Java 线程与并发
Java 线程与并发
本章分为两个部分:
上半部分:Java多线程——基础
下半部分:Java并发编程——进阶
Java多线程
创建线程的方式
在Java中,有四种创建线程的方法:
- 继承
Thread类- 继承
Thread类 - 重写
run()方法 - 用
start()方法开启线程(是一个Native方法)
- 继承
- 实现
Runnable接口- 实现
Runnable接口 - 重写
run()方法 - 使用
Thread的构造方法,传入实现了Runnable接口的类对象创建对象 - 调用
Thread对象的start()方法
- 实现
- 实现
Callable接口(一个有返回值的线程)- 实现
Callable<T>接口,注意有泛型 - 重写
call()方法 - 通过
ExecutorService对象的submit( Callable<T> )方法,将实现了Callable接口的thread上传,返回值是一个Future对象 - 通过
Future对象的get()方法就可以获取到值
- 实现
- 线程池(具体内容会在下一章Java并发编程进行介绍)
- 通过
Executor来获取线程池 - 通过
ExecutorService的execute(Runnable接口)执行任务,没有返回值 - 通过
ExecutorService的shutdown()方法关闭线程池
- 通过
第一种方式demo(过于简单可以跳过):
1 | public class MyThread01 extends Thread{ |
第二种方式的demo(过于简单可以跳过):
1 | public class MyThread02 implements Runnable{ |
实现Callable接口demo:
1 | public class MyThread03 implements Callable<String> { |
线程池demo:
1 | // 1 获取线程池 |
不同创建方式的区别
- 继承
Thread类:优点是简单方便;缺点是Java单继承,如果已经有一个父类,将不再能使用这种方法。 - 实现
Runnable接口:较好的创建线程的方法 - 实现
Callable接口:需要配合ExecutorService使用,如果需要返回值可以使用这种方法,返回值可以通过Future获得 - 使用线程池:较为复杂,但是功能多样。
线程中使用的设计模式:静态代理模式
静态代理模式中有 真实对象、代理对象
- 真实对象与代理对象要实现同一个接口
- 代理对象要代理真实的角色
优点:
静态代理模式可以帮助我们处理一些其他的事情,真实对象可以专注于做本职任务
举例:
在多线程中,实现Runnable接口的类就使用了静态代理模式:
例如这个demo:真实对象——MyThread02、代理对象Thread,他们实现了同一个接口Runnable,然后通过代理类Thread代理真实对象myThread02,执行run方法(通过start执行)
1 | public class MyThread02 implements Runnable{ |
线程的五大状态
老生常谈的问题,说再多不如图:
(其实这里的五大状态,应该算OS层面的线程的五大状态,具体JVM里线程的状态,后面会说)

除此外,还要说明几点:
- 创建状态:此时Jvm会为其分配内存空间,初始化成员变量的值
- 就绪状态:JVM为其创建方法栈和PC
- 运行状态:获得了CPU
- 阻塞状态分三种情况
- 等待阻塞:线程调用了
wait()方法,进入等待队列 - 同步阻塞:要获取的同步锁被别的线程占用,JVM会将这个队列放入锁池(Lock Pool)中
- 其他阻塞:由于
sleep()、join(),或者是IO请求时产生中断
- 等待阻塞:线程调用了
- 导致线程死亡的情况(下一节详细介绍)
- 正常结束:
run或call方法运行结束 - 异常结束:抛出未捕获的Error或是Exception
- 调用stop:
stop()不建议使用,因为很容易导致死锁;官方也声明这是一个即将过时的方法。
- 正常结束:
终止线程的方式
终止线程有很多方式,这里主要介绍四种:
正常退出
程序run()或call()方法运行结束,线程正常退出
使用flag退出线程
大多数情况下,线程是伺服线程,所以我们一般使用一个变量来控制线程的退出:
伺服线程:即需要长时间运行的线程,多为循环体
1 | public class ThreadSafe extends Thread { |
注意到,此变量使用了volatile关键字,可以使同一时刻只能有一个线程修改exit的值(此关键字看下文详细阐述)
使用Interrupt
注意:中断并不会直接终止线程,而是给线程发送一个中断信号,线程可以根据中断信号来决定是否终止自己的执行。
因此终止线程需要我们自己动手,中断只是发出一个信号,在线程中,使用isInterrupted()判断
1 | public void run() { |
根据线程是否处于阻塞状态,使用interrupt中断线程有两种情况:
线程处于阻塞状态:
一些操作(如
sleep()、wait()、join()等)会导致线程阻塞当阻塞的线程调用
interrupt()方法时,会抛出InterruptException异常。此时我们想跳出线程就必须通过代码捕获该异常,然后 break 跳出循环状态注意:只有当捕获异常并
break后,才能正常结束run方法```java
while (!Thread.currentThread().isInterrupted()){try { System.out.println("sleep"); Thread.sleep(2000); System.out.println("wakeup"); } catch (InterruptedException e) { break; }}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2. 线程不处于阻塞状态:
- 使用`isInterrupted()`判断线程的中断标志来退出循环。当使用`interrupt()`方法时,中断标志就会置`true`
```java
public class ThreadSafe extends Thread {
public void run() {
while (!isInterrupted()){
//非阻塞过程中通过判断中断标志来退出
try{
Thread.sleep(5*1000);
//阻塞过程捕获中断异常来退出
}catch(InterruptedException e){
e.printStackTrace();
break;//捕获到异常之后,执行 break 跳出循环
}
}
}
}
使用stop
一个已经过时的方法,线程不安全 0
thread.stop()调用之后,创建子线程的线程就会抛出ThreadDeatherror 的错误,并且会释放子线程持有的隐式锁。
一般任何进行加锁的代码块,都是为了保护数据的一致性,如果在调用 thread.stop()后导致了该线程所持有的所有锁的突然释放(不可控制),那么被保护数据就有可能呈现不一致性,其他线程在使用这些被破坏的数据时,有可能导致一些很奇怪的应用程序错误。
sleep()与wait()
sleep()方法在Thread类中,是一个本地静态方法
1 | public static native void sleep(long millis) throws InterruptedException; |
wait()方法是在Object类中的,是一个不可重写的本地方法
1 | public final native void wait(long timeout) throws InterruptedException; |
| 对比项 | sleep | wait |
|---|---|---|
| 是否让出CPU | 是 | 是 |
| 是否让出对象锁 | 不释放 | 释放 |
| 如何进入就绪状态 | 设定时间到或是调用interrupt()方法唤醒休眠线程 |
调用notify方法 |
| 使用范围 | 任何地方 | 必须在同步代码块中 |
wait是醒着的等待,所以会释放锁
sleep抱着锁睡着了,所以不会释放锁
start方法
在Java源码中,start()方法会调用本地方法start0(),由C来实现线程的创建
所以Java本质上来说,是创建不了线程的,需要调用C++来实现
源码如下:
1 | public synchronized void start() { |
start方法与run方法的区别:
1 | Thread t1 = new Thread(r1); |
- 使用
Thread.start()来启动新的线程,实现并行执行。 - 使用
Thread.run()仅仅是在当前线程上同步地执行run()方法的代码,不会启动新的线程
Java并发编程
JUC
并发编程离不开JUC,什么是JUC?
