Redis
Redis核心内容总结
- 支持的数据结构有:字符串、列表、字典(哈希)、集合、有序集合
- 字符串的底层数据结构:SDS简单动态字符串(三个字段:指针、free剩余的空间大小、len长度)
- 使用SDS替代C原本字符串的优点:
- 获取字符串长度为O(1)级别(C中需要遍历一遍O(n))
- 实现了空间预分配(扩大时会扩的更大一点)、惰性空间释放(缩小时不会立即缩小)
- 二进制安全(使用len来判断字符串结尾,而不是C中的使用
/0来判断)
- 列表的底层数据结构:数据少用压缩列表;数据多用双向链表
- 什么时候用压缩列表?满足两个条件:
- 每个数据的长度不超过64
- 数据总个数不超过512
- 哈希的底层数据结构:数据少用压缩列表;数据多用散列表
- 散列表的使用细节:
- 解决哈希冲突:拉链法
- 维护一个装载因子:装载因子大于1.0,就翻2倍左右;小于0.1,就缩小2倍左右
- 集合的底层数据结构:数据少用有序数组;数据多用散列表
- 什么时候用有序数组?满足两个条件:
- 存储的数据全为数字
- 总个数不超过512
- 有序集合的底层数据结构:数据少用压缩列表;数据多用跳表
- 跳表的实现细节:
- 给链表隔一个元素建一个索引,在给索引隔一个建一个索引,直到最顶层建了两个索引为止
- 插入、删除、查询都很快
- **时间复杂度:O(log n)**(再细一点,如果是隔一个建立一个索引,那么时间复杂度是O(3 log n))
- 通过一个随机函数来保持平衡(随机函数的选择很重要,但是不需要深究)
- 为什么使用跳表而不是红黑树?两个原因:
- 跳表实现相对来说简单
- 红黑树的范围查询性能没有跳表好
- 数据的持久化:
- RDB:默认的方式,隔一段时间,就将当前redis库内的所有元素写入磁盘
- AOF:日志记录的方式
- 各类数据结构的应用场景:
- 字符串:可以统计网站人数、可以实现分布式锁(用
setnx) - 列表:可以实现栈、实现队列、实现消息队列
- 哈希:可以实现一个购物车
- 集合:可以实现社交领域发现共同好友、发现用户共同兴趣等
- 有序集合:可以实现一个直播的动态排行榜
- 字符串:可以统计网站人数、可以实现分布式锁(用
NOSQL
随着互联网web2.0网站的兴起,传统的关系数据库在处理web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,出现了很多难以克服的问题
redis作为非关系型数据库的一员,在web2.0的交互中展露枝头
关系型数据库
例如:
- Oracle
- MySQL
是指采用了关系模型来组织数据的数据库,其以行和列的形式存储数据,以便于用户理解,关系型数据库这一系列的行和列被称为表,一组表组成了数据库。
特点:
- 数据之间有关联关系
- 数据存储在硬盘的文件上
- 表现为一个个的表格
非关系型数据库(NOSQL)
例如:
- redis
- hbase
- mongdb
区别于关系数据库,它们不保证关系数据的ACID特性。(ACID指关系型数据库的原子性,一致性,隔离性,持久性)相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
但是一个共同的特点都是去掉关系数据库的关系型特性。
NoSQL有如下优点:易扩展,NoSQL数据库种类繁多
特点:
- 数据之间没有关系
- 数据存储在内存中
- 表现为
key:value的形式
NOSQL与关系型数据库的比较
优点:
- 成本:NOSQL数据库简单易部署,基本都是开源软件,相比关系型数据库成本低廉
- 查询速度:NOSQL存储在缓存当中,查询速度非常快
- 存储格式为:
key:value形式,文档形式,图片形式等,所以可以基础类型以及对象或是集合等格式,而关系型数据库只能存储基础类型
缺点:
- 维护的工具和资料有限:因为NOSQL属于新的技术,而关系型数据库已经有十几年的技术
- 不提供对SQL的支持:不支持SQL这样的工业标准,将产生一定用户的学习和使用成本,例如redis与hbase差别很大,而Oracle与mysql差别就很小
- 不提供关系型数据库对事务的处理
我们一般将数据存储在关系型数据库中,在NOSQL数据库中备份存储关系型数据库的数据
Redis
初识Redis
Redis:Remote Dictionary Server 远程字典服务
redis是一款高性能的NOSQL系列的非关系型数据库
redis是用c语言开发的高性能键值对数据库
常见的应用场景:
- 缓存(数据查询,短连接,新闻内容,商品内容等等)
- 聊天室的在线好友列表
- 任务队列(秒杀、抢购、12306等)
- 应用排行榜
- 网站访问统计
- 数据过期处理
- 分布式集群架构中的session分离
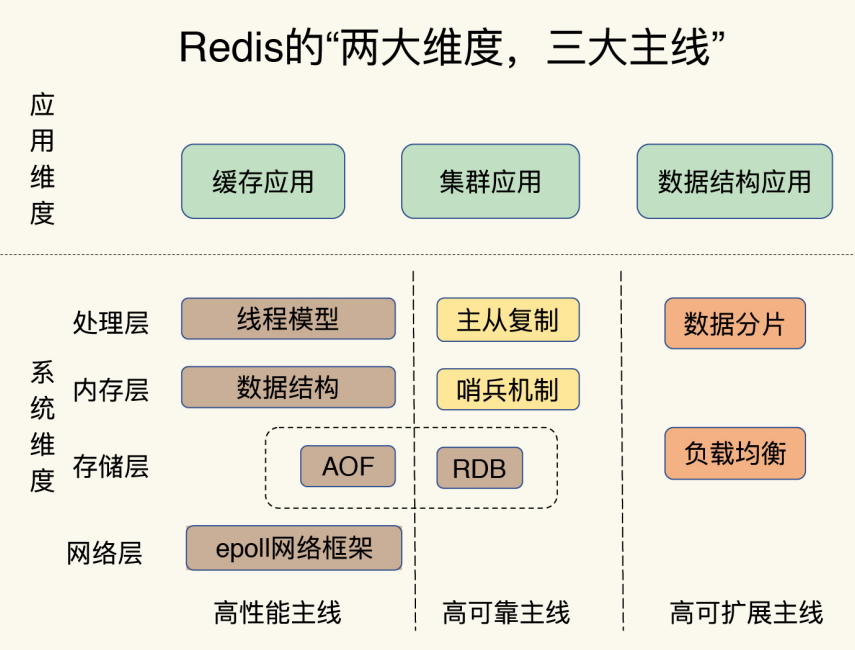
两大维度、三大主线
三大主线:高性能、高可靠、高可扩展
两大维度:应用维度、系统维度
redis不同数据的操作
本节是关于Redis的命令操作
redis数据库操作
1 | ping //测试一个连接是否还可用,如果不加任何内容返回pong,加了内容返回它本身 |
redis的数据结构
支持的五大数据结构:
- 字符串类型
string - 哈希类型
hash - 列表类型
list - 集合类型
set - 有序集合类型
sortedset(Zset)
另外还能存储几种特殊数据结构:
- HyperLogLogs:省内存的去统计各种计数,比如注册 IP 数、每日访问 IP 数的页面实时UV、在线用户数,共同好友数等
- Bitmap:两个状态的,都可以使用 Bitmap,比如登录未登录、性别
- geospatial :推算地理位置的信息: 两地之间的距离, 方圆几里的人;底层是Zset,有序列表
- stream:用于消息队列和发布/订阅模式
字符串类型
Redis中的字符串
string类型是二进制安全的,意思是Redis的string可以包含任何数据(图片、对象等等)- key最大可以是512Mb
基本的操作
1 | set key value // 存储 |
追加与长度获取
1 | append key xxx // 给一个key追加字符串 |
自增与自减(可以使用这个来进行计数,比如统计系统在线人数)
1 | incr key // 给一个key的值+1(必须是数值) |
获取子串
1 | getrange key [start] [end] //返回子串[start,end],如果end是-1,代表末尾 |
ex与nx(setnx可以实现分布式锁)
1 | setex key [second] [value] // 设置值附带过期时间 |
批量操作(原子操作,但注意,Redis单线程,如果一次传输数据太多,会导致Redis阻塞或者网络拥塞)
1 | mset key1 value1 k2 v2 k3 v3 // 批量创建 |
存放对象
1 | mset user:1:name zhangsan user:1:age 3 // mset 对象:{id}:field value |
getset
1 | getset //设置新值,返回旧值 |
总结:表格来自于
| 命令 | 描述 | 用法 |
|---|---|---|
| SET | (1)将字符串值Value关联到Key(2)Key已关联则覆盖,无视类型(3)原本Key带有生存时间TTL,那么TTL被清除 | SET key value [EX seconds] [PX milliseconds] [NX|XX] |
| GET | (1)返回key关联的字符串值(2)Key不存在返回nil(3)Key存储的不是字符串,返回错误,因为GET只用于处理字符串 | GET key |
| MSET | (1)同时设置一个或多个Key-Value键值对(2)某个给定Key已经存在,那么MSET新值会覆盖旧值(3)如果上面的覆盖不是希望的,那么使用MSETNX命令,所有Key都不存在才会进行覆盖(4)MSET是一个原子性操作,所有Key都会在同一时间被设置,不会存在有些更新有些没更新的情况 | MSET key value [key value …] |
| MGET | (1)返回一个或多个给定Key对应的Value(2)某个Key不存在那么这个Key返回nil | MGET key [key …] |
| SETEX | (1)将Value关联到Key(2)设置Key生存时间为seconds,单位为秒(3)如果Key对应的Value已经存在,则覆盖旧值(4)SET也可以设置失效时间,但是不同在于SETNX是一个原子操作,即关联值与设置生存时间同一时间完成 | SETEX key seconds value |
| SETNX | (1)将Key的值设置为Value,当且仅当Key不存在(2)若给定的Key已经存在,SEXNX不做任何动作 | SETNX key value |
Redis字符串的应用
应用场景:
Redis单线程,不需要考虑并发
setnx来设置分布式锁incrby进行计数、统计网站人数
哈希类型
以Java来理解,Redis的哈希类型就是Map<String, Map<String, Object>>
1 | hset key field value // 存储 |
redis-cli示例
1 | //设置 |
列表类型
Redis中的list
redis内的列表是一个横向的列表,可以添加到左边或者右边
redis列表是一个有序的列表,而且可以重复
1 | //添加 |
redis-cli示例
1 | //添加到list |
Redis列表的应用
Redis的列表特点:有左右、有序、可重复
- 实现栈(
lpush、lpop) - 实现队列(
lpush、rpop) - 实现消息队列(
lpush、brpop)
brpop命令:移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
集合类型
Redis集合类型
特点:
不允许重复
无序
1 | //存储 |
redis示例
1 | 127.0.0.1:6379> sadd myset a b c d e f g |
Redis集合的应用
可以利用集合的并、交特性,在社交领域,可以求共同好友、发现用户共同兴趣等
有序集合类型
Redis有序集合Zset
特点:
- 不允许重复
- 有序
1 | //存储,存储数据以及数据对应的值 |
redis示例
1 | 127.0.0.1:6379> zadd mysort 60 zhangsan |
Redis有序集合的应用
可以做排行榜、也可以用于社交领域
Redis底层数据结构
Redis的底层数据结构,支持了上一节五大基本结构的使用

