON():把 ip 转为无符号整型 (4-8 位)INET_NTOA():把整型的 ip 转为地址
插入数据前,先用 INET_ATON() 把 ip 地址转为整型,显示数据时,使用 INET_NTOA() 把整型的 ip 地址转为地址显示即可
存储时间类型
时间类型可以使用DATETIME(8字节)、TIMESTAMP(4字节)、BIGINT(8字节)
- 在INNODB存储引擎,如果有按时间排序或是按时间范围查找,性能bigint > timestamp > datetime
- 如果为了时区无关,使用DATETIME
- 如果只是为了存储,可以考虑TIMESTAMP,但是只能存储到2038年
2、对于非负类型,使用无符号数据表示
无符号比有符号多一倍空间
3、小数值,表示年龄、状态,用TINYINT类型(占用1字节)
4、如果有BLOB或是TEXT列,尽量分离到单独的扩展表中
- BLOB或TEXT如果遇到排序,是不会使用内存临时表排序的,只能使用磁盘临时表,性能很差
- BLOB和TEXT查询一定不要使用
select *
5、尽可能所有列定义为Not Null
mysql存储null值,需要额外1字节存储(bitmap)
6、财务相关使用decimal类型,精准浮点数
在计算时不会丢失精度。占用空间由定义的宽度决定,每 4 个字节可以存储 9 位数字,并且小数点要占用一个字节
数据库索引设计规范
1、单表的索引最多不要超过5个,会增大执行计划的分析时间,反而降低查询性能
2、禁止使用全文索引,OLTP不应该搞OLAP的事情
3、主键的选择
- 最好不要使用业务相关字段
- 要选择有序的字段,不适用UUID、HASH、字符串作为主键,可以使用雪花算法
- 尽量要小
4、联合索引的顺序选择,最左键应该要区分度大、字段长度小、使用最频繁
5、不使用外键
- 外键会影响父表与子表的写操作性能
- 外键建议在业务端实现
数据库SQL开发规范
1、不在数据库做运算、复杂运算业务端完成
**2、禁止使用select ***
- 会消耗更多资源:CPU、网络带宽
- 无法使用索引覆盖等优化机制
- select具体字段,会减少表结构发生变化后的影响
3、禁止使用不含字段的INSERT语句,防止表结构变化后出现问题
1 | insert into t values ('a','b','c'); # 禁止 |
4、尽量使用预编译语句
- 预编译语句只需要解析一次,且可以重复使用,每次传输只需传参数,可以提高效率,还可以避免SQL注入
5、大数据量使用连接查询代替子查询
子查询多次遍历数据(先查子查询语句,结果存入内存临时表或是磁盘临时表),然后再去使用外部查询查子查询的结果
连接查询可以同时利用多个表之间的索引(如果可以)得到结果,只查一次
6、除非要去重,否则使用UNION ALL而不是UNION
相关链接
- 博客1:平衡二叉树
- 博客2:B树与B+树图文阐述
- 博客3:mysql不同引擎的索引实现
- 视频课
- 博客4:Mysql并行复制
- 视频课*2:关于事务
- 知乎:mysql锁
- 极客时间:Mysql实战45讲
- Explain官网介绍