JAVA-集合与Map
集合
Java中实现了部分的数据结构(Data Structure)的内容,并把他们封装成了类
集合是什么
集合是一种可以存储多个数据的容器(此集合非彼集合)
优点:
- 集合的长度可以随意变化
- 集合存储的都是对象,而且对象的类型可以不同
将集合接口与实现分离
例如:队列
队列:先进先出(FIFO),头的一端可以删除元素,尾的一端可以添加元素,并且可以查找队列中元素的个数
队列Queue接口可能是这么实现的
1 | public interface Queue<E>{ |
队列有两种实现:
- 循环数组
1
2
3
4
5
6
7
8
9
10public class CircularArrayQueue<E> implements Queue<E>{
private int head;
private int tail;
CircularArrayQueue(int capcity){...}
public void add(E e){...}
public E remove(){...}
public int size(){...}
private E[] elements;
}
//这里只是做个示例 - 链表
1
2
3
4
5
6
7
8
9public class LinkedListQueue<E> implements Queue<E> {
private Link head;
private Link tail;
LinkedListQueue(){...}
public void add(E element){...}
public E remove(){...}
public int size(){...}
}
//这里只是做个示例
当在程序中使用队列时,一旦构建了集合就不需要知道究竟使用了哪种实现,所以,只有在构建集合对象的时候,使用具体的类才有意义
,例如:
1 | Queue<MyClass> myClass = new CircularArrayQueue<>(100); |
集合关系图
在Java中,集合类的基本接口是Collection接口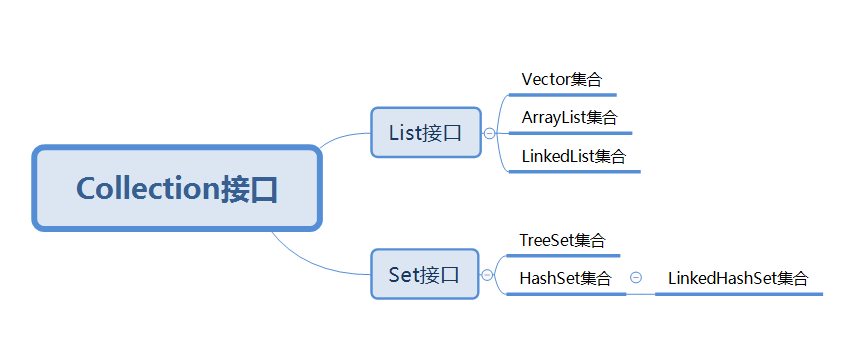
Collection接口
定义了所有单列集合中共性方法,
所有单列集合都可以使用的方法,没有带索引的方法- List接口
- 有序的集合(存储和取出元素的顺序相同)
- 允许存储重复的元素
- 有索引,可以使用普通的for循环遍历
- Set接口
- 不允许存储重复元素
- 没有索引,不能使用普通的for循环遍历
- 无序
- LinkedHashSet 例外,是有序的集合
- List接口
学习集合的方法:
- 学习顶层:学习顶层接口/抽象类的共性方法,所有的子类都可以使用
- 使用底层:顶层无法创建对象使用,需要使用底层来创建对象
Collection接口
1 | public interface Collection<E>{ |
iterator()实现了Iterator接口,首先了解一下迭代器
迭代器
Iterator迭代器接口有四个方法:
1. next():逐个访问集合中的每个元素,但是如果到带了集合的末尾会抛出一个NoSuchElementException异常
Java的迭代器可以看做是位于两个元素之间的,当调用next()的方法时,迭代器就越过下一个元素,并返回刚刚越过的元素的引用
2. hasNext():判断是否还有下一个元素
3. remove():删除一个刚刚越过的元素
4. forEachRemaining:流式编程
1 | public interface Iterator<E>{ |
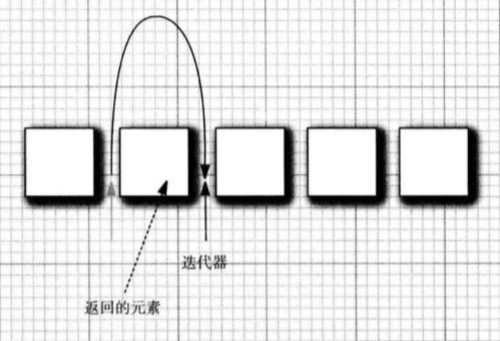
迭代器的使用
迭代器的使用
1 | Collection<String> coll = ...; |
for each也可以简单的表示同样的循环操作
1 | for(String e : c){ |
JavaSE8后,可以调用Iterator最后一个方法foreachRemaining方法,这个方法会提供一个Lambda表达式
1 | iter.forEachRemaining(element -> doSomething) |
Collection的常用方法
常用方法
1 | int size() |
代码示例
1 | Collection<String> coll = new ArrayList<>();//接口的构造 |
Iterator
迭代器: 一种通用的取出集合元素的方法
Iterator是一个接口,我们无法直接使用
需要使用实现类对象,获取它的实现类比较特殊
迭代: 在取元素之前判断集合中有没有该元素,如果有就取出这个元素,继续判断,直到取出集合中所有需要的元素
实现类
获取实现类的方法
Collection接口有一个iterator()方法,此方法直接返回实现类对象
常用方法
1 | boolean hasNext() |