- String:简单动态字符串(注意:String也有第二个数据结构:当你保存的是一个64位有符号整数时,String会保存为一个8字节的Long类型整数,这也叫int编码方式)
- List:压缩列表;双向链表
- Hash:压缩列表;散列表
- Set:整数数组;散列表
- Sorted Set:压缩列表;跳表
1 | OBJECT ENCODING [key] # 此命令可以查看底层的数据结构 |
SDS简单动态字符串
使用自己构建的名为SDS(Simple dynamic string)简单动态字符串
1 | struct sdshdr{ |
使用如此的结构,极大的提高了性能:

- O(1)级别获取字符串长度;在C中,需要进行遍历,为O(n)
- 杜绝缓冲区溢出;C中,进行strcat等字符串操作,如果没有分配足够长度空间,容易导致缓冲区溢出;而对于SDS数据类型,字符串修改会首先根据len属性检查内存是否符合要求
- 减少修改字符串的内存重新分配次数;SDS可以进行空间预分配与惰性空间释放
- 空间预分配:当字符串扩展时,会扩展更大的空间
- 惰性释放:当字符串缩小,会增大
free的值,但是空间不一定会跟着变化
- 二进制安全:C中使用
/0空字符作为字符串结束位,但是对于图片等二进制文件,内容可能有空字符,因此SDS用len来判断字符串是否结束 - 兼容部分C字符串函数:使用C语言实现,可以兼容部分C的API
压缩列表
压缩列表:
通过一片连续的内存空间来存储数据(类似于C的数组)
但是和数组的区别是,存放的数据大小允许不同
压缩列表的特点:
- 压缩列表在表头有三个字段
zlbytes、zltail和zllen,分别表示列表长度、列表尾的偏移量和列表中的 entry 个数;压缩列表在表尾还有一个zlend,表示列表结束。 - 如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段 的长度直接定位,**复杂度是 O(1)**。
- 而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了。
优点:
- 允许存储不同类型的数据
- 节省空间
Redis什么时候使用压缩列表的实现?
在数据量小的时候才会使用,需要同时满足:
- 保存的单个数据小于64字节
- 列表中的数据总个数小于512个
双向链表
双向循环链表:
Redis的list结构体额外定义一个list的结构体
链表节点:(这与基本的双向列表一样)
1 | typedef struct listNode{ |
双向链表:(额外定义list的结构体)
1 | typedef struct list{ |
特点:
- 双端:双向链表,获取头尾元素均为O(1)
- 无环:头尾均指向NULL
- 带链表长度计数器:获取链表长度为O(1)
- 多态:链表节点使用
void*指针,可以保存不同元素
散列表
散列表
哈希算法:Redis 使用 MurmurHash2这种运行速度快、随机性好的哈希算法作为哈希函数
哈希冲突解决:拉链法
当数据动态增加之后,散列表的装载因子会不停地变大。为了避免散列表性能的下降:
装载因子 = 已存储元素数量 / 哈希表大小
当装载因子大于 1 的时候,Redis 会触发扩容,将散列表扩大为原来大小的 2 倍左右
为了节省内存,当装载因子小于 0.1 的时候,Redis 就会触发缩容, 缩小为字典中数据个数的大约 2 倍大小
(2倍左右,是估计值!)
有序数组
什么时候使用有序数组?
- 存储的数据都是整数
- 存储的数据元素个数不超过512个
在集合中如果不满足这些,就用散列表实现集合
整数数组和压缩列表在查找时间复杂度方面并没有很大的优势,那为什么 Redis 还会把它 们作为底层数据结构呢?
虽然没有什么时间复杂度的优势,但是胜在其使用数组,有两个特点:
- 节省空间
- 没有内存碎片
跳表
跳表:一个链表,为了提高它的查询速度,隔一个设置一个索引,用来加快查找,为了加快索引的搜索,再对索引隔一个设置一个索引
每一层索引都是一个链表,这样构成的数据结构就是跳表

