HTTP协议
HTTP知识点总结
这里总结所有HTTP知识点
- HTTP是一个半双工协议(通信双方只能有一人说话)
- HTTP不需要连接(虽然底层TCP需要连接)
- HTTP无状态
- HTTP端口80;HTTPS端口443
- HTTP请求报文由请求行、请求头、请求空行、请求体组成
- 请求行组成:请求方法 URL HTTP版本(例如
GET www.baidu.com HTTP/1.1) - 重要的请求头字段:
Referer防盗链、Cookie、Connection请求完成后是否断开 - GET与POST区别:是否可见、是否有请求体、是否有长度限制、是否幂等、是否安全(幂等:无论调用几次结果都一样;安全:请求不会破坏服务器资源)GET幂等安全、POST不幂等不安全
- HTTP响应报文由响应行、响应头、响应空行、响应体组成(如
HTTP/1.1 200 ok) - 重要的状态码:1xx中间状态需后续操作、200一切正常、301资源永久重定向、302资源临时重定向(会将POST转化为GET)、307与302相同(但不会转变为GET)、403禁止访问、404资源找不到、5xx服务器端错误
- 重要的响应头字段:
Set-Cookie提醒浏览器设置Cookie、Connecion、Location要跳转到哪个网页 - HTTP1.0缺点:非持续连接(每次都会断开)、每次只能发送一个请求,等待响应后才能发第二个;队头阻塞(一个Http阻塞会阻塞之后的所有请求)、明文传输、不会检查身份、无法检验信息是否完整、请求/响应头没有压缩
- HTTP1.1改进:持续连接、管道网络传输(可以发完一个再发一个,是按序接收请求的,即没有优先级)、加入Cookie(解决无状态);仍存在的问题:明文传输、请求/响应头没有压缩、队头阻塞、没有优先级控制
- HTTPS:加了SSL/TSL(传输层安全协议)
- HTTPS:通过三个手段解决HTTP明文传输问题:混合加密(解决不安全)、摘要算法(解决信息不完整)、数字证书
- 对称加密:使用相同秘钥进行加密;不对称加密:各自持有私钥加密
- HTTPS采用的加密方式:通信建立前用不对称加密(安全)、通信中用对称加密(速度快)
- 摘要算法:用摘要算法算明文的指纹(指纹:即明文的一部分信息)来校验完整性
- 数字证书CA:第三方机构,存放公钥
- HTTPS建立过程:首先客户端访问服务器;服务器返回数字证书;客户端检查数字证书合法性并提取出公钥;使用公钥加密后发送给服务器;服务器使用私钥解密,提取指纹;之后一直使用指纹加密;
- HTTP2.0优化:头部压缩(HPACK算法)、传输二进制格式、不按顺序发送(客户端发出的编号为奇数、服务器端发出的编号为偶数)、解决了队头阻塞(并发的进行响应)、服务器开始可以向客户端发送消息
- HPACK算法:在客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,以提高速度
- 服务器推送:在浏览器刚请求 HTML 的时候,就提前把可能会用到的 JS、CSS 文件等静态资源主动发给客户端,减少延时的等待
- HTTP2.0缺点:HTTP2.0多请求复用一个TCP连接,如果丢包会阻塞所有的HTTP请求(使用TCP的短板)
- HTTP3.0:使用UDP协议作为底层,用QUIC协议保证可靠
- QUIC协议:解决了UDP不可靠的缺点
前言
最近在复习Servlet的过程中,突然感觉自己的HTTP协议忘光光了,于是就写了这篇,参考了很多大牛的博客以及《计算机网络 自顶向下方法》这本书
如遇错误,纯属正常,望请指正
前置知识
再开始学习HTTP之前,我们需要几个前置的知识,来保证之后我们之后的学习不会出了问题
计算机网络体系结构
众所周知,ISO提出了7层模型,但是这只是理论上的,实际上,我们平常所使用的是5层结构:(从底层到最上层)
- 物理层
- 数据链路层
- 网络层
- 传输层
- 应用层
例如我们这篇博客要学习的HTTP就是应用层的一层协议,同是应用层的还有DNS(一个解析域名的协议,并不是我们今天的重点,不过后面会提到,先混个脸熟)
而TCP协议就是传输层的
网络层有IP协议
通信分类
- 单工协议:单向传输:例如电视机、广播
- 双工协议:双向传播
- 半双工:同一时刻只能有单向通信,如对讲机
- 全双工:允许双方通信,如手机通话
TCP
运输层的一个协议,当你使用浏览器访问百度时,他们之间会首先的建立起一个TCP连接,TCP连接是通过三次握手和四次挥手来建立连接和失去连接的,TCP是一个全双工的协议,TCP很重要,但不是今天的主角
其他的就先不聊了,我们正式开始学习HTTP
HTTP
为什么要学习HTTP
当你使用一个浏览器,去访问百度时,百度的服务器就会给你响应,他们之间是通过HTTP协议来交流的
我们要写一个项目,进行前后端的交接,当你的电脑访问它的电脑时,也是通过HTTP协议来交流的
HTTP是什么
HTTP (HyperText Transfer Protocol)超文本 传输 协议,我们从三个名词来了解HTTP
什么是协议?