指JDK下的包:java.util.concurrent,简写为JUC
这个包内包含所有的与并发相关的操作,因此取名为JUC
并发:cpu快速切换程序执行,形成同时运行的假象(多个任务在同一时间段内交替执行)
并行:相对于串行而言,指多个程序同时执行(多个任务在同一时刻同时执行)
守护线程
守护线程(也叫后台线程):
为用户线程提供公共服务,没有用户线程时会自动离开
特点:
- 优先级比较低
- 普通线程可以通过
setDaemon(true)来设置一个线程为守护线程 - 守护线程中创建的新线程依然是守护线程
- 守护线程是JVM级别的;以 Tomcat 为例,如果你在 Web 应用中启动一个线程,这个线程的生命周期并不会和 Web 应用程序保持同步。也就是说,即使你停止了 Web 应用,这个线程依旧是活跃的
- 只要有一个用户线程,那么守护线程就不会退出;如果全是守护线程,那么守护线程也就会退出
Java默认有两个线程:
main线程: Java 程序的入口,它从main方法开始执行。在main方法中创建的任何线程都会成为主线程的子线程GC线程:GC线程就是守护线程,当GC线程是JVM中仅剩的线程时,GC线程会自动离开
线程池
线程池的作用
- 增快响应速度
- 控制并发量(最主要的原因)
- 对线程进行统一管理
- 减小线程切换时的上下文开销
实现原理:每一个Thread都有一个start方法,当调用start启动线程时,JVM就会调用该类的run方法
线程池就是通过不断向start方法中传递Runnable对象
线程池常见类的简介
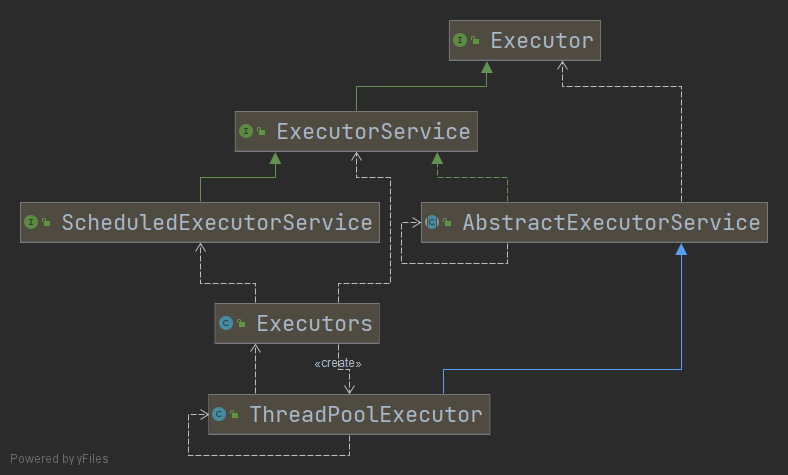
Executor:顶级接口ExecutorService:次级接口,一般使用此类使用线程池,通过调用execute与submit方法执行任务execute方法:没有返回值,执行Runnable方法submit方法:返回Future接口对象,
Executors:JDK官方实现的四类线程池,其本质就是ThreadPoolExecutor创建,只不过参数不同ScheduledExecutorService:ExecutorService的子接口,实现了任务定时执行,JDK实现的线程池中,newScheduledThreadPool会返回一个此接口的对象ThreadPoolExecutor:创建线程最详细的方法,有七个参数
线程池的组成&参数
- 线程池管理器:用于创建并管理线程池
- 工作线程:线程池中的线程
- 任务接口:每个任务必须实现的接口,用于工作线程调度其运行
- 任务队列:用于存放待处理的任务,提供一种缓冲机制
在Executor框架内,ThreadPoolExecutor负责创建线程池,构造方法如下:
1 | public ThreadPoolExecutor(int corePoolSize, |
corePoolSize:线程池线程数量maximumPoolSize:最大线程数量keepAliveTime:最大连接时长(当前线程数量处于上面两个数量之间,就会判断最大连接时长)unit:时间单位workQueue:阻塞队列,被提交但是没有被执行的任务threadFactory:线程工厂,这里使用默认的线程工厂handler:拒绝策略
线程池的状态
ThreadPoolExecutor有五种状态:这五个状态由ctl来控制,ctl是一个AtomicInteger类型的变量,状态就由ctl来获取
1 | private static final int RUNNING = -1 << COUNT_BITS; |
拒绝策略
线程池中线程已经使用完,且任务队列也已经满了,此时就需要对新来的任务进行拒绝
JDK内置有四种拒绝策略,这四种拒绝策略是ThreadPoolExecutor类的内部类
AbortPolicy:直接抛出异常,阻止系统正常运行。CallerRunsPolicy: 只要线程池未关闭,该策略直接在调用者线程中,运行当前被丢弃的任务。(显然这样做不会真的丢弃任务,但是,任务提交线程的性能极有可能会急剧下降)DiscardOldestPolicy: 丢弃最老的一个请求,也就是即将被执行的一个任务,并尝试再次提交当前任务DiscardPolicy: 该策略默默地丢弃无法处理的任务,不予任何处理。如果允许任务丢失,这是最好的一种方案。
不同线程池
Java中有四种线程池,他们的顶层接口是Executor,但是严格意义上来说Executor并不是一个线程池,而是一个执行线程池的工具,真正的线程池接口是ExecutorService
ExecutorService有四个静态方法:
newSingleThreadExecutornewFixedThreadPoolnewScheduledThreadPoolnewCachedThreadPool
下面我们来说这些不同线程池的特点
newSingleThreadExecutor
1 | public static ExecutorService newSingleThreadExecutor() { |
特点:
- 核心线程只有一个
- 所有任务按照先来先执行的顺序执行
newScheduledThreadPool
1 | public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { |
特点:
可以定时执行
返回
ScheduledExecutorService接口,是ExecutorService的子接口有两个重要的方法:
schedule()方法可以实现延迟执行,有三个参数:Runnable接口- 延迟时间
- 时间单位
scheduleAtFixedRate()可以实现定时周期执行,有四个参数:Runnable接口- 初始延迟时间
- 执行周期
- 时间单位
demo:
1 | public static void main(String[] args) { |
newCachedThreadPool
1 | public static ExecutorService newCachedThreadPool() { |
特点:
没有创建核心线程(核心线程数为0),最大线程数为
Integer.MAX_VALUE将任务添加到同步等待队列
SynchronousQueue(如果入列成功,那么会等待空闲的线程去运行,如果没有空闲线程,会创建线程运行)适用于短期异步程序
若一个线程60s未被使用,会被移除
newFixedThreadPool
1 | public static ExecutorService newFixedThreadPool(int nThreads) { |
特点:
- 创建有n个线程的线程池
- 只会创建核心线程!(因为核心线程数与非核心线程数相等)
- 如果任务队列没有任务,线程会阻塞在
take方法,不会被回收 - 如果线程因失败或异常而终止,那么会创建一个新线程代替他持续后续的任务(可选)
- 池若不关闭,线程也不会移除
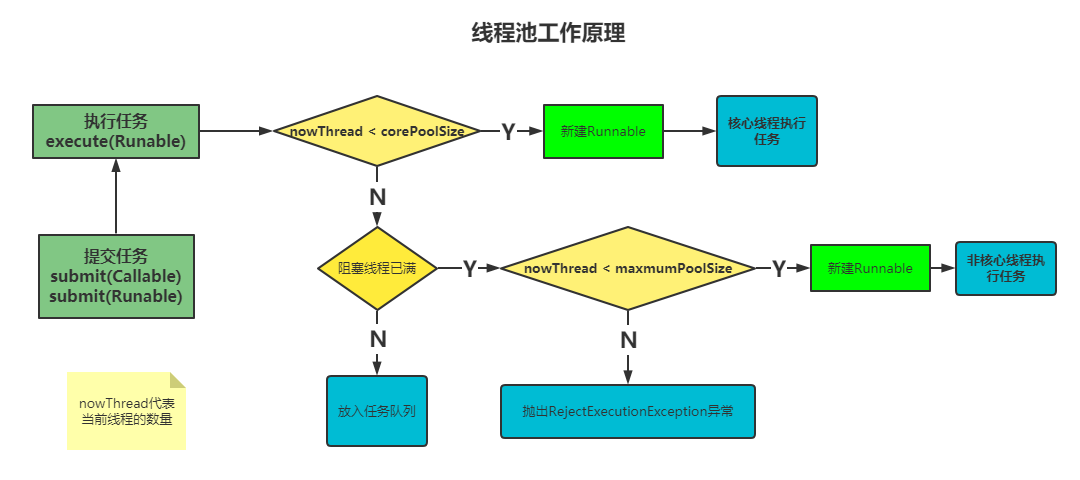
线程池工作原理
由图可以看出,创建线程池的是Executors类,回到第一节的demo
线程池的工作原理如下:
- 线程池刚创建时,内部没有一个线程
- 当调用
execute()方法添加任务,会与corePoolSize进行对比- 如果正在运行的线程数量小于
corePoolSize,马上创建线程运行这个任务 - 如果正在运行的线程数量大于等于
corePoolSize,那么这个任务放入任务队列 - 如果任务队列满了,而且正在运行的线程数量小于
maxmumPoolSize,那么还是要创建非核心线程立刻运行这个任务 - 如果任务队列满了,而且正在运行的线程数量大于等于
maxmumPoolSize,那么会抛出RejectExecutionException异常(默认的抛弃策略AbortPolicy)
- 如果正在运行的线程数量小于
- 线程完成任务会从任务队列找下一个任务来执行
- 当一个线程闲置,并且运行时间超过
keepAliveTime时,线程池会判断,如果当前运行的线程数量大于corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到corePoolSize的大小
原理如图:
阻塞队列
BolckingQueue的API:
| 方法\处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
|---|---|---|---|---|
| 插入方法 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除方法 | remove() | poll() | take() | poll(time,unit) |
| 检查方法 | element() | peek() | - | - |
常用的实现了此接口的类有:
ArrayBlockingQueue- 底层由数组组成,有界的阻塞队列
- 可以指定初始化大小,一旦初始化不能修改
- 构造方法中可以设置是否为公平锁
LinkedBlockingQueue- 无界的阻塞队列
- 底层是链表
- 队列按照先进先出的原则对元素进行排序
DelayQueue- 该队列中的元素只有当其指定的延迟时间到了,才能够从队列中获取到该元素
- 也没有大小限制
PriorityBlockingQueue- 基于优先级的无界阻塞队列(优先级的判断通过构造函数传入的Compator对象来决定)
- 内部控制线程同步的锁采用的是非公平锁
SynchronousQueue- 比较特殊,没有容器存储,适用于一些线程间直接传递任务的场景
- 是
newCachedThreadPool使用的阻塞队列 - 每个插入操作必须等待一个相应的删除操作:一个
put必须等一个take,一个take必须等一个put
Java中线程的方法与状态转换
在JDK源码中,Thread.State类代码如下,有六个状态:
1 | public enum State { |
线程的基本方法有wait()、notify()、notifyAll()、sleep()、join()、yield

wait():直接调用后会进入waiting状态;会释放锁;加时间参数的话,会进入TIMED_WAITING状态- 注意:
wait()方法不能写在if的执行语句中,如果有此需求,可以使用while进行判断(虚假唤醒)
- 注意:
notify():唤醒在一个锁上等待的单个线程;如果有很多线程,会随机选择一个唤醒sleep():进入TIMED_WAITING状态,不会释放当前占有的锁;yield():会让线程从执行进入就绪状态,让出当前CPU时间片interrupt():本意是给这个线程一个通知信号,会影响这个线程内部的一个中断标示位;不会改变线程的状态调用方法不会中断一个正在运行的线程;仅仅只是改变了一个中断标识位
若线程原本调用
sleep()而处于TIMED_WAITING状态,调用此方法会抛出InterruptException,从而使线程提前结束TIMED_WAITING状态抛出
InterruptException后,会恢复中断标志位中断状态是线程固有的一个标识位,可以通过此标识位安全的终止线程
比如,你想终止 一个
thread时,可以调用thread.interrupt()方法,在线程的run方法内部可以根据thread.isInterrupted()的值来优雅的终止线程
join():等待其他线程终止,在当前线程中调用join(),会使当前线程阻塞,等到另一个线程结束,才会变为就绪状态。- 为什么要有
join()方法?很多情况下主线程启动了子线程,需要用到子线程的返回结果,即主线需要等到子线程结束后再结束,就有了join方法
- 为什么要有
下面是一个join方法的使用示例:
1 | Thread thread1 = new Thread(() -> { |
wait的使用
wait并不是Thread的方法,而是Object的方法,但是wait能改变当前线程的状态。
wait一般搭配Synchronized使用。
wait与notify打印ABC
下面是一个wait与notify的使用示例,例子循环打印ABC:
1 | public class WaitNotify { |
虚假唤醒
虚假唤醒:例如,生产者生产了1个商品,但是却唤醒了3个消费者来消费,最终只能有一个消费者消费成功,其他两个线程就被“忽悠”了
测试demo:
1 | class PV{ |
main方法
1 | public static void main(String[] args) { |
运行结果如下:
1 | A:1 |
发现出现了负数这种情况,显然不是我们想要的
为什么会出现这种问题?