特点:
- 由很多层结构组成;
- 每一层都是一个有序的链表,排列顺序为由高层到底层,都至少包含两个链表节点
- 最底层的链表包含了所有的元素;
- 如果一个元素出现在某一层的链表中,那么在该层之下的链表也全都会出现(上一层的元素是当前层的元素的子集);
- 链表中的每个节点都包含两个指针
- 一个指向同一层的下一个链表节点
- 另一个指向下一层的同一个链表节点;
- 插入、删除、查询都很快
- 通过随机函数来维护自平衡
有多快?
如果总共有 n个 节点
那么会建立log2N的高度的节点
查询一个数据的时间复杂度为O(m*log n)
m 是多少? m=3,因为每一层最多遍历三个节点(因为索引是隔一个抽一个建立起来的)
如何维护自平衡?通过一个随机函数
比如随机函数生成了值 K,那我们就将这个结点添加到第一级到第 K 级这 K 级索引中。
随机函数的选择比较重要,这也比较复杂,我们无需研究。
为什么选跳表不用红黑树?
- 按照区间来查找数据这个操作,红黑树的效率没有跳表高(虽然增删查的时间复杂度一样)
- 跳表更容易实现(相比较而言简单)
为什么SortedSet用跳表?
跳表的数据结构可以看做:
1 | public class Node { |
跳表式依赖于概率算法的:比如现在要新加入一个节点,需要决定该节点的层级
理论上来讲,一级索引应该占50%,二级索引占25%,三级索引占12.5%等等以此类推
决定当前节点层级是通过随机来决定的,晋升的概率为1/2。
1 | private static final float PROB = 0.5 f; |
对于有序Set来说,一般需要支持的操作有:
- 增
- 删
- 查一个数据
- 查区间数据
红黑树与跳表比较来说,对于前三个操作基本一致,但是查区间数据会慢一些,且实现要比跳表难一些。
为什么跳表范围查询比红黑树快?
红黑树是老老实实一级一级查的,但是跳表是顺序和跳跃的结合,这使得跳表可以快速跳跃到目标区间的起点,而一旦找到起点后,可以直接顺序遍历底层链表。
深入Redis数据结构
占内存的String
前面说了String的底层,由SDS构成,但其实,String类有很深的门道,这节我们来说一下
String有三种编码方式:
int编码:在保存64位有符号整数时embstr编码:在保存的字符串小于44字节时raw编码:大于44字节时
下图是RedisObejct的示意图
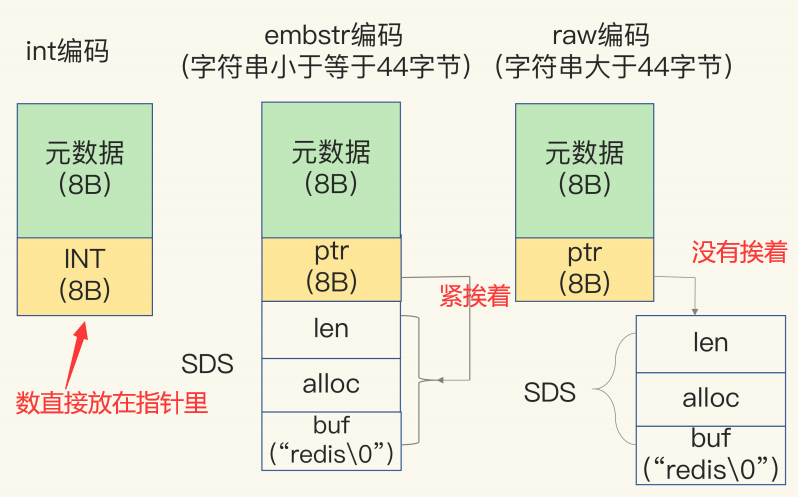
可见,三种编码方式,在内存中的实现是不一样的,int编码的数据就直接在指针里放着,节省内存;embstr的SDS在内存中与RedisObejct紧挨着(这样可以避免内存碎片)
这里额外补充一下:
RedisObejct是记录数据是什么类型的结构体,由两部分组成,元数据与类型指针
对于全局哈希表,它的每一项都是一个DictEntry结构体,这个结构体存放三个数据(下一节):key、value、next
内存结构是这么存的:

假如我们用String保存2个10位的数,会消耗多少内存呢?
由于存10的数字,所以会直接占用指针的8个字节,元数据用8个字节,共有两个会占用32字节;
DictEntry占24字节,但是Redis 使用的内存分配库 jemalloc只会分配2的幂次的大小,所以分配32字节
所以占用了64字节,但是有效的信息,只有16字节,所以说String的开销很大!利用率不高
使用压缩列表
String消耗内存很多,当存的数据只是简单的数字时,越多String消耗的空间越大,但实际上根本没有利用多少
压缩列表就是一个很节省内存的例子
压缩列表在表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量和列表中的 entry 个数;压缩列表在表尾还有一个 zlend,表示列表结束
压缩列表的每一个entry,由四个部分构成:prev_len、encoding、len、content
prev_len:表示前一个entry的长度,只有两种取值情况,要么占1B、要么占5B- 如果上一个entry小于254字节,那么就取1B;否则取5B
encoding:编码方式,1Blen:表示自身长度,占4Bcontent:保存实际数据