一种规范,人与人之间的约定就叫协议,同样计算机之间的约定就叫协议。
HTTP是一个半双工,意味着同时只能有一方说话。
HTTP是应用层的一层协议,应用层是计算机网络体系结构的最高层,意味着,这一层可以不去管底层是怎么控制的,底层可以进行更换,这一点我们之后会更加深入的去谈。
什么是传输?
传输字面意思从A点到B点运输,在HTTP中我们要求的A点和B点,分别是客户端和服务器
什么是超文本?
不仅仅局限于文字,图片、视频、音乐、压缩包等等都是超文本
HTTP定义很简单,首先我们要有两个端(客户端+服务器),其次就是他们之间通过HTTP报文进行会话,满足这两个要求就是HTTP,浏览器就是实现了HTTP的客户端,假设我们要连接一个服务器,现在我们就只差HTTP报文来交流了
HTTP报文
HTTP请求报文
由这么四个部分组成:
- 请求行:
方法 URL 版本 - 请求头(首部行):
字段 值 - 请求空行:一个空行
- 请求体(实体体)
方法有哪几种?
GET: 用于请求访问已经被URI(统一资源标识符)识别的资源,可以通过URL传参给服务器POST:用于传输信息给服务器,主要功能与GET方法类似,但一般推荐使用POST方式。PUT: 传输文件,报文主体中包含文件内容,保存到对应URI位置。HEAD: 获得报文首部,与GET方法类似,只是不返回报文主体,一般用于验证URI是否有效。DELETE:删除文件,与PUT方法相反,删除对应URI位置的文件。OPTIONS:查询相应URI支持的HTTP方法。
在这里我们要注意几个地方:
- 首先GET方法虽然是一个获取资源的方法,尽管他没有请求体(或者说它的实体体为空),但他依然可以传输数据,经常网络冲浪的你可能会见到
www.abc.com/getstudent?stu=1,机智的GET方法依靠这样的方式机智的传了数据,但是这样的方法有两个缺点:- 请求行的内容大小有限,通常限制在几k(不同的浏览器和服务器的限制会不同)
- 请求的参数裸奔。。。
- 最主要的方法有GET和PUT,由于REST ful,PUT和DELETE也开始用了起来。
- 有些刁钻的面试官会问,GET和POST哪个是幂等的?哪个是安全的?我们丝毫不慌,和他说,GET是幂等和安全的,POST不幂等也不安全(幂等:无论调用几次,结果都一样;安全:请求不会破坏服务器资源)
请求头的字段和值有哪些?
- Accept:
text/html,image/*【浏览器告诉服务器,它支持的数据类型】 - Accept-Charset: ISO-8859-1 【浏览器告诉服务器,它支持哪种字符集】
- Accept-Encoding: gzip,compress 【浏览器告诉服务器,它支持的压缩格式】
- Accept-Language: en-us,zh-cn 【浏览器告诉服务器,它的语言环境】
- Host: www.yesyourhighness.github.io 【浏览器告诉服务器,它的想访问哪台主机】
- If-Modified-Since: Tue, 11 Jul 2000 18:23:51 GMT【浏览器告诉服务器,缓存数据的时间】
- Referer: http://www.yesyourhighness.github.io 【浏览器告诉服务器,客户机是从那个页面来的—反盗链】
- User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0)【浏览器告诉服务器,浏览器的内核是什么】
- Cookie【浏览器告诉服务器,带来的Cookie是什么】
- Connection: close/Keep-Alive 【浏览器告诉服务器,请求完后是断开链接还是保持链接】
- Date: Tue, 11 Jul 2000 18:23:51 GMT【浏览器告诉服务器,请求的时间】
这么多,好慌啊,怎么办呢?