注意这里
1 | if( x != 0){ |
我们使用if进行判断,只会执行一次,如果该线程被唤醒,那么将不会去判断x != 0这个条件
所以要使用while,将方法中if判断改为while即可
总结:
如果要判断条件并进行wait()方法,不能使用if(),会出现虚假唤醒的现象
锁及相关概念(重点)
乐观锁与悲观锁
乐观锁与悲观锁是一种对于锁的思想:
- 乐观锁:认为写入少
- 悲观锁:认为写入多
由两种观点,就有不同的实现:
乐观锁认为写入少,所以不会上锁,但是更新时会进行一个判断(CAS操作),这样即使没有上锁,也不会出现线程安全问题。
悲观锁认为写入多,在每次读/写数据时都会进行上锁,其他线程想要进行读写数据,必须先拿到锁(Synchronized就是悲观锁的一种实现)。
什么是CAS
CAS(Compare And Swap/Set):比较并变换,是一个原子操作,相同则更新
CAS(V,E,N)V 表示要更新的变量(内存值,由于多线程的存在,可能与E不同)
E 表示预期值(旧的)
N 表示新值(想设置的新值)
CAS比较流程:
- 如果
V==E值时,会将V=N(内存值 == 预期值,说明没有线程对当前变量进行写操作) - 如果
V!=E,则当前线程什么都不做(内存值 != 预期值,说明已经有其他线程做了更新,那么现在就不能更改这个值) - 最后,CAS操作返回当前 V 的真实值
注意:
- CAS 操作是抱着乐观的态度进行的(乐观锁),它总是认为自己可以成功完成操作
- CAS可以用来实现自旋锁:即会有一个线程进行自旋,反复判断是否符合条件
- 当多个线程同时使用 CAS 操作一个变量时,只有一个会胜出,并成功更新,其余均会失败
- 失败的线程不会被挂起,仅是被告知失败,并且允许再次尝试,当然也允许失败的线程放弃操作
- 基于这样的原理,CAS 操作即使没有锁,也可以发现其他线程对当前线程的干扰,并进行恰当的处理。
在Java中,原子类AtomicInteger有CompareAndSet的操作:
1 | AtomicInteger atomicValue1 = new AtomicInteger(9); |
CAS存在的问题:
- ABA问题
- 循环性能开销大
- 只能保证单个变量的原子操作
AtomicInteger
AtomicInteger是一个保证原子操作的Integer类
它的关键结构如下:
1 | // 存储内存偏移量(相对于对象的起始位置,获得成员变量的偏移量) |
我们知道,普通的int,他的i++操作并不是一个原子操作,但是AtomicInteger的getAndIncrement是一个原子操作
1 | public final int getAndIncrement() { |
getAndIncrement调用了unsafe类,unsafe类提供了一些底层的、危险的操作,通常用于实现Java标准库和虚拟机的内部功能
下面是其getAndAddInt:
1 | // 下面贴出unsafe的getAndAddInt方法传入三个参数:本实例,value的内存地址偏移(偏移量是相对于对象的起始地址的位置),要加的数量 |
因此AtomicInteger的实现原理就是:volatile + cas
ABA问题
CAS过程中,有ABA问题

如何解决ABA问题?
加一个版本号即可,每次更改这个值就对齐加1,然后cas比较这个版本号就知道是否出现了ABA问题
自旋锁
自旋锁:CPU对线程进行轮询,反复询问是否释放锁,直到释放为止
自旋周期:CPU轮询的时间
优点:减少了线程阻塞;对于锁的竞争不激烈,且占用锁时间非常短的代码块来说性能能大幅度上升
缺点:如果锁竞争激烈或是占用锁时间长,那么会持续的占用CPU是极大的性能损耗
在Java中,1.5时自旋周期时定死的,在1.6后加入了适应性自旋锁,由前一次在同一个锁上的自旋时间以及锁的拥有者的状态来决定
1 | // 自旋锁的开启 |
使用CAS操作可以实现一个自旋锁。
可重入锁(递归锁)与不可重入锁
可重入锁(也叫递归锁):
理解方式一:当一个线程获取对象锁之后,这个线程可以再次获取本对象上的锁,而其他的线程是不可以的
理解方式二:一个线程执行一个嵌套的方法时,当外部方法获取到锁,他内部调用的方法无需再去获取锁
理解方式三:锁分配的单位是线程,而不是方法。一个方法无论嵌套自身的方法多少次,锁依然在这个线程内,因此无需再获取锁
在JAVA环境下ReentrantLock和synchronized都是可重入锁
可重入锁的目的是为了解决死锁的问题
公平锁与非公平锁
公平锁(Fair):加锁前检查是否有排队等待的线程,优先排队等待的队列,先来先得
非公平锁(Nonfair):加锁不考虑排队等待问题,直接尝试获取锁,获取不到自动到队尾等待(可以插队)
注意:
- 非公平锁性能高于公平锁5-10倍,因为公平锁要维护等待队列
- 在Java中,
synchronized是非公平锁,ReentrantLock默认的lock()方法采用的是非公平锁 - 非公平锁可能会导致“饥饿”的现象发生。
共享锁和独占锁
独占锁(也被称为写锁):每次只有一个线程能持有锁;一种悲观策略,无论是读操作还是写操作,都会进行加锁。
共享锁(也被称为读锁):允许多个线程同时获取锁,并发访问,共享资源。一种乐观锁
注意:
- JUC中的
ReadWriteLock读写锁,允许一个资源可以被多个读操作访问,或者被一个写操作访问,但两者不能同时进行 - 在共享锁占有期间,不允许写操作,如果有写操作,需要释放共享锁,转为独占锁(这种转变也称为锁升级)
AQS同步抽象队列
AQS (AbstractQueuedSynchronizer):抽象的队列式同步器,定义了一套多线程访问共享资源的同步器框架,很多锁都是通过AQS来实现的,例如
ReentrantLock、Semaphore、CountDownLatch
这个抽象类主要维护了一个状态state还有一个FIFO的线程等待队列:

state状态:
1 | private volatile int state; |
有三个方法可以操作这个状态的值:
1 | protected final int getState() { |
这里贴一个使用AQS实现的独占锁demo:一般AQS都会使用静态内部类来实现
1 | public class AqsLock { |
1 | public static void main(String[] args) { |
执行结果为:
1 | Thread-0 is trying to acquire the lock. |
锁升级
总共有四种:无状态锁、偏向锁、轻量级锁、重量级锁
在内存中,锁的信息存放在对象头中的markword中(markword包含的内容有三大部分:Hashcode、锁信息、GC信息)
锁升级:
随着锁的竞争,锁可以从偏向锁升级到轻量级锁,再升级到重量级锁;
但是锁的升级只能是单向的,不存在降级
偏向锁
大部分情况下锁并不存在多线程竞争,而总是由同一线程多次获得
由此提出了偏向锁