用一个RedisObejct,就可以存一堆数,这可比存一个数就要一个RedisObejct的String要省内存多了
Redis什么时候使用压缩列表的实现?
在数据量小的时候才会使用,需要同时满足:
- 保存的单个数据小于64字节
- 列表中的数据总个数小于512个
这两个参数都可以调节
全局哈希表
Redis使用了两个全局哈希表
全局哈希表:如图,value为一个一个节点,节点才会去存真正的数据类型
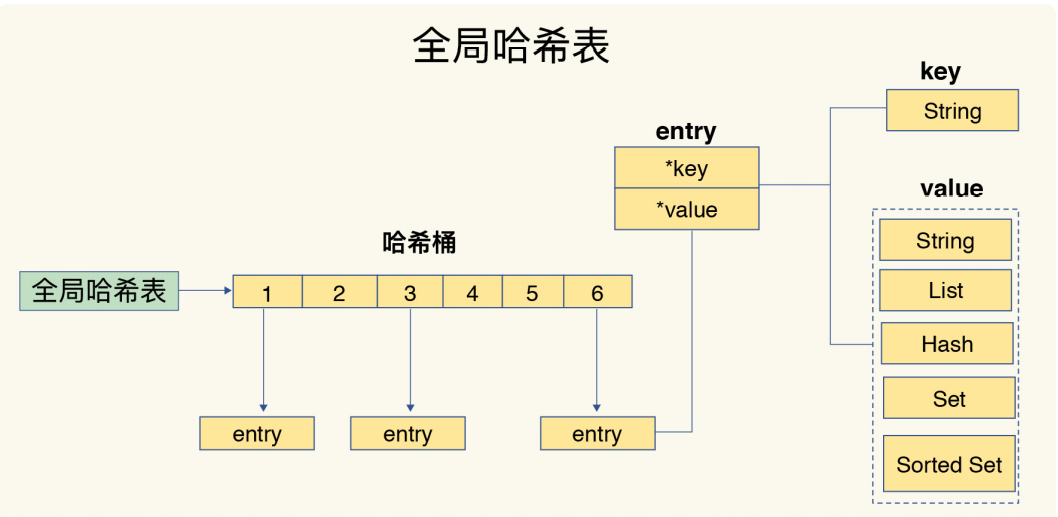
这个全局的哈希表中,每一项是一个dictEntry节点,这个dictEntry结构体包含三个部分(图中只画了两个):key、value、next(指向下一个dictEntry)
那么这里有几个问题,带着问题来思考
全局哈希表如何解决哈希碰撞?
是使用拉链法来解决哈希冲突的
如果拉链变的十分长,导致查询速度下降,那么Redis是怎么保证高性能呢?
当Redis发现存放的数据达到一定程度,就会进行rehash,使用两个哈希表来进行交替,这样即使在rehash过程中,也不会无法进行服务
rehash的过程
- 给哈希表2分配更大的空间(比如是哈希表1的两倍)
- 将哈希表1的数据重新映射并拷贝到哈希表2中
- 释放哈希表1的空间
如果哈希表2再满了,那么再次重复这个过程
渐进式rehash
如果真的采用上面的rehash过程,那么在2步过程中,由于copy浪费的时间,将导致redis不能进行服务
所以Redis是渐进式rehash的(即每次的请求,都捎带着copy一个桶上的索引)

可以保证在copy过程中,也能继续保持服务
单线程数据库Redis
Redis是单线程的吗?
严格意义上来说,Redis不是单线程的;
常说的Redis是单线程,是指其提供的网络IO 和 键值对读写是由一个线程来完成的
为什么使用单线程?
多线程其实并不会快很多,对于一些共享数据,多线程需要加锁进行操作,这种情况下,多线程的性能不会比单线程高,只会让设计上更加复杂
为什么使用单线程,Redis还这么快?
几方面原因:
- 处理方面:redis是单线程的,单线程无需考虑并发操作,无需加锁
- 内存方面:redis的底层数据结构比较快,比如跳表
- 持久化方面:有AOF这种快速的日志机制。
- 网络方面:使用epoll网络编程模型
多路复用机制
以一个Redis的GET请求为例,基本的IO模型如图

整个过程如下
- Redis要先监听客户端请求(bind/listen)
- 建立连接(accept)
- 读取请求(recv)
- 解析客户端发送的请求(parse)
- 从数据库获取数据(get)
- 返回发送给客户端(send)
其中2与3是阻塞点
(2:redis监听到连接请求,但是一直未能成功连接,导致其他客户端无法与redis连接;3:读取的数据如果一直没有到达,也会造成阻塞)
如何解决基本的网络IO带来的阻塞?
Socket网络模型支持非阻塞模式
非阻塞:即在遇到阻塞后,不在原地等待,而是先去执行其他操作,隔段时间再来观察是否还阻塞
Socket 网络模型的非阻塞模式设置,主要体现在三个关键的函数调用上:
| 调用方法 | 返回套接字类型 | 非阻塞模式 | 效果 |
|---|---|---|---|
socket() |
主动套接字 | ||
listen() |
监听套接字 | 可设置 | accept()非阻塞 |
accept() |
已连接套接字 | 可设置 | send()/recv()非阻塞 |
socket()方法会返回主动套接字然后调用
listen()方法,将主动套接字转化为监听套接字,此时,可以监听来自客户端的连接请求调用
accept()方法接收到达的客户端连接,并返回已连接套接字
因为可以设置非阻塞,所以Redis在accept()或recv()迟迟没有得到反映,就可以先进行其他操作
虽然Redis可以不继续等待,但是总得有机制在监听套接字上等待,这就用到了Linux的IO多路复用机制
多路复用机制:
IO 多路复用机制是指一个线程处理多个 IO 流,就是我们经常听到的 select/epoll 机制
select/epoll 机制:可以快速看一下这篇blog,图画的非常nice,一眼就懂了
这里贴一下图,图源在上面已经说了
- select:
- 处理所有的fd,进行挨个询问
- 水平触发:如果不处理,下次会继续通知
- epoll:
- 所只处理那些就绪的fd
- 支持水平触发与边缘触发:只通知一次,如果我没有处理,只有到下次状态发生实际变化才会通知


Redis中的高性能IO模型

回调机制:
select/epoll 提供了基于事件的回调机制,即针对不同事件的发生,调用相应的处理函数
这些事件会被放进一个事件队列,Redis 单线程对该事件队列不断进行处理。
这样一来, Redis 无需一直轮询是否有请求实际发生,这就可以避免造成 CPU 资源浪费。
AOF详解
redis是一个内存数据库,储存在内存当中,关闭后数据会丢失,但是Redis提供了两种持久化方式:RDB、AOF
AOF (Append Only File): 日志记录的方式,可以记录每一条命令的操作,可以每一次命令操作后,持久化数据
AOF日志的工作比较特殊,不同于传统的WAL,他是先执行操作,再写数据
为什么AOF日志要先执行操作,后写入日志呢?
好处有两个:
- 避免检查语法错误:因为只有执行成功,才会被写入日志
- 命令执行后再写,不会阻塞当前的操作
不过有两个潜在的风险:
- 如果操作执行完,宕机,会导致日志上并没有记录(数据会丢失,不再可以使用日志进行恢复)
- 虽然避免了阻塞当前操作,但可能会阻塞下一个操作(因为写日志是需要操作磁盘的!)
如果我们可以找好时机写入磁盘,那么这两个风险会好一点:Redis提供了三种写回策略
三种写回策略
AOF 机制给我们提供了三个选择,也就是 AOF 配置项 appendfsync 的三个可选值:
Always:每一个操作都写回日志Everysec:每秒写回,先写在缓冲区,每隔一秒写回一次No:先写在缓冲区,操作系统控制何时写回
| 配置项 | 写回时机 | 优点 | 缺点 |
|---|---|---|---|
| Always | 同步写回 | 可靠性好,数据基本不丢失 | 影响性能 |
| Everysec | 每秒写回 | 性能适中 | 宕机丢失1s数据 |
| No | 操作系统控制写回 | 性能好 | 宕机丢失数据较多 |
不管哪一种写回方式,随着日志越写越多,终究会导致性能问题,所以AOF还提供了重写机制
AOF重写机制
重写:就是在重写时,Redis 根据数据库的现状创建一个新的 AOF 文件
这个文件会比原来的小很多,因为它只记录结果!