我把几个重要的标记了一下,其他的先混个脸熟,以后真见到了再看看也不迟
响应报文
由这么几个部分组成
- 响应行:
版本 状态码 描述 - 响应头(首部行):
字段 值 - 空行:一个空行
- 响应体(实体体)
状态码的值有哪些?
- 1xx 提示信息,表示目前是中间状态还需要后续的操作
- 2xx 成功信息
- 200 OK 一切正常,而且非HEAD请求会有body数据
- 204 No Content 成功,响应头没有body参数,即服务器没有新数据返回,页面不刷新
- 206 Partial Content 分块下载或断电续传,表示返回的body只是一部分
- 3xx 重定向,资源位置变动,需要客户端重新请求
- 301 Moved Permanently 请求的资源已分配了新的URI中,URL地址改变了。【永久重定向】
- 302 Found 请求的资源临时分配了新的URI中,URL地址没变【转发】会把POST请求变成GET
- 303 See other 与302相同的功能,但明确客户端应该采用GET方式来获取资源
- 304 Not Modified 发送了附带请求,但不符合条件【返回未过期的缓存数据】
- 307 Temporary Redirect 与302相同,但不会把POST请求变成GET
- 4xx 客户端错误,请求有误
- 400 Bad Request 客户端请求的报文有错误 ,是一个笼统的状态码
- 401 Unauthorized 需要认证身份
- 403 Forbidden 没有访问权限,服务器禁止访问资源
- 404 Not Found 请求的资源在服务器上不存在或未找到
- 5xx 服务器错误,服务器处理出现错误
- 500 Internal Server Error 服务器发生错误,笼统状态码
- 501 Not Implemented 客户端请求的功能目前还不支持,类似即将开业的意思
- 502 Bad Gateway 服务器作为网关或代理返回的错误码
- 503 Service Unavailable 服务器当前正忙,暂时无法响应
- 505 HTTP Veision Not Surported 服务器不支持请求报文所使用的HTTP协议版本
响应头的字段和值有哪些?
- Location: http://www.yesyourhighness.github.io 【服务器告诉浏览器要跳转到哪个页面】
- Server:apache tomcat【服务器告诉浏览器,服务器的型号是什么】
- Content-Encoding: gzip 【服务器告诉浏览器数据压缩的格式】
- Content-Length: 80 【服务器告诉浏览器回送数据的长度】
- Content-Language: zh-cn 【服务器告诉浏览器,服务器的语言环境】
- Content-Type: text/html; charset=GB2312 【服务器告诉浏览器,回送数据的类型】
- Refresh: 1;url=http://www.it315.org【服务器告诉浏览器要定时刷新】
- Content-Disposition: attachment; filename=aaa.zip【服务器告诉浏览器以下载方式打开数据】
- Transfer-Encoding: chunked 【服务器告诉浏览器数据以分块方式回送】
- Set-Cookie:SS=Q0=5Lb_nQ; path=/search【服务器告诉浏览器要保存Cookie】
- Cache-Control: no-cache 【服务器告诉浏览器不要设置缓存】
- Pragma: no-cache 【服务器告诉浏览器不要设置缓存】
- Connection: close/Keep-Alive 【服务器告诉浏览器连接方式】
- Date: Tue, 11 Jul 2000 18:23:51 GMT【服务器告诉浏览器回送数据的时间】
- Last-Modified: Tue, 11 Jul 2000 18:23:51 GMT【服务器告诉浏览器该资源上次更新时间】
除了几个重要的我标记了之外,其他的我们都可以见了再查
现在,知道了请求头和响应体,我们就可以开始调戏百度了,哈哈哈
(这里我使用的是我的小破服务器,没有服务器可以用Linux的虚拟机)
1 | 我输入:telnet www.baidu.com 80 |
大方的百度给我返回了一大堆,不要急,我们看最前面的东西
1 | HTTP/1.1 200 OK |
百度响应给我们信息,状态码是喜闻乐见的200,开心
好了这样我们无情的就调戏了一波百度,走人,程序员的生活就是这么平凡且枯燥
HTTP(1.0)特性
非持续连接
如果你是一个程序研制者,你需要使用TCP来完成HTTP报文的传输,那么你会有两种选择
- 每个请求/响应对使用一个单独的TCP连接发送,这样的程序称为非持续连接
- 所有的请求/响应对使用同一个TCP连接发送,这样的程序称为持续连接
HTTP(1.0)是非持续连接的,这意味着服务器每次响应发送的响应体中只能包含一个对象的信息
假设服务器上有一个HTML资源和十张图片,现在我们要获取这样的资源,我们需要连接几次TCP呢?