偏向锁:在某个线程获得锁后,消除这个线程重入(CAS)的开销,看起来非常偏向这个线程,所以叫偏向锁
轻量级锁的获取及释放依赖多次CAS,但是偏向锁只需要在置换线程ID时依赖一次CAS指令
特点:
偏向锁主要用来优化同一线程多次申请同一个锁的竞争
一次CAS,只比较Thread ID
消除了重入开销
轻量级锁
“轻量级”是相对于使用操作系统互斥量来实现的传统锁而言的
作用:
- 多次CAS,自旋判断
重量级锁
synchronized是通过对象内部的一个叫做监视器锁来实现的,但是监视器锁本质又是依赖于操作系统底层的Mutex lock来实现的
操作系统想要实现一个重量级锁,必须从用户态切换到核心态,所以这也是synchronized效率低的原因
重量级锁:依赖于操作系统的
Mutex Lock实现的锁
JDK1.6 以后,为了减少获得锁和释放锁所带来的性能消耗,提高性能,引入了“轻量级锁”和 “偏向锁”
锁升级过程
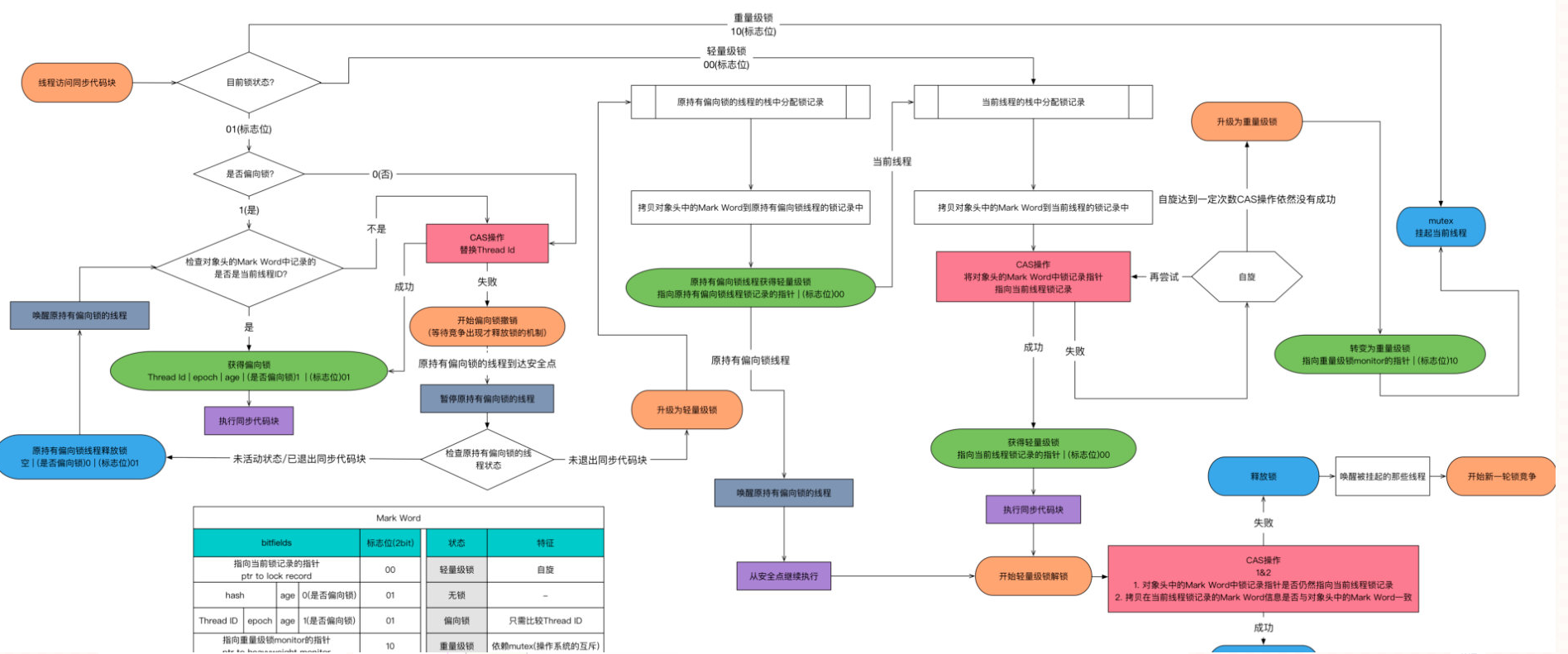
当一个线程A要去获取一个锁的时候,简单过程如下:
- 如果处于无锁状态,那么将锁设置为偏向锁,并设置A的线程号记录在对象头
- 如果A重复进入此锁,只需要判断线程A线程ID与记录是否相同,就给锁(一次CAS即可)
- 如果线程B想要获取锁,进行一次CAS判断
- CAS判断成功:线程B获取到锁
- CAS判断失败:升级为轻量级锁
- 轻量级锁进行多次CAS判断,如果仍然不能满足当前的竞争状况,那么升级为重量级锁
- 重量级锁是OS实现的排他锁,需要从用户态进入到核心态,十分浪费性能。
Synchronized
Java中使用专门的关键字
Synchronized,是悲观锁、可重入锁、非公平锁
直接修饰:
- 修饰方法:锁住对象的实例(
this),即方法的调用者 - 修饰静态方法:锁住
Class实例(因为Class数据存放在永久代(元空间),此位置是全局共享的,所以相当于一个全局锁)
synchronized(obj){}同步块中
obj称为同步监视器;可以是任何对象,但是推荐使用共享资源作为同步监视器(修饰方法时,同步监视器就是this或是class)
底层实现
对象头的markword会关联到一个monitor对象(这个对象是用C++语言写的)
- 当我们进入一个方法的时候,执行monitor enter,就会获取当前对象的一个所有权,这个时候monitor进入数为1,当前的这个线程就是这个monitor的owner。
- 如果你已经是这个monitor的owner了,你再次进入,就会把进入数+1(每次重入加一)
- 同理,当他执行完monitor exit,对应的进入数就-1,直到为0,才可以被其他线程持有。
所有的互斥,其实在这里,就是看你能否获得monitor的所有权,一旦你成为owner就是获得者。
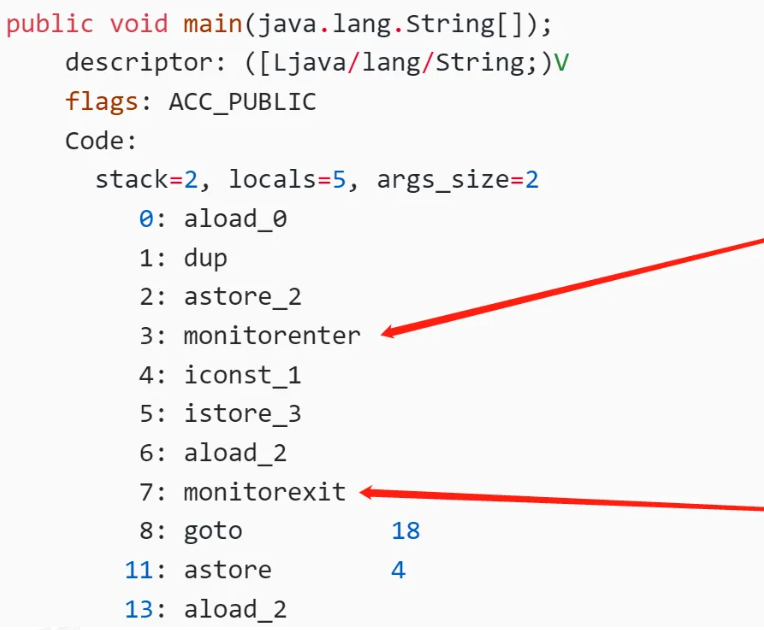
Synchronized修饰的方法在抛出异常时,会释放锁吗?
会
Lock
synchronized是悲观锁,无论线程是读还是写都会独占整个资源,因此出现了Lock接口
JUC下有locks包,这个包内,最常见就有ReentrantLock与ReentrantReadWriteLock

ReentrantReadWriteLock虽然没有实现Lock接口,但是他的两个静态内部类ReadLock与WriteLock均实现了Lock接口
Lock接口部分方法如下:
1 | void lock(); //若锁处于空闲状态,当前线程将获取到锁 |
注意:
当一个线程获取了锁之后(运行状态),是不会被
interrupt()方法中断的;除非调用的是lockInterruptibly()方法获取锁中断只能作用于处于WAITING状态的线程
因此使用锁的基本方式均为:
1 | Lock lock = ...; // 声明一个锁 |
ReentrantLock
ReentrantLock继承了Lock接口并实现了接口中定义的方法,是一种可重入锁
方法介绍:
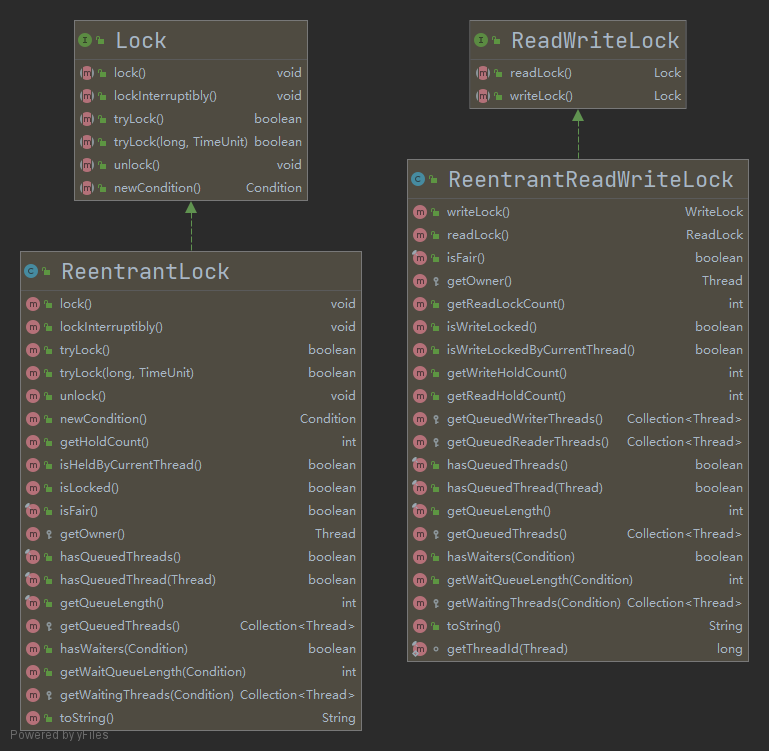
首先是实现了Lock接口的方法(上面已经介绍),其他是ReentrantLock自己的方法:
1 | getHoldCount(); //查询当前线程保持此锁的次数,也就是执行此线程执行 lock 方法的次数。 |
这里可以对比一下synchronized与ReentrantLock:
| 对比项 | synchronized | ReentrantLock |
|---|---|---|
| 如何加锁解锁 | JVM自动控制 | 程序员手动进行 |
| 是否公平 | 非公平锁 | 默认为非公平锁 |
| 是否可重入 | 可重入 | 可重入 |
| 发生异常 | JVM自动释放锁 | finally中手动释放锁 |
| 可中断锁 | 不可中断锁 | 可中断锁 |
总结:ReentrantLock对比synchronized主要增加了三项功能:
- 等待可中断:当持有锁的线程长期不释放锁时,正在等待的线程可以选择放弃等待,改为处理其他事情,它对处理执行时间非常长的同步块很有帮助(而在等待由
synchronized产生的互斥锁时,会一直阻塞,是不能被中断的) - 可实现公平锁:可以使用
new ReentrantLock(true)来使用公平锁 - 锁可以绑定多个Condition:
ReentrantLock对象可以同时绑定多个Condition对象(条件变量或条件队列);- 而在
synchronized中,锁对象的wait()和notify()或notifyAll()方法可以实现一个隐含条件,但如果要和多于一个的条件关联的时候,就不得不额外地添加一个锁 ReentrantLock则无需这么做,只需要多次调用newCondition()方法即可。而且我们还可以通过绑定Condition对象来判断当前线程通知的是哪些线程(即与Condition对象绑定在一起的其它线程)
demo:
1 | public class Test { |
ReentrantLock的源码实现
ReentrantLock内部其实是用AQS来保证的同步:
1 | // ReentrantLock成员变量,Sync实现了AQS |
1 | abstract static class Sync extends AbstractQueuedSynchronizer { |
默认使用非公平锁:
1 | static final class NonfairSync extends Sync { |
ReadWriteLock
读写锁将读操作与写操作进行分离:
1 | public interface ReadWriteLock { |
ReentrantReadWriteLock是ReadWriteLock的一个实现类,将读写操作分离:
满足四个原则:
- 允许多个线程一起读
- 只允许一个线程写
- 读时不能写(悲观读)
- 写时不能读
锁的降级与升级:支持锁降级(写锁变为读锁),但是不支持锁升级(读锁变为写锁)!