并且 和AOF 日志由主线程写回不同,重写过程是由后台线程 bgrewriteaof 来完成的
重写的过程:一个拷贝、两个日志
一个拷贝:主线程fork出后台线程bgrewriteaof(注意:fork这一操作的过程是阻塞了主线程的!)
fork操作会把主线程的内存拷贝一份给 bgrewriteaof 子进程,这里面就包含了数据库的最新数据(也就是说,如果主线程的内存越大,这个拷贝的时间也会越长)
两个日志:
- 正常使用的AOF日志
- AOF重写日志

RDB详解
另一种Redis的持久化方式
RDB (Redis DataBase) : 默认方式,不需要进行配置,默认就使用这种机制,一定时间间隔,检测key的变化情况,然后持久化存储
类似于快照,会将当前内存所处的状态,生成一个RDB文件
和AOF比,RDB 记录的是某一时刻的数据,并不是操作
所以,在做数据恢复时,我们可以直接把 RDB 文件读入内存,很快地完成恢复
RDB快照
Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave:
save:在主线程中执行,会导致阻塞;bgsave:创建一个子进程,专门用于写入 RDB 文件,避免了主线程的阻塞,这也是 Redis RDB 文件生成的默认配置
在进行快照时,数据可以改变吗?
可以改变,Redis采用COW(写时复制)的思想来实现备份时也可以服务
- 如果是读操作:(例如图中的键值对 A),那么,主线程和 bgsave 子进程相互不影响
- 如果是写操作:(例如图中的键值对 C), 那么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave 子进程会把这个副本数据写入 RDB 文件,而在这个过程中,主线程仍然可以直接修改原来的数据

RDB的缺点
虽然RDB可以快速的进行恢复,而且也可以在备份时继续服务
但是隔多久进行一次快照并不好把控
- 隔得时间短,影响性能
- 隔得时间长,如果宕机会丢失很多数据
Redis提出了增量快照
增量快照:即在一次全量快照后,之后的更改只记录修改的部分
Redis4.0混合AOF与RDB
Redis 4.0 中提出了一个混合使用 AOF 日志和内存快照的方法。
简单来说,内存快照以一定的频率执行,在两次快照之间,使用 AOF 日志记录这期间的所有命令操作
这个方法既能享受到 RDB 文件快速恢复的好处,又能享受到 AOF 只记录操作命令的简单优势
Redis主从复制
为了保证数据故障恢复时也可以进行服务(Redis为了可以提供服务操碎了心)Redis也有主从机制
主从库模式
Redis主从库承担了不同的任务,采用读写分离的方式
- 主库:负责读操作、写操作
- 从库:只负责读操作
写操作只可以对主库进行
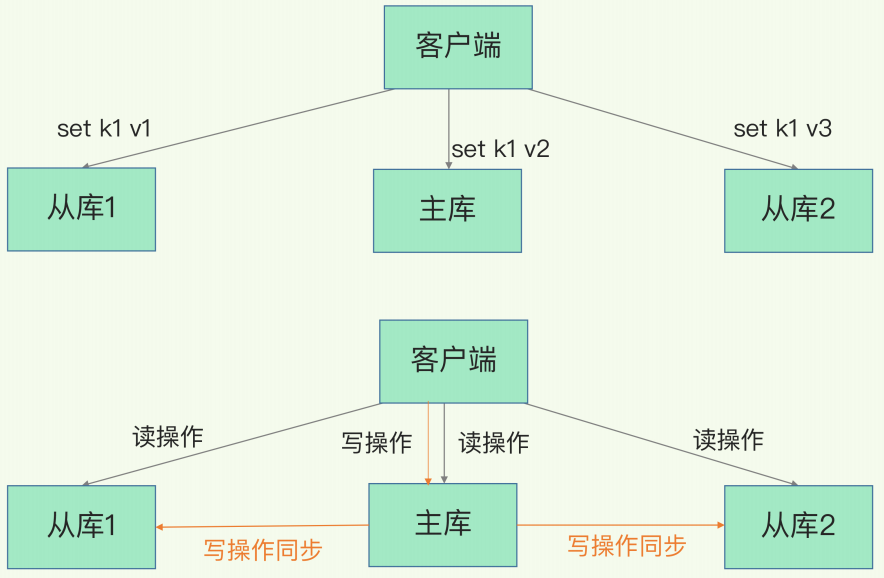
为什么要采用读写分离的方式?
可以避免主从库之间进行数据协调,只需要让主库同步从库即可(如果都可以进行写操作,那么会很混乱)
第一次同步
从库如何成为主库的从库?
一行代码即可:
1 | 现在有实例 1(ip:172.16.19.3)和实例 2(ip:172.16.19.5) |
第一次同步有三个阶段:

从库发起连接请求(
psync a b包含两个参数,a为主库的runId,由于不知道主库runID,所以为?;b为复制进度,第一次复制为-1);主库收到后,会使用FULLRESYNC命令,表示这是一次全量复制主库将所有数据同步(即一个RDB块)给从库。从库收到数据后,清除原本的数据,并在本地完成数据加载
(主库发送RDB后会在内存中用专门的
replication buffer,记录 收到新的写操作)主库会把第二阶段执行过程中新收到的写命令,再发送给从库
主从级联模式
如果主库频繁的从库创建RDB、发送RDB
这会影响主库的性能(因为fork会阻塞主线程,而且越大,fork所需要的时间会越长)
所以为了解决这个问题,有了主 - 从 - 从模式
即部署主从集群的时候,可以手动选择一个从库(比如选择内存资源配置 较高的从库),用于级联其他的从库
这个从库就可以帮主库分担压力

网络闪断与repl_backlog_buffer缓存
网络闪断:即网络不好,短短续续
如果在Redis2.8版本之前,出现了网络闪断,在重新连接后,会重新进行一次全量复制,开销极大
Redis2.8版本之后,网络断了之后,主从库会采用增量复制的方式继续同步
当主从库断连后,主库会把断连期间收到的写操作命令,写入replication buffer,同时也会把这些操作命令也写入 repl_backlog_buffer这个缓冲区
repl_backlog_buffer是一个环形缓冲区,随着主库不断接收新的写操作,它在缓冲区中的写位置会逐步偏离起始位置
这个缓存有两个指针:如图,分别为主库读的指针、从库读的指针
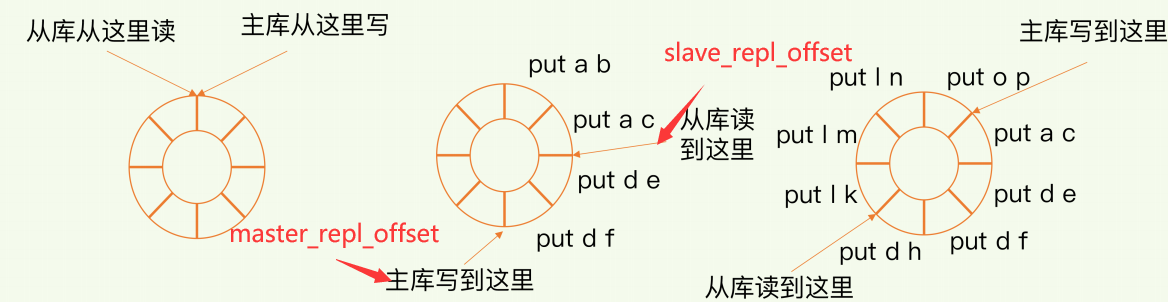
连接恢复之后,从库首先会给主库发送 psync 命令,并把自己当前的 slave_repl_offset 发给主库
主库会判断自己的 master_repl_offset 和 slave_repl_offset 之间的差距,只用把master_repl_offset和 slave_repl_offset 之间的命令操作同步给从库就行
哨兵机制
主库提供了所有的写服务,如果主库挂掉,那么整个系统将陷入瘫痪
Redis使用哨兵机制,来解决这个问题
Redis哨兵机制:在主库挂掉后,将从从库中选出一个作为新的主库
哨兵
哨兵:即运行在特殊模式下的Redis进程
哨兵有三个任务:
- 监控:周期性的给主库发送PING,检测主库是否在运行
- 选择主库:从众多的从库中筛选一个作为主库
- 通知:把新主库的连接信息发送给从库
其实这三个功能都是围绕着一个流程来进行的
监控——主观下线与客观下线
哨兵如何判断一个主库已经挂掉了呢?
哨兵会周期性给主库、从库发送PING请求,如果主从库没有在规定时间内回应:
- 从库没有回应:标记为主观下线
- 主库没有回应:有可能主库真的下线了(此时会进行主从切换),也有可能是哨兵误判了
所以需要有很多哨兵来进行对主库是否下线的判断,这就称为哨兵集群
所以,当多数的哨兵都认为主库已经下线,那么此时主库就会被认定为客观下线
客观下线的标准就是:当有 N 个哨兵实例时,最好要有 N/2 + 1 个实例判断主库为“主观下线”,才能最终判定主库为“客观下线”
监控的具体流程:
- 当一个哨兵判断主库主观下线后,就会给其他哨兵发送
is-master-down-by-addr - 其他的哨兵会根据自己的判断,投出Y/N(即赞成票和不赞成票)
- 当赞成票大于
quorum参数时,就会认为主库客观下线