11次(一个html和十张图片),每次我们都要经历TCP的建立和断开
笨拙的发送请求
我们每次只能发送一个请求,只有等待第一个请求响应之后,我们才可以发送第二个请求
队头阻塞
不仅笨,而且假如有一个HTTP请求阻塞,那么他之后的请求都会阻塞

无状态
兵无常势,水无常形 ——孙武《孙子兵法》
HTTP是一个无状态的协议(stateless protocol),什么是无状态呢?即HTTP没有记忆,或者说服务器不会存储任何关于该用户的信息。
比如说刚刚我们调戏了百度,但是它根本不会记得我们。。。(是不是该难受)
这里把它也算做了一个缺点,无状态当然也不是没有好处,由于无状态,服务器的负担就没有那么严重,可以说无状态是把双刃剑吧
优点
- 简单方便
- 灵活:由于是应用层协议,它的下层可以任意变化
- 应用广泛
缺点
明文传输
没错,明文传输。肉眼可见,信息裸奔,容易被窃听
HTTP不会验证身份
HTTP建立在双方相信的基础上,他不会去检查你的信息
不知道是否完整
我们无法验证信息的完整性,别人监听了我们的信息,他可以篡改
HTTP(1.1)提升
时代在发展,社会在进步,HTTP也不是一成不变的,HTTP迎来了1.1时代
持续连接
我们上面说到,HTTP是一个非持续连接,这样在请求数据时,我们会经历很多次不必要的TCP建立和断开,于是1.1版本我们变成了持续连接,这样的好处就是,大大提高了传输效率
请求头内我们有一个字段Connection:Keep-Alive,就是告诉服务器,和我建立连接之后,不要着急断开
管道网络传输
现在我们发送请求,无需等待响应就可以发出第二个
注意:我们尽管能够发送多个请求而无需等待响应,但是我们的请求是按着顺序来的,服务器会依次响应我们的请求,这意味着,如果其中一个响应出现丢包或是延迟,之后的响应依然会阻塞
HTTP1.1希望使用此技术解决队头阻塞,但是并没有解决的很完全
此外,因为接受响应需要按顺序,所以很少浏览器实际使用了这个技术,反而是使用其他一些操作来提高速度:
- 精灵图:把多个小图标组合起来,作为一个图片发送
- DataURLs:将图片等资源嵌入到文档中作为文字发送,就无需额外请求图片了,比如base64
- 域名分片:1.1的串行发送限制是针对域来说的,如果域不同就可以达到并行下载,比如我们有五张图片,给每一个图片设置一个域名,比如
image1.img.com、image2.img.com等等,就可以实现并行下载资源(一个比较极端的例子,实际中没有这么夸张)
DataURLs是一种用于在URL中包含数据的特殊方案。它允许将小型数据嵌入到文档中,而无需单独请求服务器获取数据。
DataURLs的数据格式:
1 | data:[<mediatype>][;base64],<data> |
优点:减少对服务器的请求,提高页面加载速度,并且适用于一些临时或小规模的数据嵌入需求
缺点:数据直接嵌入在URL中,会导致URL过长和重复传输相同的数据,增加了页面的大小
Cookie
上面我们说我们虽然调戏了百度,但是百度忘记了我们,但其实他是记得我们的。
Cookie是什么?
Cookie是曲奇饼的意思。
哦不,Cookie是为了解决HTTP无状态的技术
当我们第一次访问服务器时,服务器看见我们没有带曲奇饼,他就会给我们一个曲奇饼,告诉我们的浏览器,“诶呀,下次来的时候记住带上曲奇饼”,响应完我们的数据之后,他会把对象和曲奇饼一起给我们
之后,当我们再一次访问服务器时,我们通过曲奇饼,服务器就可以认识我们,“啊,原来是你小子”
Cookie技术总共包含四个组件:
- 响应报文有一个cookie
- 请求报文中有一个cookie
- 浏览器保存了一个cookie
- 后端数据库中也有一个cookie
HTTP1.1已解决的问题
- 持续连接的问题
- 支持管道网络传输
HTTP1.1仍存在的问题
- 请求 / 响应头部(Header)未经压缩就发送,头部信息越多延迟越大。只能压缩 Body 的部分;
- 发送冗长的头部。每次互相发送相同的首部造成的浪费较多;
- 服务器是按请求的顺序响应的,如果服务器响应慢,会招致客户端一直请求不到数据,也就是队头阻塞;
- 没有请求优先级控制;
- 请求只能从客户端开始,服务器只能被动响应
- 依然是明文传输,易篡改、窃听、冒充
HTTP的缺点还有这么多,但是科技总是会进步的!