ReentrantReadWriteLock的Demo如下:
1 | public class ReadWriteLockDemo { |
Semaphore
Semaphore:信号量,是对具体物理资源的抽象
处理多个共享资源的问题
关于信号量的详细解释,可以看我的另一篇blog
注意:现有资源数目信号量S。P、V操作分别代表消费者(申请资源)、生产者(释放资源)
S == 1:信号量就变为互斥信号量S > 0:说明S资源还有S个S < 0:说明等待队列还有-S个进程阻塞着
Java中demo:
1 | // 信号量值为 3 |
可见信号量与ReentrantLock使用该方法基本一致
锁优化
有了锁虽然解决了线程安全问题,但是带来了性能的下降,此时就要进行锁优化了。
一般我们会有如下的锁优化方法:
- 减少锁持有时间:只在有线程安全问题的程序上加锁
- 减小锁粒度:将大对象拆成小对象,降低锁竞争
- 锁分离:根据功能分离锁,例如
ReadWriteLock,将读与写进行分离 - 锁粗化:通常情况下,为了保证多线程间的有效并发,会要求每个线程持有锁的时间尽量短。但是,凡事都有一个度,如果对同一个锁不停的进行请求、同步和释放,其本身也会消耗系统宝贵的资源,反而不利于性能的优化
- 锁消除:编辑器级别的事情,可以对没有共享需求的代码进行优化,直接消除锁,这些多半是程序员编码不规范引起的。
Volatile关键字
volatile本意是“易失的”,在计算机内代表,被这个关键字修饰的变量不会被缓存起来;
对于非volatile变量来说,访问它的值会先从内存copy到CPU cache中,如果刚copy完,内存中的值就发生了改变,那么CPU读到的是cache中的值,而不是最新值
对于volatile修饰的变量,每次都要去内存中读取
被这个关键字修饰的变量代表着两种特性:可见性与有序性
- 变量可见性:变量对所有线程可见(这里的可见性指:一个线程修改了变量的值,那么新的值对于其他线程是可以立即获取的)
- 禁止重排序:多核CPU会对指令进行重排序,以加快指令的执行速度,使用此关键字可以不让CPU这么做
优点:
比synchronized更轻量级的一个同步锁,不会使线程阻塞
volatile 适合这种场景:一个变量被多个线程共享,线程直接给这个变量赋值
注意:
- 被
volatile修饰的变量可以保证单次读/写操作的原子性 - 不能保证
i++这种操作的原子性,因为本质上其是两次操作 读+写 - 必须同时满足两个条件,才能保证线程安全:
- 对变量的写操作不依赖于当前值(
i++),或者说是单纯的变量赋值(类似flag = true,不是这种a += 10) - 该变量没有包含在具有其他变量的不变式中(不同的 volatile 变量之间,不能互相依赖)只有在状态真正独立于程序内其他内容时才能使用
volatile
- 对变量的写操作不依赖于当前值(
可见性与有序性实现的底层原理
底层是如何确保volatile的可见性的?
通过缓存一致性协议:不同厂商有不同协议,这里以牙膏厂的MESI为例:
当CPU写数据时,如果发现操作的变量是共享变量,会发出信号通知其他CPU将该变量的缓存行置为无效状态
底层是如何确保volatile的有序性的?
通过内存屏障,这是一个CPU指令,不能对其进行重排序,volatile就是基于内存屏障实现的
JUC通信工具类
| 类 | 作用 |
|---|---|
| Semaphore | 限制线程的数量 |
| Exchanger | 两个线程交换数据 |
| CountDownLatch | 线程等待直到计数器减为0时开始工作 |
| CyclicBarrier | 作用跟CountDownLatch类似,但是可以重复使用 |
| Phaser | 增强的CyclicBarrier |
Semaphore
用于资源有限的场景中,可以限制线程的数量
比如我想限制只有3个线程在工作:
1 | public class SemaphoreDemo { |
Exchanger
用于两个线程交换数据,数据支持泛型(所以我们可以传IO流之类的)
调用到exchange()方法,线程会进入阻塞状态,只有另一个exchange()
方法被调用,才会继续执行
核心方法:
exchange(E e):将数据交给另一个线程(会进入阻塞)
1 | final static Exchanger<String> ex1 = new Exchanger<>(); |
CountDownLatch
闭锁、或者叫门闩:在闭锁到达结束状态之前,这扇门一直是关闭的。可以用来等其他线程执行。
假设某个任务执行之前,需要等待其他线程完成一些任务,那么就可以用CountDownLatch类
主要的方法有:
new CountDownLatch(int count):构造方法,参数是一个int值,代表需要等待几个任务await():进入等待状态await(long time, TimeUnit unit):进入等待状态,如果count为0或者时间到也会释放getCount():获取当前count值countDown():让count值减1,如果count为0,就会自动解锁await
1 | public class CountDownLatchDemo { |
CyclicBarrier
栅栏,
CyclicBarrirer从名字上来理解是“循环的屏障”的意思。
前面提到了CountDownLatch一旦计数值count被降为0后,就不能再重新设置了,它只能起一次“屏障”的作用。
而CyclicBarrier拥有CountDownLatch的所有功能,还可以使用reset()方法重置屏障
1 | public class CyclicBarrierDemo { |
CopyOnWriteArrayList
并发编程时,使用ArrayList会遇到Concurrent Modification Exception并发修改异常,表明ArrayList不能在并发开发中使用
1 | public static void main(String[] args) { |
为了避免这个异常,我们有三种解决办法:
- 使用
Vector,这个类是线程安全的,但是效率极低 - 使用集合类的
synchronizedList方法 - 使用
CopyOnWriteArrayList,这是最佳的方法
CopyOnWrite:写入时复制(COW 计算机程序设计领域的一种优化策略)
ThreadLocal
ThreadLocal 线程本地变量:在同一线程,不同组件之间传递数据
当我们遇到这种情况:线程设置的变量只有自己读取(即保证线程隔离)
我们可以使用ThreadLocal也可以使用Synchronized,区别在于ThreadLocal并没有加锁,它的执行速度与效率会远远高于Synchronized。
Synchronized与ThreadLocal的区别:
- Synchronized
- 使用时间换空间
- 目的在于保证多个线程在操作共享资源时的顺序。
- ThreadLocal
- 使用空间换时间
- 目的在于保证多线程中数据隔离
作用:主要是实现了数据隔离,不同线程之间不会互相干扰
ThreadLocal的使用
ThreadLocal的使用非常简单,例如这个demo
1 | ThreadLocal<String> threadLocal = new ThreadLocal<>(); |
主要使用的方法就四个:构造方法、set、get、remove
ThreadLocal本身并不存储值,而是将值存储在Thread类的ThreadLocalMap中,ThreadLocalMap的key是ThreadLocal对象本身(注意:并不是Thread对象,而是ThreadLocal对象!!),value就是我们设置的值。
在看下面的例子:下面这个例子使用同一个ThreadLocal,互相之间不干扰不能获取到别人的值。
1 | ThreadLocal<Integer> threadLocal = new ThreadLocal<>(); |
ThreadLocal的定义
ThreadLocal与Thread的关系
- Thread类内部定义了两个ThreadLocalMap的引用
1 | // Thread类 |
- ThreadLocalMap的定义是在ThreadLocal类内部定义的
1 | // ThreadLocal类内部定义了静态内部类ThreadLocalMap |
- 使用ThreadLocal的set方法,实际上是使用了对应线程的ThreadLocalMap的set方法
1 | private void set(Thread t, T value) { |
- ThreadLocal会在第一次被使用时(get、set)去创建对应线程的ThreadLocalMap
ThreadLocal的原理
每一个Thread维护一个ThreadLocal,每一个Thread含有一个ThreadLocalMap
这个Map的key是ThreadLocal实例本身,value是我们想要设置的值

要想搞清楚ThreadLocal,首先看Thread类中含有两个属性均为ThreadLocalMap类型(这里先知道Thread类有这个属性即可)
1 | ThreadLocal.ThreadLocalMap threadLocals = null; |
再来看ThreadLocal的构造方法,很简单,与默认构造一样:
1 | public ThreadLocal() { |
在看get()方法:(下面的方法在ThreadLocal类中)
1 | public T get() { |
真正的get其实是由这里的getEntry()方法完成的:值得一提的是在ThreadLocalMap中是使用开放地址法处理哈希碰撞的
处理哈希碰撞的方法:
- 开放地址法:如果遇到哈希冲突,就重新寻找真正的存放数据的下标位置(重新计算哈希也有不同的方法)
- 线性探测(ThreadLocalMap就是这种方式):从此下标开始,挨个往下找
- 二次探测:探测步数是原始相隔位置的平方
- 再哈希法:用不同哈希函数再求一遍哈希值
- 链地址法:如果遇到哈希冲突,就拉一条链表出来。HashMap中就是使用这种方法进行处理的
- 建立公共溢出区:专门存放所有哈希碰撞后的数据
1 | private Entry getEntry(ThreadLocal<?> key) { |
(set()方法实现的原理与get()方法差不多,就不再赘述;)
Entry代码如下,注意继承了弱引用类:
弱引用 —— 发现即回收
特点:
- 只被弱引用关联的对象只能生存到下一次 GC 发生为止(无论内存是否足够)
- 由于垃圾回收线程的优先级很低,所以不一定很快被回收掉;这种情况可以存活较长时间
1 | static class ThreadLocalMap { |
ThreadLocal的内存泄漏问题
ThreadLocalMap定义在ThreadLocal内,但是实际上是Thread的成员。
Thread内含有ThreadLocalMap的强引用,一般来说ThreadLocalMap的生命周期是与Thread一致的。
但由于thread一般是复用的,因此Thread一般不会消亡,也就导致ThreadLocalMap不会消亡,即使对应Entry的key,也就是ThreadLocal被GC回收掉,其value也会存在,也就导致了内存泄漏。
ThreadLocal被设计为弱引用,是为了减少内存泄漏带来的影响,但是不能消除内存泄漏。
避免内存泄漏的方式:
- 底层设计有优化,在每次
get、set操作时,会自动清除key(也就是ThreadLocal)为null的Entry。但如果一直没有调用get、set方法,那么还是会有内存泄漏的问题。 - 养成良好习惯,每次使用完后手动调用
remove方法
InheritableThreadLocal
为了使得父子线程之间可以传递数据,引入了InheritableThreadLocal
1 | ThreadLocal<String> tl1 = new InheritableThreadLocal<>(); |
输出结果:
1 | main:main |
但注意,InheritableThreadLocal和线程池共同使用的时候,会出现问题,比如:
1 | InheritableThreadLocal<String> tl = new InheritableThreadLocal<>(); |
输出结果为:
1 | main:main1 |
注意到tl.set("main2");值没有发生作用,这是为什么呢?