主库挂掉,哪一个哨兵来执行主从切换的任务呢?
是由Leader来执行,leader也是由投票选举产生的:
在投票过程中,任何一个想成为 Leader 的哨兵,要满足两个条件:
- 拿到半数以上的赞成票
- 拿到的票数同时还需要大于等于哨兵配置文件中的
quorum值
哨兵是如何确定Leader投票是投是还是否呢?
它会给第一个向它发送投票请求的哨兵回复 Y,给后续再发送投票请求的哨兵回复 N
选主——选择新主库
哨兵如何选择主库?
整个过程分为两步:筛选 + 打分
简单来说,我们在多个从库中,先按照一定的筛选条件,把不符合条件的从库去掉。然后,我们再按照一定的规则, 给剩下的从库逐个打分,将得分最高的从库选为新主库
(从库都在卷~)
筛选条件:除了要检查从库的当前在线状态,还要判断它之前的网络连接状态(通过配置一个最大连接时长,默认如果发生断连的次数超过10次,就认为这个从库的网络状况不好,就被miss掉了)
打分规则:别按照三个规则依次进行三轮打分,这三个规则分别是从库优先级、从库复制进度以及从库 ID 号
三轮打分过程:
- 优先级最高的从库得分高(不同的从库可以设置不同的优先级,一般给内存大的从库设定一个高的优先级)
- 和旧主库同步程度最近的从库得分高(通过
repl_backlog_buff缓存中的指针,详情见上一节) - ID号小的从库得分高:默认的规定,在优先级和复制进度都相同的情况下,ID 号最小的从库得分最高,会被选为新主库
通知——发布/订阅机制
哨兵之间是如何进行交流的?
要弄清楚这个问题,首先得知道如何设置一个哨兵:
1 | sentinel monitor <master-name> <ip> <redis-port> <quorum> |
此时哨兵之间是不知道彼此的
哨兵实例之间可以相互发现,要归功于 Redis 提供的 pub/sub 机制,也就是发布 / 订阅 机制
发布订阅机制:订阅了同一个频道的应用,可以通过发布的消息进行信息交换
频道有很多:
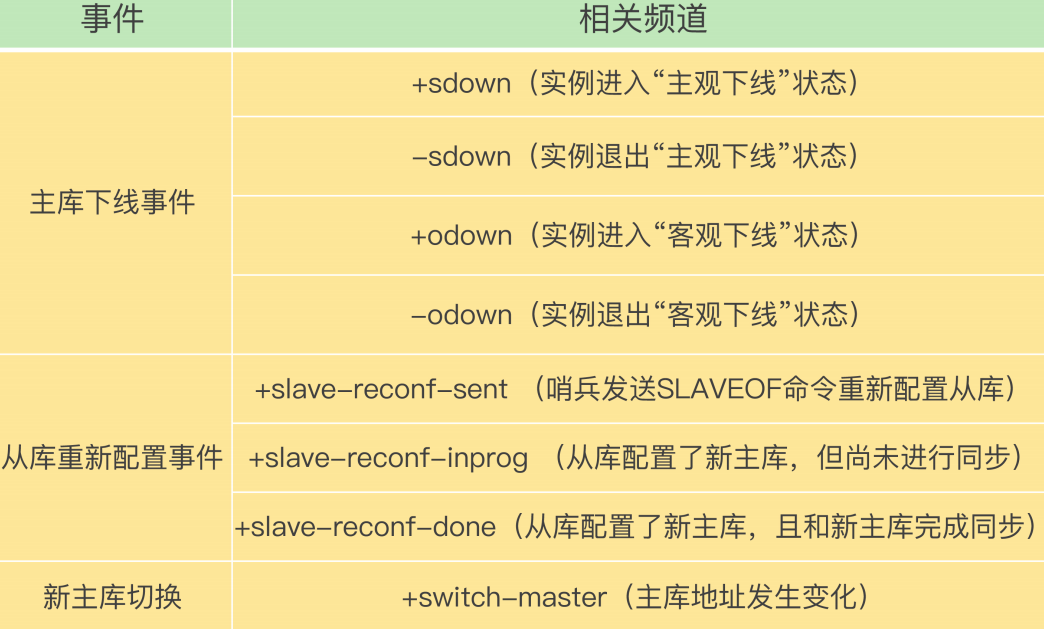
哨兵只要和主库建立起了连接,就可以在主库上发布消息了,比如说发布它自己的连接信息(IP 和端口)
同时,它也可以从主库上订阅消息,获得其他哨兵发布的连接信息。当多个哨兵实例都在主库上做了发布和订阅操作后,它们之间就能知道彼此的 IP 地址和端口。
举个例子,具体说明一下。
在下图中,哨兵 1 把自己的 IP(172.16.19.3)和端口 (26579)发布到“__sentinel__:hello”频道上,哨兵 2 和 3 订阅了该频道。那么此时,哨兵 2 和 3 就可以从这个频道直接获取哨兵 1 的 IP 地址和端口号。

哨兵是如何知道从库的IP的?
哨兵向主库发送 INFO 命令,主库接受到这个命令后,就会把从库列表返回给哨兵
Redis缓存
缓存处理请求的两种情况
缓存接收请求后,无非两种情况:
- 缓存命中:缓存中有数据,可以直接读
- 缓存缺失:缓存中没有数据,必须要去数据库中读取;而且读取完成后,还必须把这个数据再加载到缓存中
注意:缓存缺失后,除了要访问数据库,还要把新的数据写到缓存内(缓存更新)
Redis的缓存类型
Redis中缓存由两种类型,我们可以根据业务的不同来选择不同的缓存:
- 只读缓存:只读缓存只接受读请求,对于写请求直接交给数据库处理
- 读写缓存:读写请求接收读、写请求
只读缓存对于不同的请求:
- 写请求:只读缓存会删除当前缓存
- 读请求:如果读不到,会发生缓存缺失,在读完数据库后进行缓存更新