一次完整的HTTP过程
我们在浏览器输入 http://www.baidu.com/index.html
DNS服务将域名转换为主机名
HTTP客户进程发起一个到服务器www.baidu.com的TCP连接请求(包含四个字段:源IP,源端口,目的IP,目的端口),TCP连接就要经过三次握手
建立连接后,客户端将HTTP报文发送给服务器端,服务器端OS接收后,将按不同的端口号划分数据给进程(这里就是80端口)。
服务器端接收到后,分析url,这里即/index.html,在自己的内存中寻找index.html,在寻找到后,将HTML文件封装到响应体中,立马向客户端发送响应报文
浏览器接收到响应报文之后,根据响应回的Connection字段信息,决定是否关闭TCP连接。如果字段值为close的话,那么开始四次挥手;如果字段值为Keep-Alive的话,那么在发送完html之后依然保持连接状态。
浏览器根据响应体来进行显示
HTTPS
时代在发展,科技在进步,HTTPS给HTTP的安全性带来了保障
HTTPS(Hyper Text Transfer Protocol over SecureSocket Layer),明显的字眼SSL
HTTPS就是在TCP的上层加了SSL(或者是TLS),HTTP的默认端口是80,HTTPS默认端口是443
SSL(Secure Sockets Layer)安全套接层和TLS(Transport Layer Security)传输层安全协议其实是一套东西。
网景公司在1994年提出HTTPS协议时,使用的是SSL进行加密。后来IETF(Internet Engineering Task Force)互联网工程任务组将SSL进一步标准化,于1999年公布第一版TLS协议文件TLS 1.0。目前最新版的TLS协议是TLS 1.3,于2018年公布。
HTTPS加入了SSL来解决HTTP不安全的问题,主要通过三个手段:
- 混合加密
- 摘要算法
- 数字证书

混合加密
首先我们先了解一下对称加密,和非对称加密
对称加密:采用单钥密码系统的加密方法,同一个秘钥可以同时用作信息的加密和解密,这种加密方法称为对称加密,也称为单秘钥加密。对称秘钥使用一个秘钥,速度快,但是秘钥必须共享给对方,在这个过程中容易受到攻击
非对称加密:即浏览器和客户端各自持有私钥,不必交换秘钥,安全,但是速度较慢
HTTPS采用两种办法混合使用的方式:
- 通信建立前:采用非对称秘钥加密的方式交换会话秘钥,后续就不再使用非对称加密
- 通信过程中:全部使用对称加密来加密明文数据
摘要算法
客户端在发送明文之前,通过摘要算法算出明文的指纹
指纹:一般地,把对一个信息的摘要称为该消息的指纹或数字签名
发送的时候将明文加指纹一同加密为密文后,一同发送给服务器
服务器解密后,用相同的摘要算法算出发送过来的明文,通过对比自己得出的指纹和发送过来的指纹做对比,如果比较相同,说明数据是完整的
数字证书
借助第三方权威机构CA(数字证书认证机构),将服务器公钥放在数字证书(由数字证书认证机构发布),只要证书是可信的,公钥就是可信的。(可信是可信,但是要小钱钱。。。)