main线程设置为
main1一开始线程池之中没有线程,在第一次使用线程池执行任务时,会创建线程
- 子线程会将父线程的
InheritableThreadLocalcopy到子线程的InheritableThreadLocal - 此后,子线程的InheritableThreadLocal与父线程其实就没有关系了
- 子线程会将父线程的
main线程更改值为
main2在下一次执行任务时,线程池的线程还是之前的线程(线程复用),由于其copy的map没有发生变化,因此其存的值还是
main1
因此,InheritableThreadLocal不能再线程池场景下使用
TransmittableThreadLocal
如果我们现在有一个场景,需要在多个线程之间(线程池)进行通信,可以使用TTL
注意:线程池需要使用TtlExecutors.getTtlExecutorService包裹:
1 | ExecutorService es = TtlExecutors.getTtlExecutorService(Executors.newFixedThreadPool(1)); |
此时再去运行,即正常:
1 | TransmittableThreadLocal ttl = new TransmittableThreadLocal(); |
输出结果为:
1 | main:main1 |
原理:TTL如何做到的?
核心有两点:
- 如何实现线程之间共享数据?
- 使用一个静态的
static ThreadLocal<Map>,静态成员属于类,以实现线程池之间共享
- 使用一个静态的
- 有线程更改数据,那么在什么时候进行数据传递?
- 任务的执行都是一个
Runnable接口实现的方法,TTL额外实现了一个集成Runnable接口的类,在线程池调用run方法之前进行ThreadLocal的copy,在执行完成后进行复原 - 这也是为什么要使用
TtlExecutors.getTtlExecutorService包裹一下线程池的原因
- 任务的执行都是一个
对应源码:TtlRunnable源码
1 | public void run() { |
TL、ITL、TTL之间的关系
从左到右依次继承:InheritableThreadLocal继承了ThreadLocal,TransmittableThreadLocal继承了InheritableThreadLocal
总结
Thread维护了一个MapThreadLocalMap,这个Map的key是ThreadLocal,value是我们想要设置的值ThreadLocalMap是每个Thread都拥有的一个属性ThreadLocalMap是ThreadLocal线程的内部类ThreadLocalMap中Entry的key是ThreadLocal类,而且是弱引用(有内存泄露的风险)ThreadLocalMap中避免哈希碰撞的方法是开放地址法 + 线性探索ThreadLocalMap与synchronized都可以进行数据隔离,区别是ThreadLocal使用空间换时间,synchronized则相反
详解
此部分关于AQS、CountDownLatch、ReentrantLock等的源码级理解
AQS
AQS抽象同步队列是一个抽象类,Java的ReentrantLock、CountDownLatch都是AQS实现的。
AQS提出一个这样的模型:一个共享变量state,以及一个双向链表CLH队列,每一个请求资源的线程,都会被封装成一个CLH队列的结点
关键实现
state 状态:
1 | private volatile int state; |
有三个方法可以操作这个状态的值:
1 | protected final int getState() { |
数据结构
AQS是将每条请求共享资源的线程封装成一个CLH锁队列的一个结点(Node)来实现锁的分配。其中Sync queue,即同步队列,是双向链表,包括head结点和tail结点,head结点主要用作后续的调度。
而Condition queue不是必须的,其是一个单向链表,只有当使用Condition时,才会存在此单向链表。并且可能会有多个Condition queue。
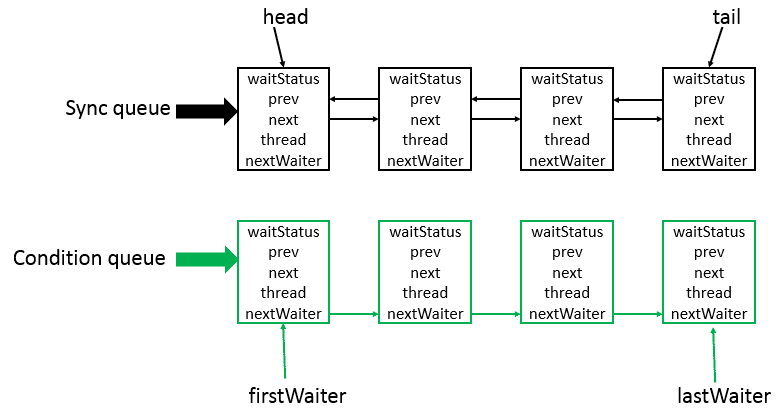
AQS有两个内部类Node和ConditionObject
1 | final boolean transferForSignal(Node node) { |
锁共享方式
- 互斥锁:只有一个线程可以执行,比如ReentrantLock就是这样的实现
- 共享锁:多个线程可以同时执行,比如CountDownLatch
自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS已经在上层已经帮我们实现好了(模版方法模式)
1 | isHeldExclusively()//该线程是否正在独占资源。只有用到condition才需要去实现它。 |
Node的状态
AQS的每一个Node,都是一个Thread的包装,AQS为什么是一个双向链表,是因为AQS需要通过前继节点来判断当前节点的行动:
Node有这几种状态
1 | static final int CANCELLED = 1; // 指示当前线程被取消执行 |
如果Node是非负数表示均不需要被激活
注意:特别注意
- SIGNAL:意思表示,后续节点被park了,在当前节点在释放或是取消时,一定要唤醒后续节点
- CANCEL:由于超时或是中断,此节点被取消执行了!
- CONDITION:表示处于条件队列中,在条件没有满足的时候,不会进入同步等待队列
- PROPAGATE:共享模式的特有状态,用于传播唤醒状态
AQS为什么得用一个双向链表?为什么不用单向链表?
因为AQS中多次使用到了前继节点:
使用前继节点的状态,来判断当前节点的行为,比如前继节点为SIGNAL,就表示前继节点在释放或是取消的时候,千万要唤醒后继节点
SIGNAL状态也就意味着,只有前继节点才能唤醒后继节点
tryAcquire与acquire方法
加锁实际是由底层的acquire方法实现的:
1 | public final void acquire(int arg) { |
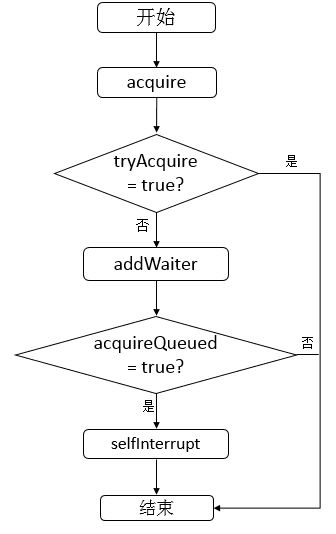
- 首先调用
tryAcquire获取,如果能获取成功,直接结束,如果没能获取成功就执行2 - 执行
addWaiter方法,将当前的Thread包装为一个Node节点,放在链表的尾部,执行3 - 调用
acquireQueued,下面列出代码:- 不断轮训
- 首先:获取当前Node的前继节点,如果前继节点为head并且获取到了资源,那么表示自己可以执行了
- 然后:判断前继节点的运行状态,根据不同状态执行不同操作
shouldParkAfterFailedAcquire- 如果前继节点的状态为CANCELLED(说明线程取消执行),则进行下一次循环
- 如果前继节点状态为SIGNAL,就表示当前节点需要park(也就是进入等待状态),返回True
- 如果需要park线程,那么就调用
parkAndCheckInterrupt,也就是LockSupport.park()
1 | final boolean acquireQueued(final Node node, int arg) { |
1 | // 在获取锁失败后,是否要被park呢? |
返回
true的情况:如果前驱节点的状态为SIGNAL,则表明当前线程应该阻塞(park),等待前驱节点唤醒它。返回
false的情况:如果前驱节点的状态不是SIGNAL,则当前线程暂时不会阻塞,还需要进一步处理。可能是因为前驱节点被取消,需要跳过,或者前驱节点还没有设置为SIGNAL状态,需要进行状态更新。
tryRelease与release方法
释放锁也是调用tryRelease,如果释放成功就唤醒后继节点
1 | public final boolean release(int arg) { |
AQS实现简单的独占锁
AQS内部类部分:
- tryAcquire:用cas判断当前状态,如果获取到了就设为独占setExclusiveOwnerThread
- tryRelease:首先判断状态是不是unlock,清除独占,设置state为unlock
1 | static class Sync extends AbstractQueuedSynchronizer { |
外部实现Lock:
1 | public class AqsLock implements Lock { |
tryAcquireShared与acquireShared方法
在共享锁中,state的数字就有了意义,他表示资源的个数:
1 | tryAcquireShared(int)//共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。 |
同独占锁的实现,共享锁也是这样:
1 | public final void acquireShared(int arg) { |
如果获取失败,调用下面的方法,与独占锁的acquireQueued方法很像,他们的主要区别在于setHeadAndPropagate()方法
1 | private void doAcquireShared(int arg) { |
与独占锁的区别就在于下面这个方法,独占锁直接setHead(node),而共享锁还会尝试唤醒后继节点
1 | private void setHeadAndPropagate(Node node, int propagate) { |
需要唤醒后面节点的条件有:
propagate > 0:如果propagate大于 0,表示需要继续传播唤醒后续线程。h == null:如果旧的头节点h为空,说明队列之前为空,需要唤醒新的节点。h.waitStatus < 0:如果旧的头节点的状态是负数,表示头节点处于等待状态(通常为SIGNAL),表明可能有后续节点需要被唤醒h = head:再次检查当前的头节点是否已经发生变化。h.waitStatus < 0:再次检查新的头节点状态。
tryReleaseShared与releaseShared方法
1 | public final boolean releaseShared(int arg) { |
1 | private void doReleaseShared() { |
AQS要点总结
1、AQS有两个内部类Node和ConditionObject
2、AQS同步队列是一个双向链表,条件队列是一个单向链表
3、AQS的Node包裹了一个Thread,只有head才有执行的权利,而且只有head才能唤醒后继节点
4、Node的SIGNAL状态表示,后继节点处于park,当前节点释放时,一定要激活后继节点(unpark后继节点)
5、Condition满足后,会调用transferForSignal从条件队列转移到同步队列
6、acquire的流程为:tryAcquire(尝试获取一次)->addWaiter(包装为Node添加到队列)->acquireQueued(判断前继节点状态,决定当前节点行为)
7、当前继节点为SIGNAL,表示当前节点会在前继节点释放时被唤醒;前继节点为CANCEL,表示会直接跳过前继节点;前继节点propagate,表示处于传播状态,可以无条件唤醒后继节点(用于共享模式);
8、AQS有两种同步方式:共享和独占。独占的实现类有ReentrantLock,共享的实现类有CountDownLatch。
9、共享模式实现方式与独占差不多,区别在于是否可以传播唤醒后继节点
CountDownLatch
问题
1、CountDownLatch适用于什么场景?