读写缓存对于不同的请求的处理:
- 读请求:与只读缓存一样
- 写请求:直接在缓存中进行更改
在读写缓存中,由于写请求在缓存中就进行了处理,所以必须要写回磁盘,这时就有两种不同的写回磁盘的策略:
- 同步直写:服务器向缓存和数据库同时发起请求,缓存处理完成后,需要等待数据库也处理完成后,才会返回响应
- 异步写回:缓存处理完数据后直接返回,而且数据只有在被淘汰出缓存时才会写回磁盘

| 对比 | 同步直写 | 异步写回 |
|---|---|---|
| 优点 | 即使缓存发生故障,数据也不会丢失 | 访问快速 |
| 缺点 | 等待数据库,降低了缓存的访问性能 | 缓存发生故障会导致数据直接丢失 |
Redis的缓存淘汰机制
Redis有两种淘汰策略:
- 惰性删除:redis不主动删除过期键,而是处理每一个请求时,判断是否过期,如果过期就删除。
- 定期删除:每隔一段时间(默认100ms)随机抽查一部分键,根据不同的策略淘汰键。
Redis4.0定期删除有 8 种淘汰策略:
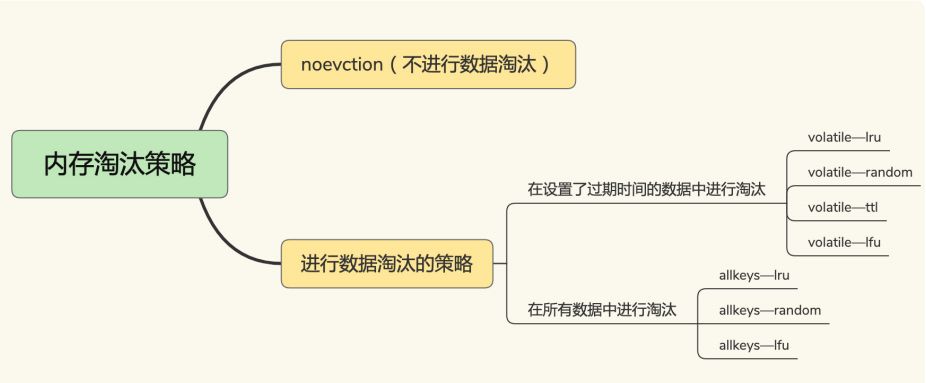
noeviction:不会淘汰数据,如果缓存满了,将不再提供服务(默认策略)volatile开头的淘汰策略:代表淘汰的选择源是所有有时间限制的数据,不会淘汰那些无时间限制的数据(即只淘汰那些设置EXPIRE的数据)allkeys开头的淘汰策略:淘汰的选择源是所有数据LRU:基于LRU算法进行淘汰LFU:基于LFU算法进行淘汰random:随机进行淘汰volatile-ttl:淘汰最早的请求(通过TTL判断)
如何选择?
优先使用
allkeys-lru策略:可以充分利用 LRU 这一经典缓存算法的优势,把最 近最常访问的数据留在缓存中如果你的业务中有类似置顶的需求(比如置顶新闻、置顶视频):可以使用
volatile-lru策略,同时不给这些置顶数据设置过期时间。这样一来,这些需要置顶的数据一直不会被删除,而其他数据会在过期时根据 LRU 规则进行筛选
淘汰的数据如何处理?
一般来讲,对于干净页直接删除,但是对于脏页要写回数据库后再删除。
但是在Redis中,不管干不干净,只要认定淘汰,就会直接删除
Redis中的LRU算法
由于LRU需要借助链表,而且涉及到了链表的很多断开、连接的操作
所以如果缓存中的数据很多,那么直接使用LRU算法,显然会造成很大负担
LRU算法就不介绍了,在Redis中的特殊处理,要说一下
首先要知道Redis在RedisObejct中,保存了lru字段记录最近一次的访问时间戳
第一次LRU淘汰:随机选出N个数据,把他们作为一个候选集合,接下来,Redis会比较这N个数据的lru字段,将数值最小的(也就是好久没有访问的)淘汰
之后的每一次淘汰:挑选一些数据进入候选集合,挑选的标准是该数据的lru字段的值比候选集合里最小的lru还要小,然后淘汰lru字段最小的数据
经过这样的特殊处理,Redis就既实现了LRU,也提高了缓存的性能
缓存一致性问题
由于Redis有两种缓存,所以缓存不一致问题,我们分开来讨论:
对于读写缓存
只能采用同步直写的方式避免,涉及到Redis的事务
对于只读缓存
- 新增数据时:数据在写入数据库后,加载到内存,不存在不一致问题
- 删改数据时:只读缓存只接受读请求,所以如果你改了数据库中的数据,假设此时还没来得及删掉缓存中的数据,那么此时有请求来读,读到的将是旧的数据(存在不一致问题)
解决措施:删除缓存中的数据,并且将数据库中的数据修改
但是!这个解决措施并不一定能完全成功:(我们还需要保障措施保证这两步能完成!)
下面我们看删改数据时都会有哪些情况,可以导致数据不一致的发生
情况一:删改数据后,由于删缓存数据的操作失败而导致的缓存不一致
情况二:删改数据后,由于多线程,还没来得及删缓存数据,而导致的缓存不一致
如何解决?
对于情况一:采用重试机制
对于情况二:采用延迟双删
重试机制
可以把要删除的缓存值或者是要更新的数据库值暂存到消息队列中(例如使用 Kafka 消息队列)
当删除缓存数据操作失败后,可以从消息队列中重新读取这些值,然后再次进行删除或更新

延迟双删
在线程 A 更新完数据库值以后,我们可以让它先 sleep 一小段时间,再进行一次缓存删除操作
(线程 A sleep 的时间,就需要大于线程 B 读取数据再写入缓存的时间)
之所以要加上 sleep 的这段时间,就是为了让线程 B 能够先从数据库读取数据,再把缺失的数据写入缓存,然后,线程 A 再进行删除
1 | 伪代码 |
使用延迟双删+消息队列方式解决缓存一致性会有什么弊端吗?
- 对业务代码的侵入比较大
- 延迟时间不好控制,时间短可能导致双删没有作用;时间太长可能会降低系统并发度
因此可以使用异步缓存更新机制:使用canal订阅binlog日志文件,在有数据更新后触发缓存更新重试机制。