SSL/TLS协议建立的过程

下面是一个旧版的流程,我发现写的有点乱且复杂,所以只看上图即可
- 首先,由客户端向服务器发起加密通信请求,也就是
ClientHello请求。
主要发送的信息(1)客户端支持的 `SSL/TLS` 协议版本,如 TLS 1.2 版本。 (2)客户端生产的**随机数**(Client Random),后面用于生产「会话秘钥」。 (3)客户端支持的密码套件列表,如 RSA 加密算法。 - 服务器收到客户端请求后,向客户端发出响应,也就是
SeverHello。
回应(1)确认 `SSL/ TLS` 协议版本,如果浏览器不支持,则关闭加密通信。 (2)服务器生产的**随机数**(Server Random),后面用于生产「会话秘钥」。 (3)确认的密码套件列表,如 RSA 加密算法。 (4)**服务器的数字证书**。 - 客户端收到服务器的回应之后,首先通过浏览器或者操作系统中的 CA 公钥,确认服务器的数字证书的真实性。
如果证书没有问题,客户端会从数字证书中取出服务器的公钥,然后使用它加密报文发送: (1)一个**随机数**(pre-master key)。该随机数会被服务器**公钥加密** (2)加密通信算法改变通知,表示随后的信息都将用「会话秘钥」加密通信 (3)客户端握手结束通知,表示客户端的握手阶段已经结束。这一项同时把之前所有内容的发生的数据做个摘要,用来供服务端校验 - 服务器收到客户端的第三个随机数(pre-master key)之后,通过协商的加密算法,计算出本次通信的「会话秘钥」
(1)加密通信算法改变通知,表示随后的信息都将用「会话秘钥」加密通信。
(2)服务器握手结束通知,表示服务器的握手阶段已经结束。这一项同时把之前所有内容的发生的数据做个摘要,用来供客户端校验。
HTTP终于解决了不安全的问题,但是他的问题还有很多:
- 请求 / 响应头部(Header)未经压缩就发送,头部信息越多延迟越大。只能压缩 Body 的部分;
- 发送冗长的头部。每次互相发送相同的首部造成的浪费较多;
- 服务器是按请求的顺序响应的,如果服务器响应慢,会招致客户端一直请求不到数据,也就是队头阻塞;
- 没有请求优先级控制;
- 请求只能从客户端开始,服务器只能被动响应
HTTP2
HTTP2优化
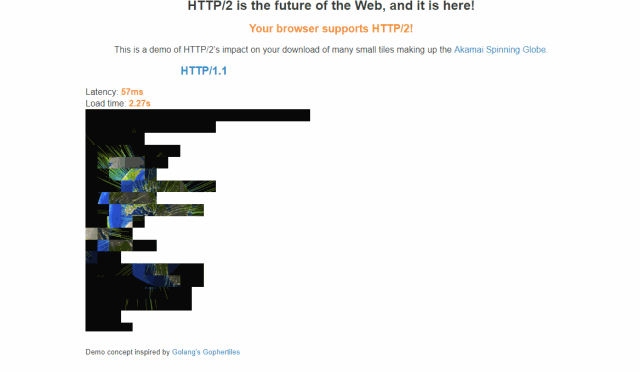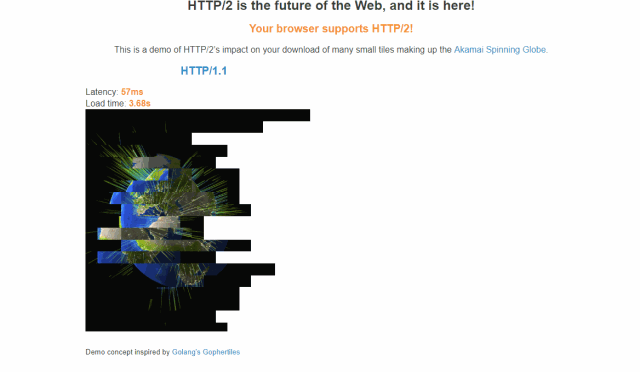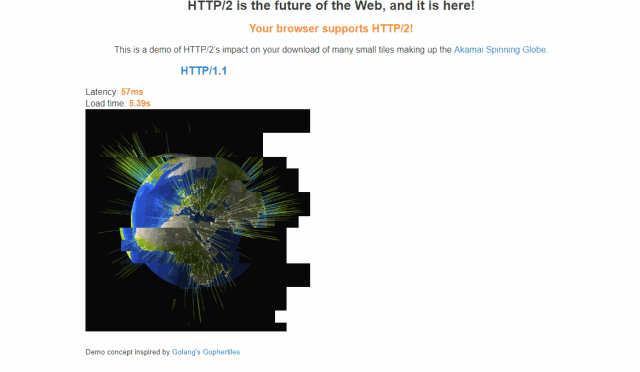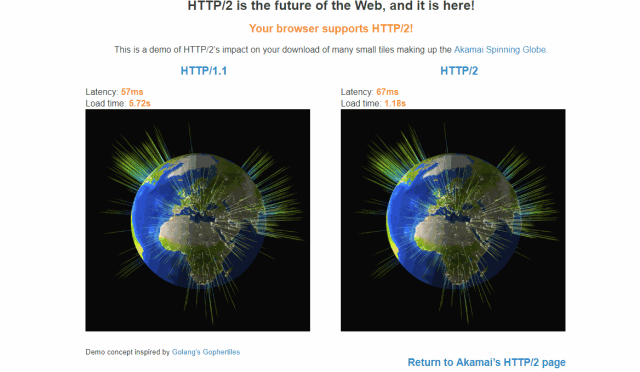
头部压缩,如果同时发出的多个请求请求头相同,则会消除重复的部分
这就是所谓的 HPACK 算法:在客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。HTTP/2 不再像 HTTP/1.1 里的纯文本形式的报文,而是全面采用了二进制格式。头信息和数据体都是二进制,并且统称为帧(frame):头信息帧和数据帧。