CountDownLatch典型的用法是将一个程序分为n个互相独立的可解决任务,并创建值为n的CountDownLatch。
2、CountDownLatch的实现原理是什么?
当每一个任务完成时,都会在这个锁存器上调用countDown,等待问题被解决的任务调用这个锁存器的await,将他们自己拦住,直至锁存器计数结束
这个计数器是用AQS的state实现的,使用了AQS的共享模式,每次获取资源都调用tryAquireShared模式,每次释放资源都调用tryReleaseShared。
Demo:七颗龙珠召唤神龙
当某一个线程需要等待N个线程执行完成时,就使用
1 | public class DragenBall implements Runnable{ |
实现原理
利用了AQS的共享模式,内部使用state作为count的数量,每次CountDown就释放一个资源
1 | tryAcquireShared(int)//共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。 |
CountDownLatch有一个内部类继承了AQS:
1 | private static final class Sync extends AbstractQueuedSynchronizer { |
CountDownLatch的其他部分很简单:关键看await()与countDown实现
1 | public class CountDownLatch { |
ReentrantLock
问题
1、ReentrantLock是什么锁?
可重入的、可公平可不公平、悲观锁
2、ReentrantLock是如何实现可重入的?
通过state状态维护可重入次数,每次tryAcquire时:
- 如果没有被占据,就获得锁
- 如果被占据,判断是不是当前线程占据,如果是的话,就将state+acquire次数,就实现了重入
3、ReentrantLock是如何实现公平与非公平的?
- 非公平锁:tryAcquire时,直接cas判断(直接抢占)
- 公平锁:tryAcquire时,会先判断head后是否有线程,如果有,就说明存在比自己等待时间长的线程。
4、对比Synchronized的有什么区别?
Synchronized:加锁syn(obj)、进入等待obj.wait()、obj.notify()、obj.notifyAll()- 实现方式:加锁解锁JVM自动实现,通过JVM内部的monitor对象,
- 可重入:调用字节码
monitor_enter和monitor_exit实现可重入 - 公平锁与非公平锁:只支持非公平锁
- 条件:条件只能使用obj进行判断,不支持多个条件
- 锁粒度:1.5之前直接为重量级锁,之后引入了锁升级过程,但还是独占锁,读写不分离
ReentrantLock:加锁lock()、解锁unlock()、进入等待condition.await()、唤醒condition.signal()- 实现方式:加锁解锁使用AQS,同步队列+条件队列
- 可重入:
state状态存储重入次数,tryAcquire时判断是否是当前线程重入 - 公平锁与非公平锁:支持公平锁,默认非公平锁
- 条件:通过
ConditionObject对象及条件队列实现,满足条件后,调用signal()将Node传送给同步队列 - 锁粒度:独占锁,读写不分离
内部结构
内部集成关系,由一个静态内部类继承AQS(大部分都是这么实现的),然后又有两个静态内部类分别集成Sync,实现公平锁与非公平锁。
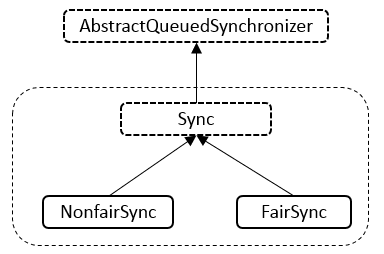
Sync类
Sync类实现了非公平的获取方式,tryAcquire在子类中实现。
下面是源码,可以看到可重入的实现方式:
- 如果没有线程占据锁,那么就获得
- 如果当前线程就是获取了锁的线程
current == getExclusiveOwnerThread(),可以再次获得,将state+acquires次数
1 | abstract static class Sync extends AbstractQueuedSynchronizer { |
NonFairSync
NonfairSync直接调用Sync的获取方式即可
1 | static final class NonfairSync extends Sync { |
FairSync
公平锁如何实现?
在tryAcquire方法中,并不像非公平锁一样,直接调用cas,而是先判断当前同步队列是否有节点
(如果有节点,就说明该线程等待的时间比当前线程时间要长)
1 | static final class FairSync extends Sync { |
这里看下hasQueuedPredecessors方法:
如果当前head后有节点(说明有线程在等待,且不是当前线程在等待),那么返回true
1 | public final boolean hasQueuedPredecessors() { |
ReentrantReadWriteLock
问题
1、为什么有ReentrantLock还要引入ReentrantReadWriteLock
对于大部分操作来说,读写的要求是不一致的,读锁可以一起读,写锁只能一个线程写,而ReentrantLock是悲观锁,不论读写都会锁住,不利于提高读操作的并发性。
2、如何实现的读写分离?
ReentrantReadWriteLock在内部实现了读锁与写锁,读锁使用共享模式的AQS,写锁使用独占模式的AQS。
- 写锁:状态存放在AQS的state的低16位,如果低16位不为0,表示写锁已被获取
- 读锁:读锁状态存放的位置有state的高16位以及ThreadLocalHoldCounter的HoldCounter,他存放了所有线程的读锁数量。
获取写锁时,是如何判断有没有读锁的?通过判断state和写锁(低16位),如果state==0但是写锁数不为0,那么就存在读锁。
3、本地线程计数器ThreadLocalHoldCounter是做什么的?
存放不同的线程的读锁的计数状态(没有存放写锁的状态)
4、缓存计数器cachedHoldCounter是做什么的?
避免每次都去读取ThreadLocal,存放当前线程的读锁计数,是一个优化机制
6、支持锁升级吗?为什么?
不支持,为了避免:
- 防止死锁:如果有多个线程获取了读锁,然后想获取写锁,都会等待对方释放读锁,就会形成死锁问题
- 为了避免数据不一致:多个线程获取了读锁,一个线程还获取了写锁,那么这个线程的写入操作对其他线程不可见
7、支持锁降级吗?为什么?