常用方法
1 | Collection<String> coll = new ArrayList<>(); |
foreach
JDK1.5之后的一个高级for循环,专门用来遍历数组和集合的,它的内部其实是个iterator迭代器
所以在遍历的过程中,不能对集合中的元素进行增删操作
所有的单列集合都可以使用增强for
1 | for(元素的数据类型 变量 : Collection集合/数组){ |
1 | Collection<String> coll = new ArrayList<>(); |
泛型
泛型是一种未知的数据类型,当我们不知道使用声明数据类型的时候,我们可以使用泛型
可以看成一个变量,可以用来接收数据类型
ArrayList集合在定义的时候,不知道集合中都会存储声明元素的数据,所以类型使用泛型
1 | public class ArrayList<E>{ |
泛型数据类型的确定时间在创建对象的那一刻
优缺点
优点
- 避免了类型转换的麻烦,存储的是什么类型,取出的就是什么类型
- 把运行期异常(代码运行之后会抛出的异常),提升到了编译器(写代码的时候会报错)
弊端
泛型是什么类型只能存储声明类型
如果不加泛型,默认Object类,可以存储任何对象,但不安全,但容易引发异常
(例如:当存入Integer对象和String对象,遍历时想调用toString方法,而这样就必须向下转型,在运行中也可能会报错)
泛型类
泛型类
1 | public class father<E> { |
调用
1 | father f = new father(); |
泛型方法
1 | public <E> void method (E e){ |
泛型接口
1 | public interface api<E> { |
接口实现类
1 | public class apiImpl <E> implements api<E>{ |
高级用法
泛型通配符?
不知道使用什么类型时可以使用
但是此时只能接受数据,而不能存储数据
1 | public static void print(ArrayList<?> list){ |
高级用法:
泛型的上限限定:
? extends E代表使用的泛型只能是E类型的子类/本身泛型的下限限定:
? super E代表使用的泛型只能是E类型的父类/本身
数据结构简述
栈(stack)
先进后出
只有一个口,最先进去的,最后才能出去
类似于手枪弹夹
队列(quene)
先进先出
有一个入口一个出口,先进去的先出去
数组(array)
查询快,增删慢
查询快:
数组的地址是连续的,我们通过数组的首地址可以找到数组,通过数组的索引值可以快速的找到某一个元素
增删慢:
数组的长度是固定的,我们增删一个元素,必须创建一个新的数组,把原数组的数据复制过来,而原数组会被垃圾回收
链表(linked list)
查询慢,增删快
查询慢: 链表的地址不是连续的,每次查询元素必须从头开始
增删快:链表结构增删一个元素,对整体没有影响
链表的每一个元素称之为一个节点,
一个节点包括三个部分(自己的地址+数据+下一个节点的地址)
两种列表
单向列表
链表中只有一条链子,不能保证元素的顺序(存储元素和去除元素的顺序有可能不一致)
双向列表
链表中有两条链子,一条专门记录元素的顺序,一条是一个有序的集合
红黑树
特点:趋于平衡的树,查询的速度非常快
约束:
节点可以是红色也可以是黑色
根节点是黑色
叶子结点(空节点)是黑色
每个红色的节点的子节点都是黑色的
任何一个节点到其每一个叶子结点的路径上黑色节点相同
List集合
特点
- 有序:存储与取出的顺序是一致的
- 有索引:包含常用的索引方法
- 允许重复
常用方法
1 | public void add(int index,E element) |
示例
1 | List<String>list = new ArrayList<>(); |
遍历方法
1 | //普通for循环 |
常见报错
1 | IndexOutofBoundsException//索引越界异常,集合会报 |
ArrayList
List 接口的大小可变数组的实现。
实现了所有可选列表操作,并允许包括 null在内的所有元素。
除了实现 List接口外,此类还提供一些方法来操作内部用来存储列表的数组的大小
尖括号内的E叫做泛型,装在该集合当中的所有元素都必须是统一的类型
泛型只能是引用类型,不能是基本类型
包路径:
1 | java.util |
构造方法:
1 | public ArrayList(Collection<? extends E> c) |
常用方法
1 | public E set(int index,E element); //输入索引值和相同的泛型内容替换原有的内容 |
示例代码:
1 | ArrayList<String> list = new ArrayList<>(); |
泛型只能导入引用类型,那怎么存入基本类型呢?