HTTP/2 的数据包不是按顺序发送的,同一个连接里面连续的数据包,可能属于不同的回应。因此,必须要对数据包做标记,指出它属于哪个回应。
每个请求或回应的所有数据包,称为一个数据流(Stream)。
每个数据流都标记着一个独一无二的编号,其中规定客户端发出的数据流编号为奇数, 服务器发出的数据流编号为偶数
客户端还可以指定数据流的优先级。优先级高的请求,服务器就先响应该请求。
HTTP/2 是可以在一个连接中并发多个请求或回应,而不用按照顺序一一对应。不会再出现「队头阻塞」问题,降低了延迟,大幅度提高了连接的利用率。
- 报文含有流标识符,这样解决无序响应的问题
服务不再是被动地响应,也可以主动向客户端发送消息。
在浏览器刚请求 HTML 的时候,就提前把可能会用到的 JS、CSS 文件等静态资源主动发给客户端,减少延时的等待,也就是服务器推送(Server Push,也叫 Cache Push)。
结构如下:

HTTP2缺点
多个 HTTP 请求在复用一个 TCP 连接,下层的 TCP 协议是不知道有多少个 HTTP 请求的。所以一旦发生了丢包现象,就会触发 TCP 的重传机制,这样在一个 TCP 连接中的所有的 HTTP 请求都必须等待这个丢了的包被重传回来。
我们发现一个问题(盲生,你发现了华点):
- HTTP/1.1 中的管道( pipeline)传输中如果有一个请求阻塞了,那么队列后请求也统统被阻塞住了
- HTTP/2 多请求复用一个TCP连接,一旦发生丢包,就会阻塞住所有的 HTTP 请求。
归结原因,这是使用TCP协议的弊端
所以HTTP3直接干掉了TCP,这就是为什么我们说HTTP协议是一个应用层的高层协议,因为它可以灵活的选择底层的结构
HTTP3
HTTP/3 把 HTTP 下层的 TCP 协议改成了 UDP

- UDP 发生是不管顺序,也不管丢包的,所以不会出现 HTTP/1.1 的队头阻塞 和 HTTP/2 的一个丢包全部重传问题。
- 大家都知道 UDP 是不可靠传输的,但基于 UDP 的 QUIC 协议 可以实现类似 TCP 的可靠性传输。
- QUIC 有自己的一套机制可以保证传输的可靠性的。当某个流发生丢包时,只会阻塞这个流,其他流不会受到影响。
- TL3 升级成了最新的 1.3 版本,头部压缩算法也升级成了 QPack。
- HTTPS 要建立一个连接,要花费 6 次交互,先是建立三次握手,然后是 TLS/1.3 的三次握手。QUIC 直接把以往的 TCP 和 TLS/1.3 的 6 次交互合并成了 3 次,减少了交互次数。
QUIC 是一个在 UDP 之上的伪 TCP + TLS + HTTP/2 的多路复用的协议。
小结
本文从基础的网络知识谈起,从HTTP1.0,谈到了HTTP3.0,
谈到了他们各自的优点缺点,每一步的发展,每一次出现的错误
感慨良多,HTTP的发展就像是人类不断探索的过程,发现问题到解决问题,解决问题到又发现问题,值得思考很多很多很多
参考资料
- 《计算机网络 自顶向下方法》
- 公众号 小林coding
- 公众号 Java3y
- 敖丙