支持锁降级,可以保证数据一致性,获取写锁后获取读锁,再释放写锁,可以保证前后读取到的数据一致,不会有其他线程进行更改。
内部结构

内部有五个类:Sync、Fair、NonfairSync;Lock、ReadLock、WriteLock
ReadLock与WriteLock
先从读写锁开始介绍,因为ReentrantReadWriteLock本质是一个锁
- ReadLock:调用Sync的acquireShared与releaseShared
- WriteLock:调用Sync的acquire与release
均调用了Sync,重点去看Sync的获取方法
1 | public static class WriteLock implements Lock, java.io.Serializable { |
1 | public static class ReadLock implements Lock, java.io.Serializable { |
Sync
Sync同样是一个继承了AQS的静态内部类,其内部还有两个类:
- HoldCount:一个计数器,专门用于计算读锁的个数
- ThreadLocalHoldCounter:继承了ThreadLocal,而且存储HoldCount
1 | abstract static class Sync extends AbstractQueuedSynchronizer { |
Sync如何进行计数?AQS的state中的高16读低16写
1 | static final int SHARED_SHIFT = 16; |
Sync构造时,就会创建本地线程计数器ThreadLocalHoldCounter
1 | private transient ThreadLocalHoldCounter readHolds; |
这里中断介绍一下四个成员:
- readHolds:ThreadLocal对象,保存了每一个线程的HoldCounter,也就是保存了每个线程的读锁的个数
- cachedHoldCounter:缓存当前线程的读锁个数(因为查找ThreadLocal会有开销)
- firstReader:跟踪第一个获取读锁的线程,是一个优化手段
- firstReaderHoldCount:第一个读取锁线程的读锁个数,配合firstReader使用
Sync的写实现
写锁调用Sync的acquire与release:
写锁的实现与普通的独占锁实现基本一致,有几个比较关键的点:
- 如果当前state不为0,但是写锁为0,表示有读锁,那么直接返回false
- 多了一个判断当前是否存在独占锁的逻辑,是否存在独占锁是通过判断state的低16位判断的。而且不允许数量超过2^16
1 | protected final boolean tryAcquire(int acquires) { |
writerShouldBlock:
- 对于公平锁操作,会判断同步队列头部是否有线程等待
hasQueuedPredecessors - 对于非公平锁,直接返回false,写锁应该一直允许抢占
写锁的释放
1 | protected final boolean tryRelease(int releases) { |
Sync的读实现
读锁(共享锁)调用Sync的acquireShared与releaseShared:
1 | protected final int tryAcquireShared(int unused) { |
readerShouldBlock:
- 对于公平锁操作,会判断同步队列头部是否有线程等待
hasQueuedPredecessors(与写锁一样) - 对于非公平锁,会判断同步队列第一个线程是否是独占锁,如果是返回true
firstReader:
firstReader是一个Thread的指针,指向第一个获取读锁的线程
firstReaderHoldCount是获取读锁的锁数量的计数
使用firstReader与firstReaderHoldCount是为了在一般情况下,避免遍历ThreadLocal的开销
cachedHoldCounter:
cachedHoldCounter保存当前线程的读锁个数
值得注意的是,如果线程已经获取了写锁,那么依然可以获取读锁,这意味着ReentrantReadWriteLock支持锁降级
锁升级与锁降级
锁升级与锁降级指的是:
- 锁升级:在已有读锁的情况下,获取写锁,然后释放读锁
- 锁降级:在已有写锁的情况下,获取读锁,然后释放写锁
锁降级的好处:
对于锁降级来说,如果我们先释放写锁,在获取读锁,那么这个过程可能数据就会变动,造成前后数据读取不一致,因此锁降级可以支持前后数据读取一致性
ReentrantReadWriteLock支持锁降级,但不支持锁升级,原因是:如果当前有很多线程持有读锁,其中一个线程进行了锁升级,那么他的写入改动,对其他已经获取读锁的线程是不可见的。
Excutor的四种线程池实现
- SingleThreadExecutor:1个核心线程和最大线程,阻塞队列无限
1 | public static ExecutorService newSingleThreadExecutor() { |
- newFixedThreadPool:固定大小,核心与最大线程相同,阻塞队列也是无限
1 | public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) { |
- CachedThreadPool:0核心数量,但是最大线程无限,适合于短期的大量短任务,60秒后会自动释放线程
1 | public static ExecutorService newCachedThreadPool() { |
如果任务数量过多且执行速度较慢,可能会创建大量的线程,从而导致 OOM
SynchronousQueue是一个继承了AQS的同步队列,没有容量,不存储元素。
- ScheduledThreadPool:最大线程数也是无限,阻塞队列是DelayedWorkQueue也无界
1 | public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { |
线程池总结:
- SingleThreadExecutor、newFixedThreadPool、ScheduledThreadPool的阻塞队列都是无界的,如果请求堆积,容易引起OOM
- CachedThreadPool的阻塞队列虽然不存储元素,但是他的最大线程数无限,如果短期来了大量任务且执行时间长,也会出现OOM
线程池用的阻塞队列总结:
- LinkedBlockingQueue,无界队列,如果任务堆积有可能OOM
- SynchronousQueue:同步队列,是AQS的实现,不存储元素
- DelayedWorkQueue:延迟阻塞队列,内部是一个堆,按照执行时间排序,会自动扩容,也是无界的
ThreadPoolExecutor
核心数据结构
核心数据结构是一个阻塞队列+Worker的hashset
1 | private final BlockingQueue<Runnable> workQueue; // 阻塞队列 |
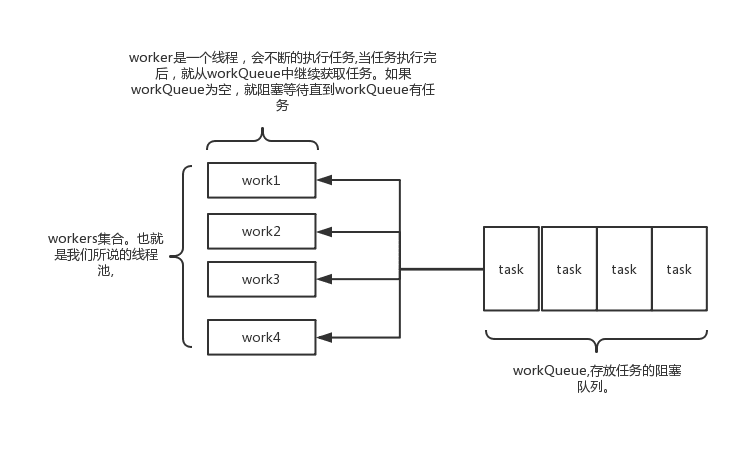
worker就是一个继承了AQS、实现了Runnable接口的包裹了Thread的内部类:
1 | private final class Worker |
ctl状态
线程池使用一个AtomicInteger来控制状态,它包括两个概念workercount和runState
1 | private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); |
- workercount:线程池最大数量是2^29-1(高三位表示状态)
- runState:高三位表示状态
1 | private static final int COUNT_BITS = Integer.SIZE - 3; // 32 - 3 = 29 |
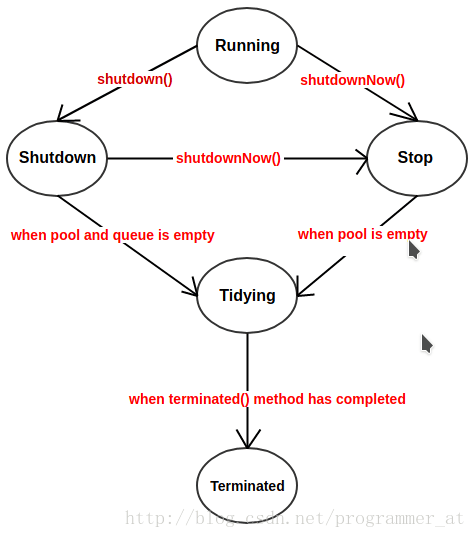
线程池的状态有:
1 | private static final int RUNNING = -1 << COUNT_BITS; |
execute方法
1 | public void execute(Runnable command) { |
addWorker方法
addWorker(command, true):传入两个参数,分别是Runnable任务与bool,为true表示创建核心线程执行,为false表示创建非核心线程执行。
- 创建新线程需要全局锁ReentrantLock
详细代码如下:
1 | private boolean addWorker(Runnable firstTask, boolean core) { |
在addWorker里调用了t.start()方法,也就是调用worker的run方法!
runWorker方法
worker是实现了Runnable接口的,在run方法中调用了runworker方法:
1 | final void runWorker(Worker w) { |
w.unlock():在创建完worker的时候,设置了state为-1(看构造函数),是为了防止在初始化未完成前被中断,这里unlock,解锁,将aqs的state变为0。此时就支持了被中断的能力getTask():会获取当前阻塞队列的任务,也有判断线程是否销毁的逻辑task.run();:真正执行run方法的位置
getTask方法
下面看一下getTask,是如何获取队列任务,并且抛出异常的:
allowCoreThreadTimeOut:是否允许核心线程过期?可以设置这个值,让核心线程也去销毁workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS):在keepAliveTime时间内阻塞,除非获取到元素workQueue.take():一直阻塞,直到可以获取出数据
线程是如何超时被销毁的?
在getTask方法中通过workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)获取任务,如果任务为空,就标记超时为true,在下一次循环中就会销毁线程
1 | private Runnable getTask() { |
线程池的关闭问题
线程池有shutdown()和shutdownNow()方法,原理是遍历线程池中规定工作线程,然后逐个调用线程的interrupt方法来中断。
- shutdown:不会立即停止,会停止接受外部任务,等待队列的任务执行完成后,才停止
- shutdownNow:停止接受任务,忽略队列等待的任务,尝试中断正在执行的任务(不一定会立马停止)
线程池总结
- ThreadPoolExecutor的结构:
- 一个
AtomicInteger的状态,高3bit表示线程池状态,低29位表示当前线程池数量 - 一个
HashSet<Worker>,线程池存储线程使用了一个set BlockingQueue<Runnable>,任务的阻塞队列- Worker:其内部有一个线程,还是一个继承了AQS,实现了Runnable接口的类,既可以保证自己给自己加锁,又能执行任务,他的run方法的实现调用了
runWorker方法,
- 一个
- 调用链路:ThreaPoolExecutor中的executor方法->addWorker方法->getTask获取任务
executor(Runnable command)方法:根据不同逻辑(核心线程数量与当前线程数量的关系),调用addWorker方法addWorker方法:addWorker负责Worker的线程的创建逻辑,创建时会以ReentrantLock加锁的逻辑,线程由线程工厂创建,创建完成后,将worker添加到set内,最后会执行t.start()方法,也就是执行了run方法,也就是执行了runWorker方法。runWorker方法:runWorker方法真正调用了任务的run方法,并且可以添加一些前后的处理逻辑,执行时后不断调用getTask方法获取任务,执行任务时,使用worker的AQS lock与unlock方法进行加锁。getTask方法:获取阻塞队列的任务,主要通过两个方法poll与take,poll中有保活时间,如果获取到的任务为null,说明当前线程空闲,下一次循环就会被销毁。而且还可以设置allowCoreThreadTimeOut为true,核心线程也会在空闲时被销毁。
简而言之:线程池的工作流程是,在任务传入后,调用executor方法,executor方法会判断线程数与核心线程数的关系,考虑是否创建Worker,创建Worker调用addWorker方法,创建后会将Worker放入线程池set内,然后执行线程的start方法,由于Worker实现了Runnable接口,重写了run方法,也就是调用了runWorker方法,runWorker方法会不断的调用getTask获取任务,getTask方法通过阻塞队列的poll与take方法获取任务,其中poll方法有保活时间,如果保活时间内都没有获取到任务,说明当前线程空闲,就会被销毁。