缓存雪崩
缓存雪崩:指大量的应用请求无法在 Redis 缓存中进行处理,应用将大量请求发送到数据库层,导致数据库层的压力激增
导致缓存雪崩的原因:
- 缓存中有大量的数据同时过期
- Redis缓存发生故障宕机
解决措施:
对于情况1,有两种解决办法:
- 避免给大量的数据设置相同的过期时间(可以给EXPIRE设置时间时加一个1-3分钟的随机值)
- 服务降级
服务降级:
对于非核心数据,暂停缓存服务,让其直接返回预定义的信息或者空值
对于核心数据,继续提供服务
对于情况2,也有两种解决办法:
- 服务熔断或请求限流机制
- 使用主从Redis集群,切换主库(比较好的办法)
服务熔断:
为了防止引发连锁的数据库雪崩,甚至是整个系统的崩溃,我们暂停业务应用对缓存系统的接口访问
服务熔断会终止所有的缓存服务,这当然是不好的
请求限流机制:
在业务系统的请求入口前端控制每秒进入系统的请求数,避免过多的请 求被发送到数据库
比如请求入口前端允许每秒进入系统的请求是 1 万个,其中,9000 个请求都能在缓存系统中进行处理,只有 1000 个请求会被应用发送到数据库进行处理
缓存击穿
缓存击穿:针对某个访问非常频繁的热点数据的请求,无法在缓存中进行处理,导致访问该数据的大量请求,一下子都发送到了后端数据库
解决办法:
热点数据不要设置过期时间,让其能对热点数据持续提供服务
缓存穿透
缓存穿透:要访问的数据既不在 Redis 缓存中,也不在数据库中,导致请求在访问缓存时,发生缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据
发生缓存穿透的原因:
- 业务层误操作:业务层不慎删除了缓存的数据和数据库的数据
- 恶意攻击:专门访问数据库没有的数据
解决措施:
- 缓存空值或缺省值
- 使用布隆过滤器快速判断是否存在,减轻数据库压力
- 在前端的请求入口进行检测,把恶意的请求直接过滤掉
布隆过滤器
布隆过滤器:
是由初值都为0的bit数组与N个哈希函数组合,可以快速判断数据是否存在
如果一个数据被写入数据库,那么需要在布隆过滤器上标记它的存在:
使用N个哈希函数分别计算这个数据的哈希值,得到N个哈希值
将哈希值对bit数组的长度取模,得到每个哈希值在数组中的对应位置
将对应的bit位置为1
如果想要查一个数据是否存在:
- 同样使用N个哈希函数计算其哈希值
- 去对应位置查看bit数组对应位是否为1
- 只要有一个不为1,那么这个数据就不存在
缓存异常总结

缓存污染
缓存污染:指缓存中存放了很多访问次数很少,甚至只会被访问一次的数据,白白占用缓存的空间
如何解决缓存污染?
LRU可以解决缓存污染问题吗?
LRU的确可以有效的留存最近访问的数据,但是在出现扫描式单次查询操作时,LRU策略显得无能为力
扫描式单词查询:应用对大量的数据进行一次全体读取,每个数据都会被读取,而且只会被读取一次。此时,因为这些被查询的数据刚刚被访 问过,所以 lru 字段值都很大
Redis中的LFU算法
LFU(least frequently used)可以看做LRU算法的一种优化,它会从两个值来判断将什么数据淘汰:
- 数据访问的时效性(即访问时间到当前时间的长度)
- 数据被访问的次数
LFU判断依据:
LFU算法会先根据数据被访问的次数进行筛选,如果访问次数相同,那么才会去比较访问的时效性,将访问更久的数据淘汰。
这两个数据也存放在RedisObejct中,RedisObejct中的lru字段占用了3B(24b),将这个字段分开:
- ldt值:lru字段的前16bit,表示数据的访问时间戳
- counter值:lru字段的后8bit,表示数据的访问次数
注意:
counter的值并不是每访问一次就增加1
它的加1过程很复杂:
counter计数规则是:
每当数据被访问一次时,首先,用计数器当前的值乘以配置项
lfu_log_factor再加 1,再取其倒数,得到一个p值; 把这个 p 值和一个取值范围在(0,1)间的随机数
r值比大小,只有p值大于r值时,计数器才加 1
我们不需要记住这个计数规则,官方给我们一个lfu_log_factor值取不同数据时,counter值的变化情况:

可见,一般的项目,我们可以设置为10,就可以保证在1M点击的情况下也能保证区分度
除此外,Redis还规定了counter的衰减机制:
LFU 策略使用衰减因子配置项
lfu_decay_time来控制访问次数的衰减。LFU 策略会计算当前时间和数据最近一次访问时间的差值,并把这个差值换算成以分钟为单位。
然后,LFU 策略再把这个差值除以
lfu_decay_time值,所得的结果就是数据 counter 要衰减的值。
热key问题
热key指在缓存系统中,某些缓存key访问过于频繁,导致对于这些key需要额外进行性能处理的情况。
一般处理热key问题的解决手段有三种:
- 缓存预热:在系统启动或者业务低峰,主动缓存热门数据
- 一致性hash:使用哈希环,将键散列在整个环上,可以使请求更均匀的分布在各个redis节点。
- 数据分片:按照业务某个键分片,拆分缓存在不同的缓存节点上,减轻单个节点的压力。
但是在实际应用中,热key可能是可预知的,也可能不可预知:
- 可预知的热key:比如秒杀活动。在发布商品时就需要进行分布式缓存、本地缓存预热
- 不可预知的热key:比如某个商品突然称为爆款。接入热点探测系统(定期上报key的查询次数,热点系统检测是否为热key),如果是热key立即建立本地缓存与缓存
除此外,对于热key问题,即使有缓存手段也要做好兜底工作,做好限流熔断兜底。
热key如何发现?
1、在LFU算法下,可以使用--hotkeys
1 | redis-cli -p 6379 --hotkeys |
该参数能够返回所有 key 的被访问次数
2、MONITOR命令
实时查看 Redis 的所有操作的方式,可以用于临时监控 Redis 实例的操作情况,包括读写、删除等操作。
对 Redis 性能的影响比较大,因此禁止长时间开启 MONITOR(生产环境中建议谨慎使用该命令)。
3、业务代码是否有日志?
大key问题
怎么算是一个大key?
- 如果是String类型:value超过1MB
- 复合类型(List、Hash、Sort、Sorted Sort):value元素超过5000个
大key带来的副作用:
- 占用内存大
- 处理大key的网络IO消耗大:比如一个key是1mb,qps是1000,那么每秒就有1GB的流量处理,一般的千兆宽带是扛不住这个压力的
- del困难:删除大key时,阻塞的时间会比较长
如何发现大key?
1、加--bigkeys参数:
1 | redis-cli -p 6379 --bigkeys -i 3 |
这种方式会扫描所有的key,且只能找出每种数据结构 top 1 bigkey(占用内存最大的 String 数据类型,包含元素最多的复合数据类型)
实际上这种方式会调用scan命令进行执行
2、使用scan命令
SCAN 命令在遍历大量数据时不会阻塞服务器,但是返回的数据可能不是实时的。
1 | SCAN 0 MATCH user:* COUNT 100 |
3、借助开源工具,分析RDB文件(前提使用了RDB的方式)
4、借助平台的分析服务(阿里云Redis有bigkey实时分析)
如何处理大key?
手动清理:
- Redis 4.0+可以使用
UNLINK命令来异步删除一个或多个指定的 key - Redis 4.0 以下可以考虑使用
SCAN命令结合DEL命令来分批次删除。
- Redis 4.0+可以使用
分割:将一个bigkey分为多个小key,比如一个hash通过二次hash,拆分为多个hash
采用合适的数据结构:例如,文件二进制数据不使用 String 保存、使用 HyperLogLog 统计页面 UV、Bitmap 保存状态信息(0/1)
开启lazy-free: Redis 4.0 开始引入的,指的是让 Redis 采用异步方式延迟释放 key 使用的内存,将该操作交给单独的子线程处理
Redis分布式锁
查看此篇:redis分布式锁
相关链接
- 博客园
- b站狂神说
- Redis设计与实现
- csdn图解epoll
- 极客时间蒋德钧老师的redis课