使用基本类型的对应的包装类
从JDK1.5开始,支持自动装箱拆箱
1 | ArrayList<Integer> list1 = new ArrayList<>(); |
LinkedList
底层是一个双向列表,
查询慢,增删快,多线程
也有list的三个特点(有序,可索引,可重复)
包路径
1 | java.util |
常用方法
添加方法
1 | public void addFirst(E e) |
获取方法
1 | public E getFirst() |
移除方法
1 | public E removeFirst() |
示例代码
1 | LinkedList<String> linked = new LinkedList<>(); |
Vector
是一个同步的集合(单线程,速度慢)
了解即可,最早期的一个集合
HashSet
特点:
- 继承set接口
- 没有重复元素
- 没有索引,也不能使用普通的for循环
- HashSet特点
- 不同步(多线程)
- 无序的集合
- 没有索引
- 底层是一个哈希表结构(查询速度非常快)
包路径
1 | java.util |
构造函数
1 | public HashSet() |
1 | Set<Integer> set = new HashSet<>();//构造一个HashSet集合 |
存储自定义类型的元素
对于自定义元素
1 | Set<father> set = new HashSet<>();//构造一个HashSet集合 |
我们必须重写hashCode和equals方法,来保证不重复
1 |
|
再次运行,发现重复的人就被去掉了
哈希值
哈希值是一个十进制的整数,由系统随机给出
就是对象的地址值,是一个逻辑地址,是模拟出来的地址,不是数据实际存储的物理地址
在Obejct类中有一个方法可以返回对象的哈希值
1 | father f1 = new father(); |
1 | String s1 = "重地"; |
哈希表
HashSet集合存储数据的结构(哈希表)
把元素进行了分组,相同哈希值的元素分为一组,每一组都是一个链表,这些元素的哈希值相同
如果链表超过了8位,那么就会把链表转化为红黑树,提高查询速度
jdk1.8之前:哈希表 = 数组+链表
jdk1.8之后:
哈希表 = 数组 +链表
哈希表 = 数组 + 红黑树(提高查询的速度)
哈希表的特点:速度快
set不重复原理
add方法会计算字符串的哈希值,得到哈希值会去寻找是否存在此哈希值。
如果没有就会存储到集合当中
如果有(哈希冲突)就会调用equals方法对这两个相同的字符进行比较,比较如果不同才会存储这个元素,挂在同一个位置
LinkedHashSet
继承了HashSet集合,底层是一个哈希表(数组+链表/红黑树)+链表
多了一条链表(记录元素的顺序),可以保证元素有序
包路径
1 | java.util |
HashSet无序,LinkedHashSet有序
可变参数
JDK1.5之后,如果我们需要接受多个参数,并且多个参数的类型一致,我们就可以简化成如下的格式:
1 | public static void sum(int... a){//这样接收 |
1 | //调用 |
注意事项:
一个方法的参数列表,只能有一个 可变参数
如果方法的参数有多个,那么可变参数必须写在最右边
小实例:计算任意项的和
1 | public static void main(String[] args) throws ParseException { |
Collections
此类完全由在 collection 上进行操作或返回 collection 的静态方法组成。
它包含在 collection 上操作的多态算法,即“包装器”,包装器返回由指定 collection 支持的新 collection,以及少数其他内容。
常用方法
1 | Collections.addAll()//参数第一个是一个集合,后面是任意个元素 |
示例代码
1 | ArrayList<String> list = new ArrayList<>(); |
自定义元素sort,需要在自定义类中重写compareTo方法
引入Comparable<>接口
1 | public class father implements Comparable<father>{ |
1 | father f1 = new father("一号",10); |
Comparable<>接口的排序规则:
this - 参数 -> 升序
参数 - this -> 降序
Map
Map<K,V>
- K键:此映射所维护的键的类型
- V键:映射值的类型
Map是一个双列集合,与Collection不同
将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。
特点:
- Map集合是一个双列集合,包含一个键一个值
- 键和值的数据类型不相关
- key不可以重复,但是value可以重复
- key和value一一对应
包路径
1 | java.util |
实现类
- HashMap(底层是一个哈希表)
- 查询速度快
- 底层是哈希表
- 无序集合
- LinkedHashMap
- 底层是一个哈希表+链表
- 有序集合
常用方法
1 | V put(K key, V value) |
示例代码
1 | Map<String,String> map = new HashMap<>(); |
Map遍历
- 法一:利用keySet方法
1 | Map<String,String> map = new HashMap<>(); |
- 法二:使用entrySet方法
1 | Map<String,String> map = new HashMap<>(); |
存储自定义类型,记得要重写hashCode方法,去重
Map.Entry
Map接口中有一个内部接口Entry
作用:当Map集合一旦创建,那么就会在Map集合中创建一个Entry对象,用来记录键与值的关系
他有两个方法:
- getKey
- getValue
用来获取V和K
JDK9优化
jdk9中,list,set,map都存入了一个静态of方法,
只适用于这三个接口,不适用于这三个接口的实现类
- 可以用来 一次性 添加 多个元素
- of方法的返回值是一个不能改变的集合,该集合不能再用add,put存入元素
- Set和Map接口在调用of方法时不能有重复的元素
所以要在数量确定的时候再用
1 | List<String> list = List.of("a","b","c"); |